本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:降低延迟并改进有状态流处理;提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;改进资源分配和可伸缩性。下面我们来简单地看下这些目标。目标一: w397090770 3年前 (2022-02-23) 838℃ 0评论6喜欢
Delta Lake 是数砖公司在2017年10月推出来的一个项目,并于2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上开源的一个存储层。它是 Databricks Runtime 重要组成部分。为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构 w397090770 5年前 (2019-12-24) 4412℃ 0评论8喜欢
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 3年前 (2022-04-01) 443℃ 0评论1喜欢
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 8年前 (2017-03-29) 3408℃ 1评论10喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-09-05) 424℃ 0评论2喜欢
Spark支持读取很多格式的文件,其中包括了所有继承了Hadoop的InputFormat类的输入文件,以及平时我们常用的Text、Json、CSV (Comma Separated Values) 以及TSV (Tab Separated Values)文件。本文主要介绍如何通过Spark来读取Json文件。很多人会说,直接用Spark SQL模块的jsonFile方法不就可以读取解析Json文件吗?是的,没错,我们是可以通过那个读取Json w397090770 10年前 (2015-01-06) 26936℃ 10评论15喜欢
在这篇我们介绍了 Spark Delta Lake 0.4.0 的发布,并提到这个版本支持 Python API 和部分 SQL。本文我们将详细介绍 Delta Lake 0.4.0 Python API 的使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在本文中,我们将基于 Apache Spark™ 2.4.3,演示一个准时航班情况业务场景中,如何使用全新的 Delta Lake 0.4.0 w397090770 5年前 (2019-10-04) 963℃ 0评论1喜欢
在《Flink本地模式安装(Local Setup)》的文章中,我简单地介绍了如何本地模式安装(Local Setup)Flink,本文将介绍如何Flink集群模式安装,主要是Standalone方式。要求(Requirements)Flink可以在Linux, Mac OS X 以及Windows(通过Cygwin)等平台上运行。集群模式主要是由一个master节点和一个或者多个worker节点组成。在你启动集群的各个组件之前 w397090770 9年前 (2016-04-20) 11865℃ 0评论9喜欢
题目描述:将一个长度超过100位数字的十进制非负整数转换为二进制数输出。输入:多组数据,每行为一个长度不超过30位的十进制非负整数。(注意是10进制数字的个数可能有30个,而非30bits的整数)输出:每行输出对应的二进制数。样例输入:0138样例输出:01111000分析:这个数不应该存储到一个int类型变量里面去 w397090770 12年前 (2013-04-03) 5938℃ 0评论5喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 719℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 3年前 (2021-10-28) 551℃ 0评论1喜欢
本文转载至 http://www.ibm.com/developerworks/cn/java/j-dcl.html 单例创建模式是一个通用的编程习语。和多线程一起使用时,必需使用某种类型的同步。在努力创建更有效的代码时,Java 程序员们创建了双重检查锁定习语,将其和单例创建模式一起使用,从而限制同步代码量。然而,由于一些不太常见的 Java 内存模型细节的原因,并不能 w397090770 11年前 (2013-10-18) 4653℃ 4评论6喜欢
Imagick是PHP的本地扩展,通过调用ImageMagick提供的API来创建和修改图片。 而ImageMagick是一套软件系列,主要用于图片的创建、编辑以及创建bitmap图片,它支持很多格式的图片读取、转换以及编辑,这些格式包括了DPX, EXR, GIF, JPEG, JPEG-2000, PDF, PhotoCD, PNG, Postscript, SVG, and TIF等等。ImageMagick的官网(http://www.imagemagick.org/script/index.ph w397090770 9年前 (2015-08-19) 27569℃ 0评论4喜欢
ArrayListMultimap类的继承关系如下图所示:[caption id="attachment_744" align="aligncenter" width="593"] Guava ArrayListMultimap[/caption] ListMultimap是一个接口,继承自Multimap接口。ListMultimap接口为所有继实现自ListMultimap的子类定义了一些共有的方法签名。ListMultimap接口并没有定义自己特有的方法签名,里面所有的方法都是重写了Multimap接口中的声明 w397090770 11年前 (2013-09-24) 8267℃ 0评论2喜欢
假设我们有个需求,需要解析文件里面的Json数据,我们的Json数据如下:[code lang="xml"]{"website": "www.iteblog.com", "email": "hadoop@iteblog.com"}[/code]我们使用play-json来解析,首先我们引入相关依赖:[code lang="xml"]<dependency> <groupId>com.typesafe.play</groupId> <artifactId>play-json_2.10</artifactId w397090770 7年前 (2017-08-02) 2866℃ 0评论16喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 308℃ 0评论0喜欢
背景随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。现有方法及问题对于数据同步,我们目前 w397090770 5年前 (2020-01-04) 1173℃ 0评论6喜欢
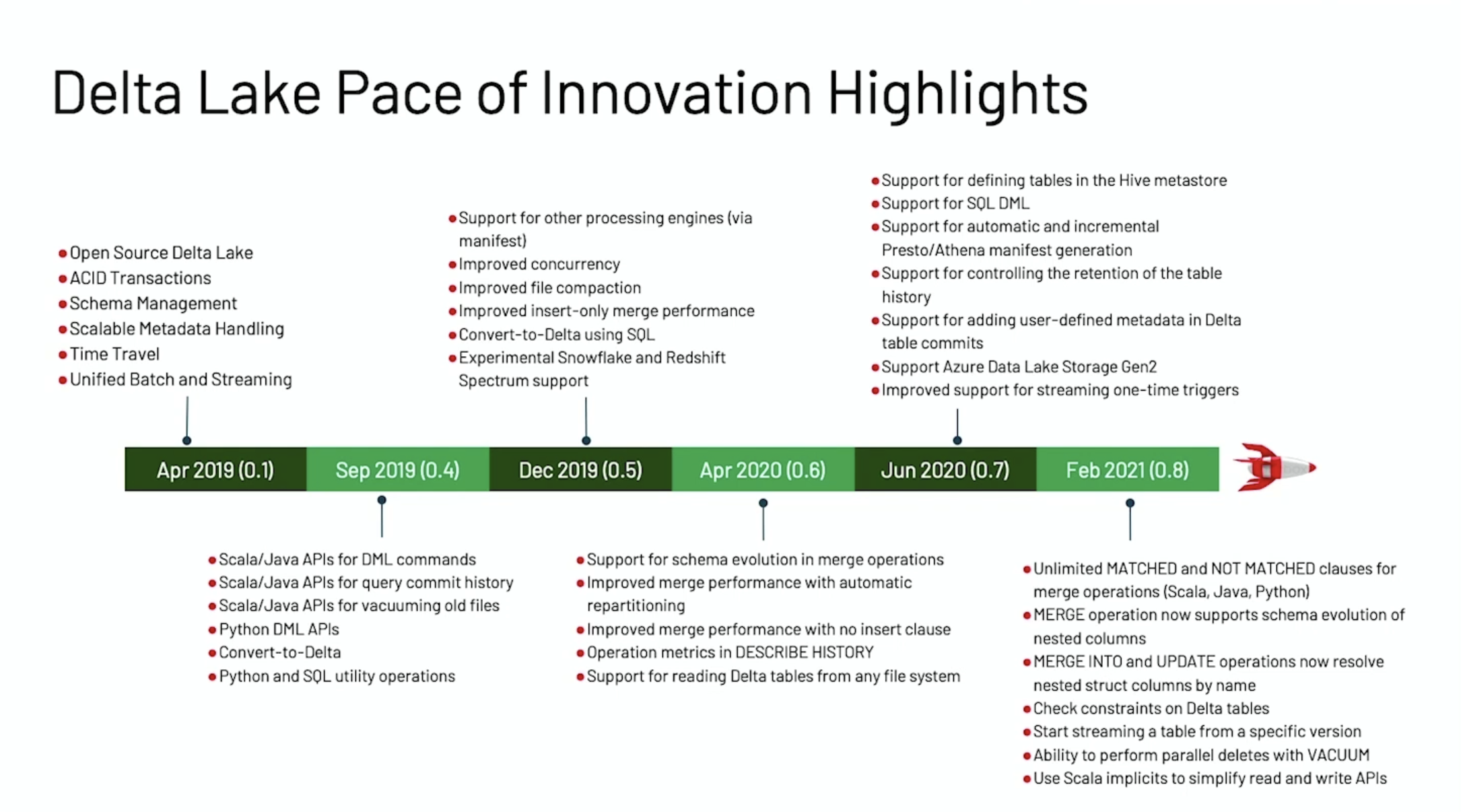
赶在 Data + AI Summit 2021 之前,Delta Lake 1.0.0 重磅发布,这个版本是基于 Spark 3.1 的,带来了许多新特性。本文将结合 Michael Armbrust 大牛在 Data + AI Summit 2021 的演讲《Announcing Delta Lake 1.0》来介绍 Delta Lake 1.0.0 版本的一些重要的新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据Delta Lake 0.1 w397090770 3年前 (2021-05-27) 851℃ 0评论2喜欢
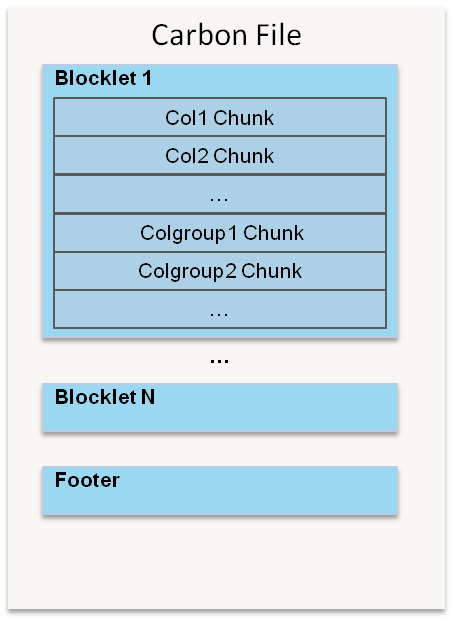
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 8年前 (2016-06-13) 5484℃ 0评论7喜欢
一、首先到oracle的官网下载Berkeley db数据库源文件下载地址http://download.oracle.com/otn/berkeley-db/db-5.3.15.tar.gz二、下载之后的文件是一个打包好的文件,需要在命令行里面利用tar来解压(当然你也可以利用一些可视化工具来解压),步骤如下在命令行里面输入[code lang="CPP"] tar -zxvf db-5.3.15.tar.gz[/code]解压之后进入db-5.3.15目录有以下 w397090770 12年前 (2013-04-04) 3942℃ 0评论0喜欢
如果你使用 Git 上传大于 100M 的文件时,你会遇到如下的问题:[code lang="bash"]iteblog@www.iteblog.com /d/spark-summit-north-america-2018-06 (master)$ git push origin masterfatal: AggregateException encountered. ▒▒▒▒һ▒▒▒▒▒▒▒▒▒▒Username for 'https://github.com': 397090770Counting objects: 78, done.Delta compression using up to 4 threads.Compressing objects: 100% (78/7 w397090770 6年前 (2018-06-17) 7601℃ 0评论7喜欢
sftp是Secure File Transfer Protocol的缩写,中文名称安全文件传送协议。其可以为传输文件提供一种安全的加密方法。sftp 与 ftp 有着几乎一样的语法和功能。SFTP 为 SSH的一部分,是一种传输档案至 Blogger 伺服器的安全方式。其实在SSH软件包中,已经包含了一个叫作SFTP(Secure File Transfer Protocol)的安全文件传输子系统,SFTP本身没有单独的守护 w397090770 7年前 (2017-06-21) 44057℃ 0评论21喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 4年前 (2020-06-28) 1020℃ 0评论1喜欢
在互联网网络中,当网络发生拥塞(congestion)时,交换机将开始丢弃数据包。这可能导致数据重发(retransmissions)、数据包查询(query packets),这些操作将进一步导致网络的拥塞。为了防止网络拥塞(network congestion),需限制流出网络的流量,使流量以比较均匀的速度向外发送。主要有两种限流算法:漏桶算法(Leaky Bucket)和 w397090770 6年前 (2018-06-04) 3334℃ 0评论4喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 9年前 (2015-11-07) 2109℃ 0评论8喜欢
通过使用易于理解的实例,本书将教你如何使用Spark Streaming构建实时应用程序。从安装和设置所需的环境开始,您将编写并执行第一个程序Spark Streaming。接下来将探讨Spark Streaming的架构和组件以及概述Spark公开的库/函数的。接下来,您将通过处理分布式日志文件的用例来了解有关Spark中的各种客户端API编码。然后,您将学习到各 w397090770 8年前 (2017-02-12) 3107℃ 0评论6喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u w397090770 7年前 (2018-02-14) 14950℃ 0评论21喜欢
大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时候会遇到以下的异常:[code lang="java"]Exception in thread "main" jav w397090770 7年前 (2017-07-04) 5380℃ 1评论16喜欢
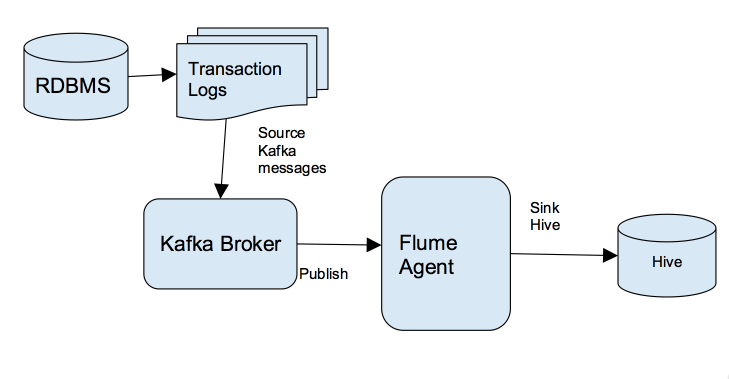
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11454℃ 6评论26喜欢
如今,互联网上存在大量功能相同的Web服务,但是它们的非功能属性(Quality of Service,QoS)一般相差很大,以至于用户在选择合适的Web服务时,把服务的QoS作为评判服务好坏的重要指标。QoS并不是在Web服务领域中产生的,它最先用在计算机网络和实时系统的非功能需求中,后来很多领域都引入了QoS指标,而且不同领域所用的QoS w397090770 12年前 (2013-05-16) 3642℃ 0评论6喜欢


















![[电子书]Learning Real-time Processing with Spark Streaming PDF下载](https://www.iteblog.com/pic/books/Learning_Real-time_Processing_with_Spark_Streaming-iteblog.jpg)