Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 6年前 (2018-05-09) 10788℃ 0评论22喜欢
在Hive0.8开始支持Insert into语句,它的作用是在一个表格里面追加数据。标准语法语法如下:[code lang="sql"]用法一:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;用法二:INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;[/code w397090770 11年前 (2013-10-30) 102118℃ 2评论69喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 w397090770 8年前 (2016-08-10) 36792℃ 2评论73喜欢
Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。更多特点请参见 一篇文章了解 Apache Cassandra 是什么。由于 Cassandra 数据库的众多优点,在国内外多达 1500+ 家公 w397090770 5年前 (2019-05-08) 1761℃ 0评论5喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 zz~~ 8年前 (2016-12-16) 17234℃ 0评论43喜欢
本文来自 恩爸 的文章,原文地址:https://blog.csdn.net/zzcclp/article/details/80161130前言一个偶然的机会,从某Spark微信群知道了CarbonData,从断断续续地去了解,到测试 1.2 版本,再到实际应用 1.3 版本的流式入库,也一年有余,在这期间,得到了 CarbonData 社区的陈亮,李昆,蔡强等大牛的鼎力支持,自己也从认识CarbonData 到应用 Carbo w397090770 6年前 (2018-05-02) 2747℃ 0评论7喜欢
MongoDB 4.2 稳定版于近日正式发布了,此版本带来了许多最大的特性,比如分布式事务(Distributed Transactions)、客户端字段级别加密(Client-Side Field-Level Encryption)、按需物化视图(On-Demand Materialized Views)以及通配符索引(Wildcard Indexes)。下面我们来简单介绍一下各个新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 5年前 (2019-08-18) 1978℃ 0评论3喜欢
IntelliJ IDEA 2020.2 稳定版已发布,此版本带来了不少新功能,包括支持在 IDE 中审查和合并 GitHub PR、新增加的 Inspections 小组件(Inspections Widget)支持在文件的警告和错误之间快速导航、使用 Problems 工具窗口查看当前文件中的完整问题列表,并在更改会破坏其他文件时收到通知。此外还有针对部分框架和技术的新功能,包括支持使 w397090770 4年前 (2020-07-29) 373℃ 0评论2喜欢
本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。背景相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 4年前 (2020-07-05) 2065℃ 0评论4喜欢
大家在查看分析网站访问日志的时候,很可能发现自己网站里面的很多图片被外部网站引用,这样给我们自己的博客带来了最少两点的不好: (1)、如果别的网站引用我们网站图片的次数非常多的话,会给咱们网站服务器带来很大的负载压力; (2)、被其他网站引用图片会消耗我们网站的流量,如果我们的网站服 w397090770 10年前 (2014-12-27) 5456℃ 0评论3喜欢
c++中关于const的用法有很多,const既可以修饰变量,也可以函数,不同的环境下,是有不同的含义。今天来讲讲const加在函数前和函数后面的区别。比如:[code lang="CPP"]#include<iostream>using namespace std;// Ahthor: 过往记忆// E-mail: wyphao.2007@163.com// Blog: // 转载请注明出处class TestClass {public: size_t length() const; const char* ge w397090770 12年前 (2013-04-05) 25008℃ 1评论55喜欢
我们在《Kafka创建Topic时如何将分区放置到不同的Broker中》文章中已经学习到创建 Topic 的时候分区是如何分配到各个 Broker 中的。今天我们来介绍分区分配到 Broker 中之后,会再哪个目录下创建文件夹。我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录 w397090770 7年前 (2017-08-09) 5068℃ 0评论15喜欢
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主题覆盖度、性能、易用性、可扩展性及数 w397090770 5年前 (2020-03-01) 2000℃ 0评论7喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 w397090770 7年前 (2017-12-05) 2994℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3568℃ 0评论21喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4463℃ 6评论6喜欢
背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 6年前 (2018-05-28) 27046℃ 409评论62喜欢
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 4年前 (2020-09-06) 1151℃ 0评论0喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中提到,Hadoop的NameNode在重启的时候,将会进入到安全模式。而在安全模式,HDFS只支持访问元数据的操作才会返回成功,其他的操作诸如创建、删除文件等操作都会导致失败。 NameNode在重启的时候,DataNode需要向NameNode发送块的信息,NameNode只有获取到整个文件系统中有99.9%(可以配 w397090770 11年前 (2014-03-13) 17328℃ 3评论16喜欢
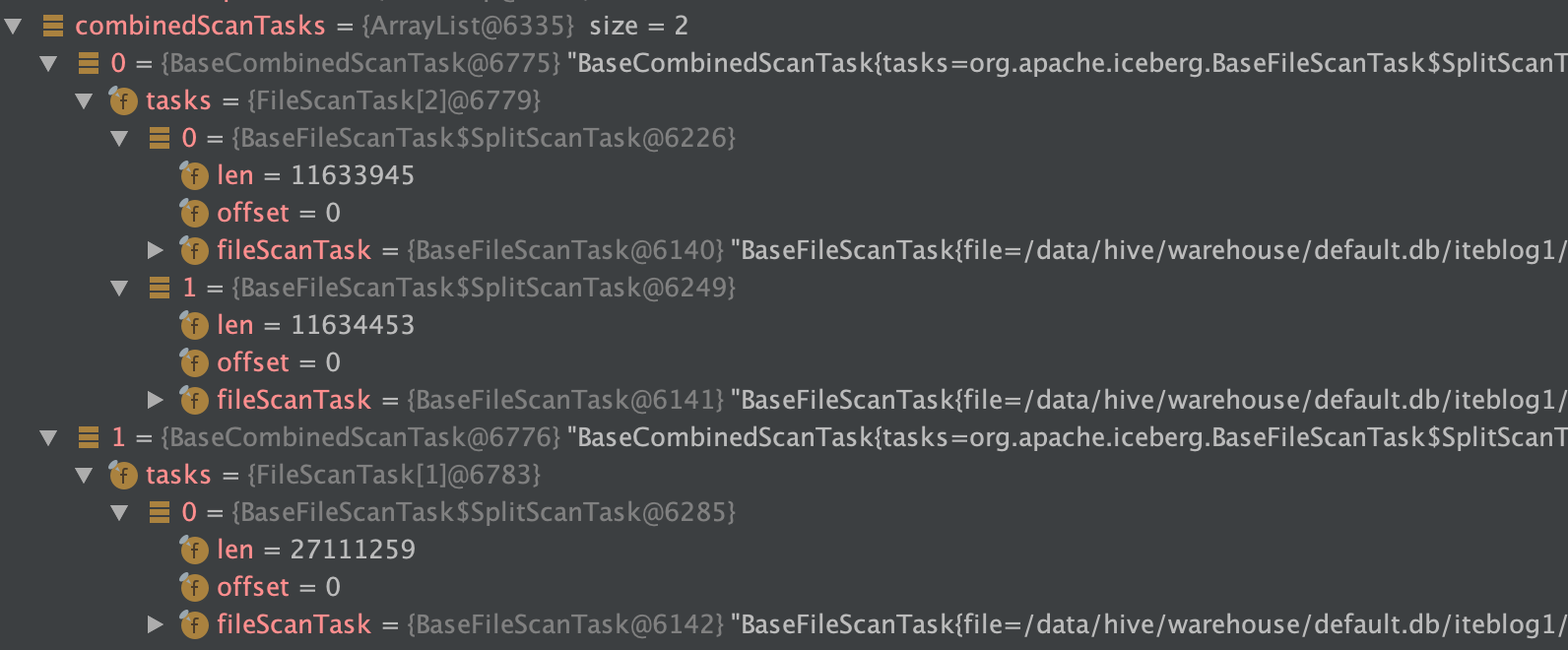
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 4年前 (2020-11-20) 6570℃ 6评论8喜欢
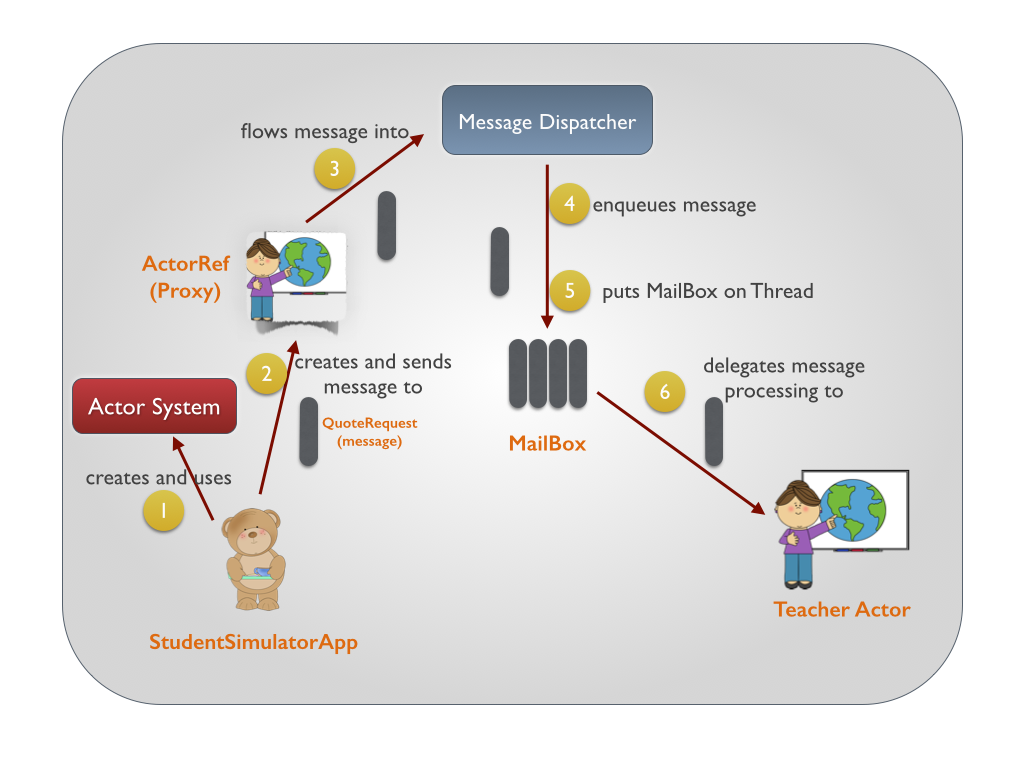
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21959℃ 5评论40喜欢
本文总结了几个本人在使用 Carbondata 的时候遇到的几个问题及其解决办法。这里使用的环境是:Spark 2.1.0、Carbondata 1.2.0。必须指定 HDFS nameservices在初始化 CarbonSession 的时候,如果不指定 HDFS nameservices,在数据导入是没啥问题的;但是数据查询会出现相关数据找不到问题:[code lang="scala"]scala> val carbon = SparkSession.builder().temp w397090770 7年前 (2017-11-09) 6597℃ 5评论14喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 4年前 (2020-11-29) 3611℃ 0评论4喜欢
北京第九次Spark Meetup活动于2015年08月22日下午14:00-18:00在北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼进行。活动内容如下: 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and Apache Zeppelin committer 3、《Apache Kylin introductio w397090770 9年前 (2015-09-04) 2669℃ 0评论4喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12458℃ 0评论34喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-06-26) 4298℃ 0评论6喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所以在选择不同当时监控时,我们需要详细了解需要我们的需 w397090770 8年前 (2016-06-23) 21253℃ 0评论34喜欢
在某些情况下,我们可能会在Spring中将一些WEB上的信息发送到Kafka中,这时候我们就需要在Spring中编写Producer相关的代码了;不过高兴的是,Spring本身提供了操作Kafka的相关类库,我们可以直接通过xml文件配置然后直接在后端的代码中使用Kafka,非常地方便。本文将介绍如果在Spring中将消息发送到Kafka。在这之前,请将下面的依赖 w397090770 8年前 (2016-11-01) 6240℃ 0评论11喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23935℃ 1评论23喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 10年前 (2014-09-08) 18320℃ 177评论16喜欢


![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)