到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th w397090770 6年前 (2018-08-01) 1694℃ 0评论4喜欢
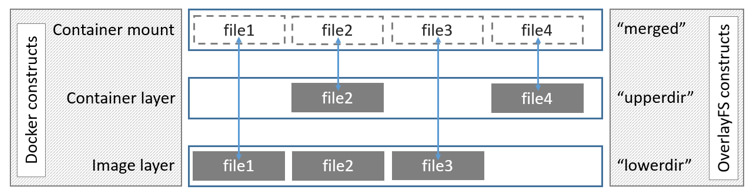
我们在 Docker 入门教程:镜像分层 和 Docker 入门教程:Docker 基础技术 Union File System 已经介绍了一些前提基础知识,本文我们来介绍 Union File System 在 Docker 的应用。为了使 Docker 能够在 container 的 writable layer 写一些比较小的数据(如果需要写大量的数据可以通过挂载盘去写),Docker 为我们实现了存储驱动(storage drivers)。Docker 使 w397090770 5年前 (2020-02-16) 756℃ 0评论5喜欢
在《Hadoop NameNode元数据相关文件目录解析》文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件:[code lang="JAVA"]current/|-- VERSION|-- edits_*|-- fsimage_0000000000008547077|-- fsimage_0000000000008547077.md5`-- seen_txid[/code] 其中存在大量的以edits开头的文件和少量的以fsimage开头的文件。那么这两种文件到底是什么,有什么用 w397090770 11年前 (2014-03-06) 20457℃ 1评论45喜欢
7.1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性。文档中词记为t,文档记为d , 语料库记为D . 词频TF(t,d) 是词t 在文档d 中出现的次数。文档频次DF(t,D) 是语料库中包括词t的文档数。如果使用词在文档中出现的频次表示词的重要程度,那么很容易取出反例, w397090770 9年前 (2016-03-27) 6041℃ 0评论6喜欢
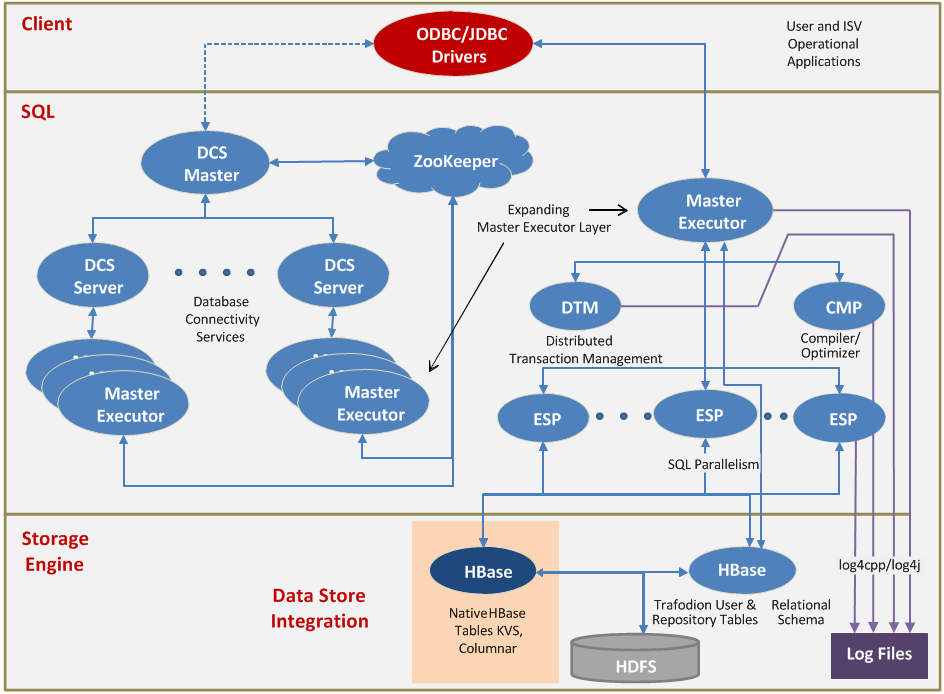
去年,我整理了2017年成功晋升为Apache TLP的大数据相关项目进行了整理,具体可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》。现在已经进入了2019年了,我在这里给大家整理了2018年成功晋升为 Apache TLP 的大数据相关项目。2018年晋升成 TLP 的项目不多,总共四个,按照项目晋升的时间进行排序的。Apache Trafodion:基于 Hadoop 平 w397090770 6年前 (2019-01-02) 1535℃ 0评论4喜欢
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程 w397090770 8年前 (2017-02-11) 1536℃ 0评论1喜欢
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下。Consumer Offset Checker Consumer Offset Checker主要是运行kafka.tools.ConsumerOffsetChecker类,对应的脚本是kafka-consumer-offset-checker.sh,会显示出Consumer的Group、Topic、分区ID、分区对应已经消费的Offset、 w397090770 9年前 (2016-03-18) 16019℃ 0评论13喜欢
本博客的《如何申请免费好用的HTTPS证书Let's Encrypt》和《在Nginx中使用Let's Encrypt免费证书配置HTTPS》文章分别介绍了如何申请Let's Encrypt的HTTPS证书和如何在nginx里面配置Let's Encrypt的HTTPS证书。但是Let's Encrypt HTTPS证书的有效期只有90天:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop到期之 w397090770 8年前 (2016-08-07) 1588℃ 0评论4喜欢
前提条件:安装好相应版本的Hadoop(可以参见《在Fedora上部署Hadoop2.2.0伪分布式平台》)、安装好JDK1.6或以上版本(可以参见《如何在Linux平台命令行环境下安装Java1.6》) Hive的下载地址:http://archive.apache.org/dist/hive/,你可以选择你适合的版本去下载。本博客下载的Hive版本为0.8.0。你可以运行下面的命令去下载Hive,并解压:[ w397090770 11年前 (2013-11-01) 15347℃ 6评论3喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-09-16) 119806℃ 4评论290喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 9年前 (2015-12-07) 24550℃ 2评论11喜欢
在 LinkedIn,我们非常依赖离线数据分析来进行数据驱动的决策。多年来,Apache Spark 已经成为 LinkedIn 的主要计算引擎,以满足这些数据需求。凭借其独特的功能,Spark 为 LinkedIn 的许多关键业务提供支持,包括数据仓库、数据科学、AI/ML、A/B 测试和指标报告。需要大规模数据分析的用例数量也在快速增长。从 2017 年到现在,LinkedIn 的 S w397090770 3年前 (2021-09-08) 1003℃ 0评论4喜欢
这篇文章是续着昨天的《Guava学习之SetMultimap》写的。AbstractSetMultimap是一个抽象类,主要是实现SetMultimap接口中的方法,但是其具体的实现都是调用了AbstractMapBasedMultimap类中的相应实现,只是将AbstractMapBasedMultimap类中返回类行为Collection的修改为Set。下面主要说说AbstractSetMultimap类的相关实现。 1、在AbstractMapBasedMultimap类中就 w397090770 11年前 (2013-09-26) 2858℃ 1评论5喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1496℃ 1评论0喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-30) 4843℃ 0评论4喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8515℃ 0评论44喜欢
Hadoop经常用于处理大量的数据,如果期间的输出数据、中间数据能压缩存储,对系统的I/O性能会有提升。综合考虑压缩、解压速度、是否支持split,目前lzo是最好的选择。LZO(LZO是Lempel-Ziv-Oberhumer的缩写)是一种高压缩比和解压速度极快的编码,它的特点是解压缩速度非常快,无损压缩,压缩后的数据能准确还原,lzo是基于block w397090770 11年前 (2014-03-25) 17558℃ 4评论10喜欢
如果我们Hadoop的core-site.xml文件中的fs.defaultFS配置由于某种原因需要修改,比如Hadoop升级、重新命名fs.defaultFS等。也就是由hdfs://olditeblog变成hdfs://newiteblogle ,如下:[code lang="bash"]<property> <name>fs.defaultFS</name> <value>hdfs://olditeblog</value></property>变成<property> <name>fs.defaultFS</ w397090770 9年前 (2015-08-27) 8539℃ 0评论14喜欢
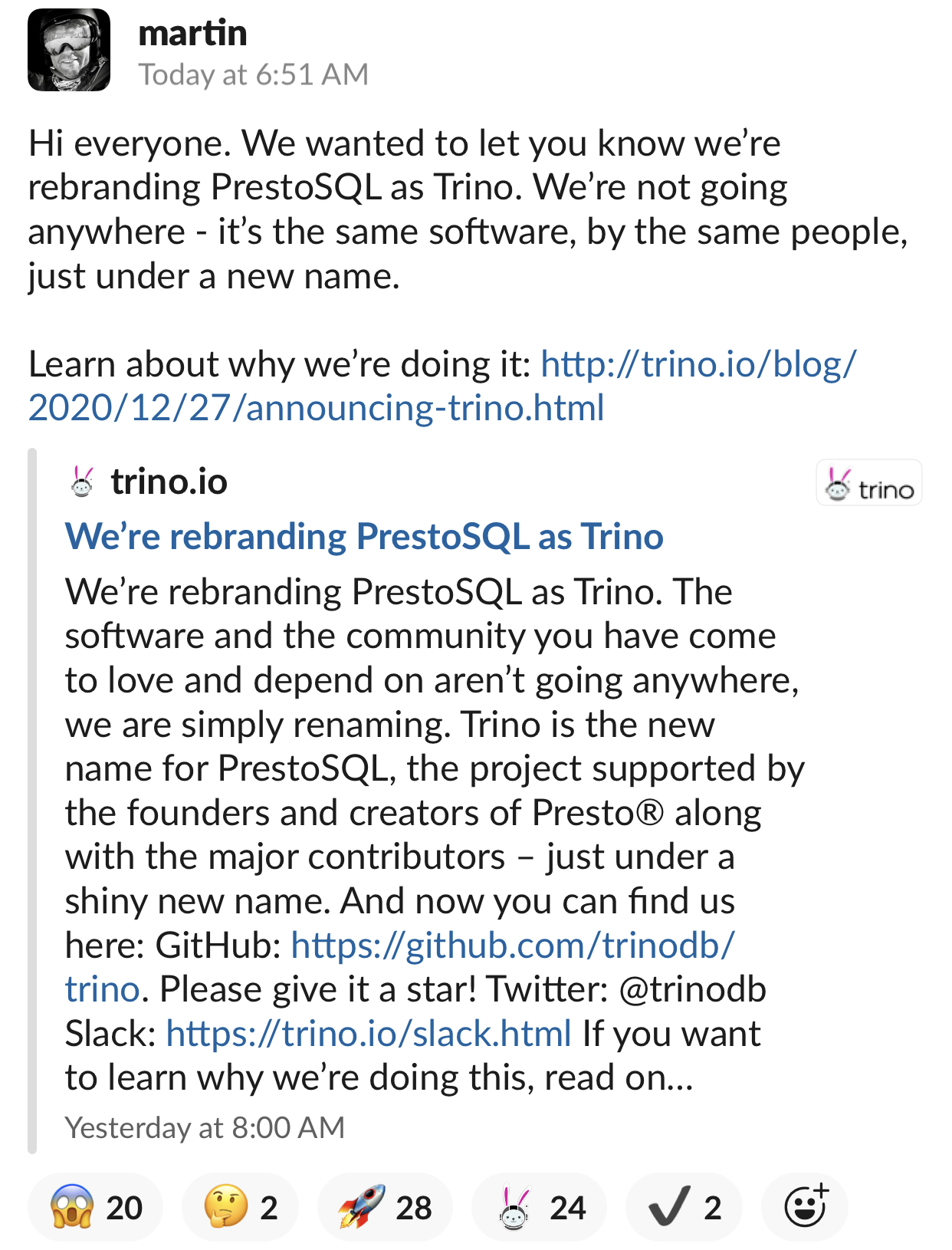
2020年12月27日,Martin Traverso、 Dain Sundstrom 以及 David Phillips 大佬们宣布将 PrestoSQL 项目的名字更名为 Trino。新的项目地址为 https://trino.io/。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop正如上图的描述,这个仅仅是更改名字,之前的社区和软件都还在那的,这个项目还是由 Presto 的创始人和创 w397090770 4年前 (2020-12-28) 1999℃ 0评论1喜欢
Linux提供了spilt命令来切割文件,我们可以按照行、文件大小对一个大的文件进行切割。先来看看这个命令的帮助:[code lang="shell"][iteblog@iteblog iteblog]$ split --helpUsage: split [OPTION]... [INPUT [PREFIX]]Output fixed-size pieces of INPUT to PREFIXaa, PREFIXab, ...; defaultsize is 1000 lines, and default PREFIX is `x'. With no INPUT, or when INPUTis -, read standard input. w397090770 9年前 (2015-12-14) 3660℃ 0评论5喜欢
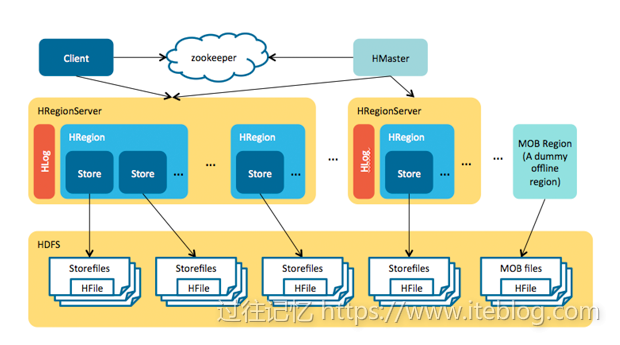
《Apache HBase中等对象存储MOB压缩分区策略介绍》 文章中介绍了 MOB 的一些压缩实现,并提及了一些 MOB 的一些简单使用,本文将详细地介绍 HBase MOB 的使用,本指南适合入门的开发者。将不同大小的文件(比如图片、文档等)存储到 HBase 非常的简单方便。从技术上来说,HBase 可以直接在一个单元格(Cell)存储大小到10MB的二进制对 w397090770 6年前 (2018-12-03) 2794℃ 0评论5喜欢
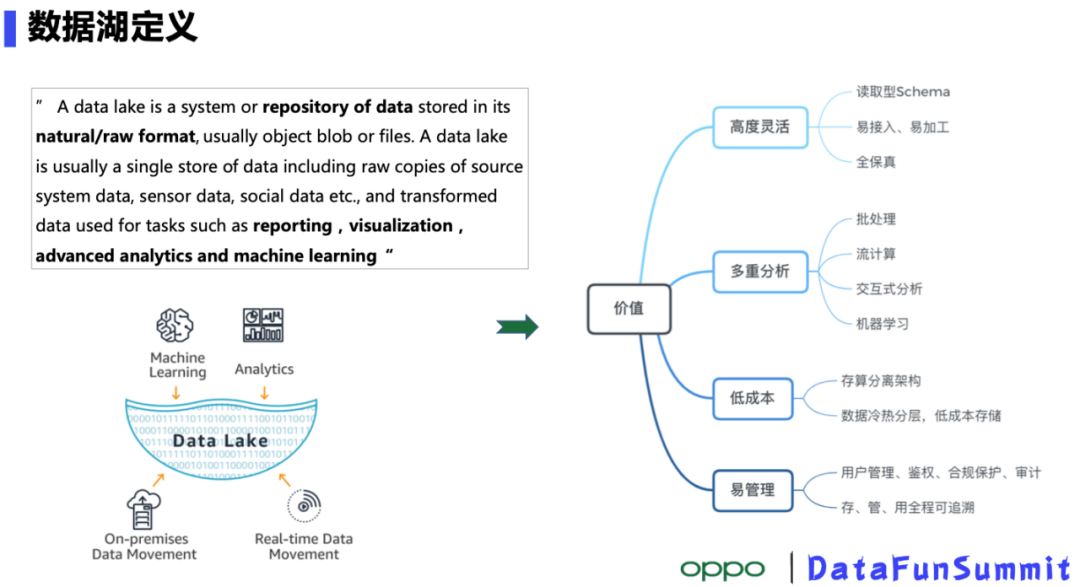
导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次Xiaochun He老师介绍的OPPO自研数据湖存储系统CBFS在很大程度上可 zz~~ 3年前 (2021-09-24) 420℃ 0评论2喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上述任务,而且还有更多的功能。与大多数下载管理器不同 w397090770 9年前 (2016-02-19) 1737℃ 0评论1喜欢
活动内容2015年下半年华东地区scala爱好者聚会,这次活动有杭州九言科技(代表作是In App)提供场地。本次活动内容不局限scala也包含一些创业公司的技术架构地点:杭州西湖区万塘路8号黄龙时代广场A座1802时间:2015年12月26日 13:00 ~ 2015年12月26日 17:30限制: 限额35人费用:免费活动安排1) 《scala和storm下的流式计算 w397090770 9年前 (2015-12-16) 2407℃ 0评论6喜欢
本书于2014年12月出版,共374页,这里提供的本身完整版。 w397090770 9年前 (2015-08-21) 2627℃ 0评论3喜欢
下面是一系列对Scala中的Lists、Array进行排序的例子,数据结构的定义如下:[code lang="scala"]// data structures working withval s = List( "a", "d", "F", "B", "e")val n = List(3, 7, 2, 1, 5)val m = Map( -2 -> 5, 2 -> 6, 5 -> 9, 1 -> 2, 0 -> -16, -1 -> -4)[/code] 利用Scala内置的sorted w397090770 10年前 (2014-11-07) 25955℃ 0评论23喜欢
Presto 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体 w397090770 2年前 (2022-06-23) 1552℃ 0评论3喜欢
到目前为止,我们在使用 CQL 建表的时候使用到了一些数据类型,比如 text、timeuuid等。本文将介绍 Apache Cassandra 内置及自定义数据类型。和其他语言一样,CQL 也支持一系列灵活的数据类型,包括基本的数据类型,集合类型以及用户自定义数据类(User-Defined Types,UDTs)。下面将介绍 CQL 支持的数据类型。如果想及时了解Spark、Hadoop或 w397090770 6年前 (2019-04-15) 2268℃ 0评论2喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 10年前 (2014-11-04) 19556℃ 5评论12喜欢
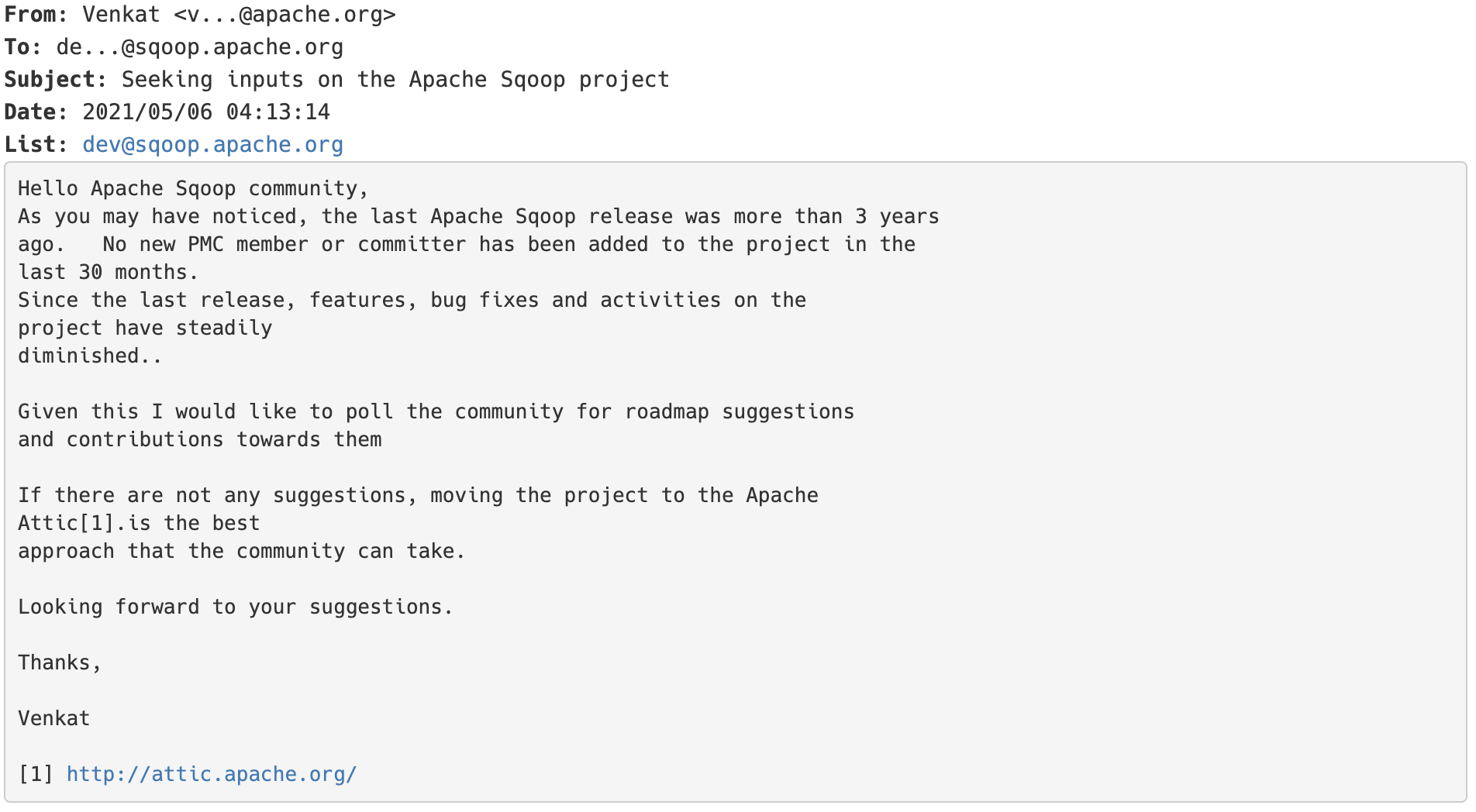
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 746℃ 0评论2喜欢

![Spark Summit East 2017部分PPT下载[共18个]](https://www.iteblog.com/pic/iteblog.png)






![Spark+AI Summit Europe 2019 PPT 下载[共122个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)




![[12-26]华东地区scala爱好者聚会](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/1.jpg)