在Scala中存在case class,它其实就是一个普通的class。但是它又和普通的class略有区别,如下:1、初始化的时候可以不用new,当然你也可以加上,普通类一定需要加new;[code lang="scala"]scala> case class Iteblog(name:String)defined class Iteblogscala> val iteblog = Iteblog("iteblog_hadoop")iteblog: Iteblog = Iteblog(iteblog_hadoop)scala> val iteblog w397090770 9年前 (2015-09-18) 38514℃ 1评论71喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 8年前 (2017-03-21) 9994℃ 0评论15喜欢
Short URL or tiny URL is an URL used to represent a long URL. For example, http://tinyurl.com/45lk7x will be redirect to http://www.snippetit.com/2008/10/implement-your-own-short-url.There are 2 main advantages of using short URL: Easy to remember - Instead of remember an URL with 50 or more characters, you only need to remember a few (5 or more depending on application's implementation). More portable - Some systems have limi w397090770 12年前 (2013-04-15) 20484℃ 0喜欢
本资料来自2022年03月03日举办的 Alluxio Day 活动。分享议题 《Speed Up Uber’s Presto with Alluxio》,分享者 Liang Chen 和王北南。Uber 的 Liang Chen 和 Alluxio 的王北南将为大家呈现 Alluxio Local Cache 上线过程中遇到的实际问题和有趣的发现。他们的演讲涵盖了 Uber 的 Presto 团队如何解决 Alluxio 的本地缓存失效的问题。Liang Chen 还将分享他使用定 w397090770 3年前 (2022-03-07) 333℃ 0评论2喜欢
在计算机人工智能领域,距离(distance)、相似度(similarity)是经常出现的基本概念,它们在自然语言处理、计算机视觉等子领域有重要的应用,而这些概念又大多源于数学领域的度量(metric)、测度(measure)等概念。 曼哈顿距离曼哈顿距离又称计程车几何距离或方格线距离,是由十九世纪的赫尔曼·闵可夫斯基所创词汇 ,为欧几里得几 w397090770 7年前 (2018-01-14) 6711℃ 0评论27喜欢
和Java一样,我们也可以使用Scala来创建Web工程,这里使用的是Scalatra,它是一款轻量级的Scala web框架,和Ruby Sinatra功能类似。比较推荐的创建Scalatra工程是使用Giter8,他是一款很不错的用于创建SBT工程的工具。所以我们需要在电脑上面安装好Giter8。这里以Centos系统为例进行介绍。安装giter8 在安装giter8之前需要安装Conscrip w397090770 9年前 (2015-12-18) 5785℃ 0评论10喜欢
七牛云存储直达地址:(点击这里) 随着网站建设的使用时间越来越长,我们的网站可能使用了越来越多的图片、CSS以及js文件,虽然这些的大小都不大,但如果请求的次数多了,这些文件的大小加起来就是一个可观的大小了!而且,如果你们页面图片或者js等文件多了,并且你的网站访问速度不太快的话,这会严重影响到 w397090770 10年前 (2015-01-12) 8795℃ 0评论11喜欢
经过去年年底的一段时间,本博客已经写了好几十篇关于Hive方面的文章,今天将这些博文汇总一下,以便大家查阅方便。同时,我将会在2014年继续更新《Hive的那些事》序列博文,对Hive比较关注的人,可以关注我的博客(/archives/category/hive的那些事:hive的那些事),由于个人水平有限,如博文有什么错误还希望大家指正。 w397090770 11年前 (2014-02-12) 9197℃ 0评论11喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7265℃ 1评论4喜欢
本文为阿里巴巴技术专家余根茂在社区发的一篇文章。Structured Streaming 最初是在 Apache Spark 2.0 中引入的,它已被证明是构建分布式流处理应用程序的最佳平台。SQL/Dataset/DataFrame API 和 Spark 的内置函数的统一使得开发人员可以轻松实现复杂的需求,比如支持流聚合、流-流 Join 和窗口。自从 Structured Streaming 发布以来,社区的开发人 w397090770 4年前 (2020-07-30) 738℃ 0评论1喜欢
使用 ElasticSearch 我们可以构建一个功能完备的搜索服务器。这一切实现起来都很简单,本文将花五分钟向你介绍如何实现。安装和运行Elasticsearch这篇文章的操作环境是 Linux 或者 Mac,在安装 ElasticSearch 之前,确保你的系统上已经安装好 JDK 6 或者以上版本。[code lang="bash"]wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearc w397090770 7年前 (2017-09-01) 3220℃ 0评论13喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9635℃ 0评论10喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 zz~~ 3年前 (2021-11-16) 550℃ 0评论0喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 7年前 (2017-06-07) 3568℃ 0评论21喜欢
Apache Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。 本文我们将介绍在Spark 2.0中如何使用SparkSession。更多关于SparkSession的文章请参见: w397090770 8年前 (2016-08-24) 15143℃ 2评论11喜欢
在《如何快速判断正整数是2的N次幂》文章中我们谈到如何快速的判断给定的正整数是否为2的N次幂,今天来谈谈如何快速地判断一个给定的正整数是否为4的N次幂。将4的幂次方写成二进制形式后,很容易就会发现有一个特点:二进制中只有一个1(1在奇数位置),并且1后面跟了偶数个0; 因此问题可以转化为判断1后面是否跟了 w397090770 11年前 (2013-09-30) 5051℃ 0评论5喜欢
我们在这篇文章简单介绍了 Apache Cassandra 是什么,以及有什么值得关注的特性。本文将简单介绍 Apache Cassandra 的安装以及简单使用,可以帮助大家快速了解 Apache Cassandra。我们到 Apache Cassandra 的官方网站下载最新版本的 Cassandra,在本文写作时最新版本的 Cassandra 为 3.11.4。Apache Cassandra 可以在 Linux、Unix、Mac OS 以及 Windows 上进行安装 w397090770 6年前 (2019-04-07) 5070℃ 0评论8喜欢
我们知道,编写Scala程序的时候可以使用下面两种方法之一:[code lang="scala"]object IteblogTest extends App { //ToDo}object IteblogTest{ def main(args: Array[String]): Unit = { //ToDo }}[/code] 上面的两种方法都可以运行程序,但是在Spark中,第一种方法有时可不会正确的运行(出现异常或者是数据不见了)。比如下面的代码运 w397090770 9年前 (2015-12-10) 5283℃ 0评论5喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1193℃ 0评论4喜欢
本章节我们提供一些 Java 8 中的 IntStream、LongStream 和 DoubleStream 使用范例。IntStream、LongStream 和 DoubleStream 分别表示原始 int 流、 原始 long 流 和 原始 double 流。这三个原始流类提供了大量的方法用于操作流中的数据,同时提供了相应的静态方法来初始化它们自己。这三个原始流类都在 java.util.stream 命名空间下。java.util.stream.Int w397090770 3年前 (2022-03-31) 194℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的内置数据类型可以分 w397090770 11年前 (2013-12-23) 15493℃ 1评论14喜欢
animate.css是一系列很酷的、有趣的以及跨浏览器的动画库,你可以在你的项目在红引入这个动画库。使用animate.css方式也非常简单,我们只需要在页面上引入animate.css文件,如下:[code lang="css"]<head> <link rel="stylesheet" href="animate.min.css"></head>[/code] 然后在你想动的元素上加上animated class。你 w397090770 9年前 (2015-08-28) 3267℃ 0评论3喜欢
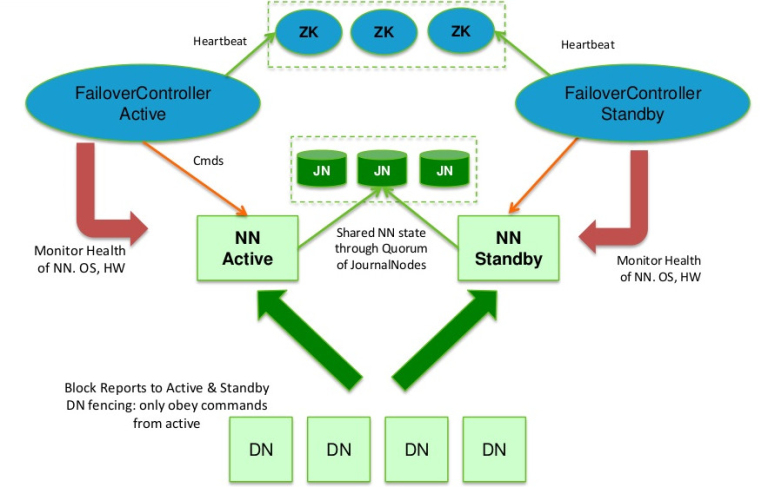
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10632℃ 3评论22喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 w397090770 4年前 (2021-01-21) 508℃ 0评论2喜欢
直到目前,我们看到的所有Mapreduce作业都输出一组文件。但是,在一些场合下,经常要求我们将输出多组文件或者把一个数据集分为多个数据集更为方便;比如将一个log里面属于不同业务线的日志分开来输出,并交给相关的业务线。 用过旧API的人应该知道,旧API中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat和org.apache.hadoop.mapr w397090770 11年前 (2013-11-26) 15122℃ 1评论10喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 4年前 (2020-12-25) 1285℃ 0评论4喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 430℃ 0评论3喜欢
本博客的《Spark与Mysql(JdbcRDD)整合开发》和《Spark RDD写入RMDB(Mysql)方法二》文章中介绍了如何通过Spark读写Mysql中的数据。 在生产环境下,很多公司都会使用PostgreSQL数据库,这篇文章将介绍如何通过Spark获取PostgreSQL中的数据。我将使用Spark 1.3中的DataFrame(也就是之前的SchemaRDD),我们可以通过SQLContext加载数据库中的数据, w397090770 9年前 (2015-05-23) 13001℃ 0评论11喜欢
全新美国区 Apple ID 注册教程参见:2021年最新美区 Apple ID 注册教程使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple ID 账号,但是很多人手上一般都是只有国内的账号,这篇文章就来教大家如何把一个中国区的 w397090770 3年前 (2021-10-10) 1473℃ 0评论2喜欢
Hadoop YARN自带了一系列的web service REST API,我们可以通过这些web service访问集群(cluster)、节点(nodes)、应用(application)以及应用的历史信息。根据API返回的类型,这些URL源归会类到不同的组。一些API返回collector类型的,有些返回singleton类型。这些web service REST API的语法如下:[code lang="JAVA"]http://{http address of service}/ws/{version}/{resourcepa w397090770 11年前 (2014-02-27) 26175℃ 2评论18喜欢