背景熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从 w397090770 5年前 (2019-07-25) 2227℃ 0评论3喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 10年前 (2015-04-12) 11934℃ 9评论12喜欢
我在《Hadoop&Spark解决二次排序问题(Hadoop篇)》文章中介绍了如何在Hadoop中实现二次排序问题,今天我将介绍如何在Spark中实现。问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si w397090770 8年前 (2016-10-08) 6205℃ 0评论12喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1193℃ 0评论4喜欢
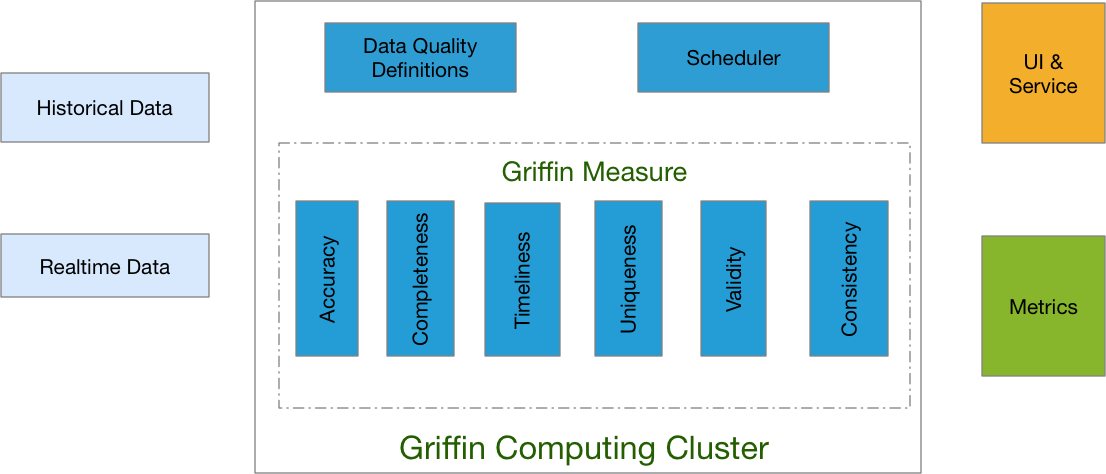
Apache Griffin 是开源的大数据数据质量解决方案,支持批处理和流模式,其是基于 Apache Hadoop 和 Apache Spark 构建,由 eBay 开发,并于 2016年12月07日进入 Apache 孵化。Griffin 提供了一个可以处理不同的任务,如定义数据质量模型,执行数据质量测量,自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化的全面的框架,旨在 w397090770 6年前 (2019-01-03) 9269℃ 3评论9喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2638℃ 0评论3喜欢
学过计算机编程的就知道,在计算机中,浮点数是不可能用浮点数精确的表达的,如果你需要精确的表达这个小数,我们最好是用分数的形式来表示,而且有限小数或无限小数都是可以转化为分数的形式。比如下面的几个小数:[code lang="bash"]0.3333(3) = 1/3的(其中括号中的数字是表示循环节)0.3 = 3 / 100.25 = 1 / 40. 285714(285714) = w397090770 12年前 (2013-03-31) 5414℃ 1评论8喜欢
本书于2017-08由Packt Publishing出版,作者Ankit Jain, 全书341页。通过本书你将学到以下知识Understand the core concepts of Apache Storm and real-time processingFollow the steps to deploy multiple nodes of Storm ClusterCreate Trident topologies to support various message-processing semanticsMake your cluster sharing effective using Storm schedulingIntegrate Apache Storm with other Big Data technolo zz~~ 7年前 (2017-08-30) 3724℃ 4评论16喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 5年前 (2019-06-27) 3053℃ 0评论6喜欢
相信很多人都用过代码写过不同的爬虫程序吧,来获取互联网上自己需要的信息,这比自己手动的去一个一个复制来的容易。但是,居然是用程序来获取某个网站里面的信息,可以知道,在很短的时间内,这个程序会访问某个网站很多次,很多网站都会对这样的情况进行屏蔽;比如,隔几分钟才能正常访问。这对于我们的爬虫 w397090770 12年前 (2013-04-02) 15906℃ 5评论26喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 w397090770 6年前 (2018-11-15) 5143℃ 1评论10喜欢
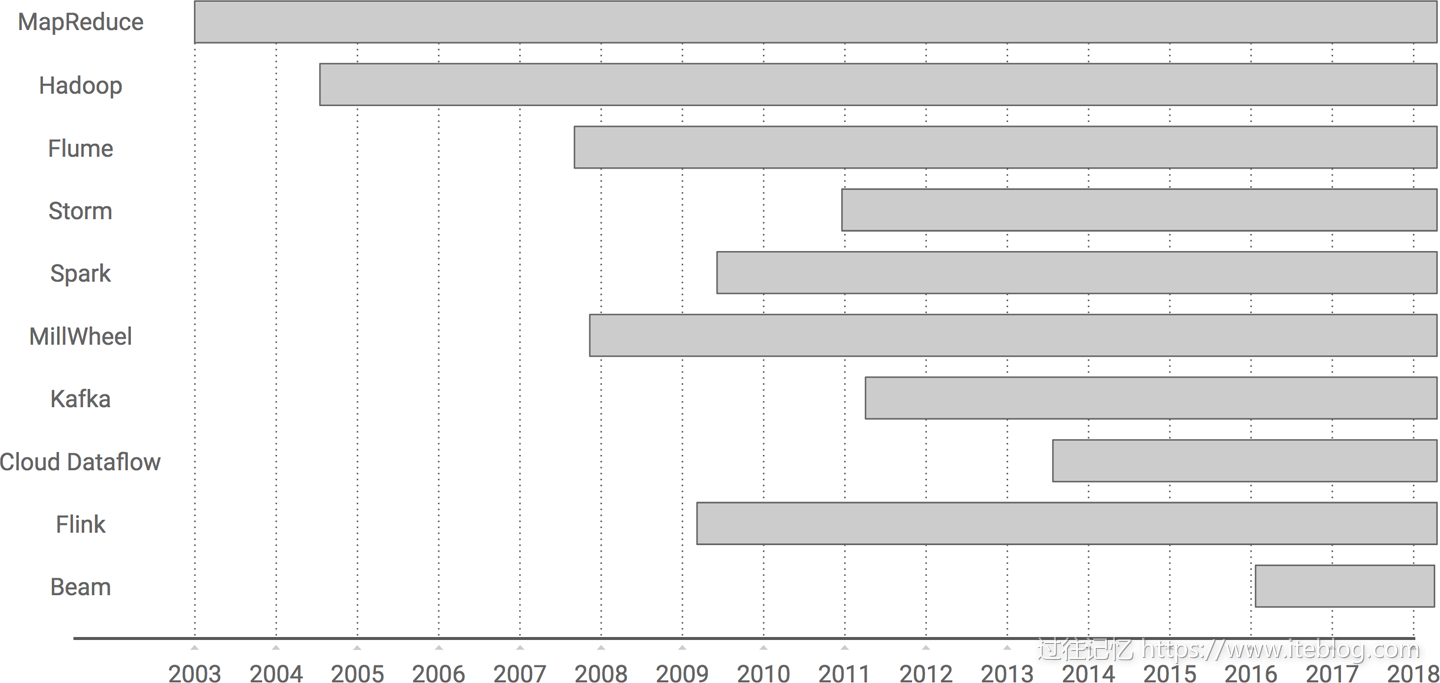
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10228℃ 2评论27喜欢
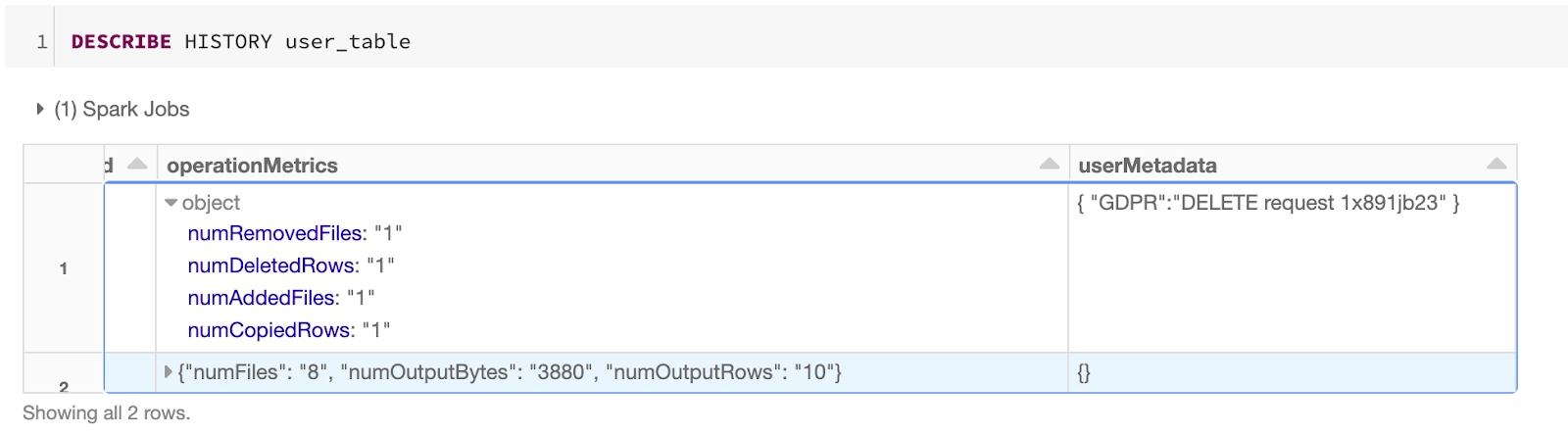
Delta Lake 0.7.0 是随着 Apache Spark 3.0 版本发布之后发布的,这个版本比较重要的特性就是支持使用 SQL 来操作 Delta 表,包括 DDL 和 DML 操作。本文将详细介绍如何使用 SQL 来操作 Delta Lake 表,关于 Delta Lake 0.7.0 版本的详细 Release Note 可以参见这里。使用 SQL 在 Hive Metastore 中创建表Delta Lake 0.7.0 支持在 Hive Metastore 中定义 Delta 表,而且这 w397090770 4年前 (2020-09-06) 1151℃ 0评论0喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在同年的12月成功毕业成为 Apache 基金会的顶级项目(《Apache Beam成为Apache顶级项目 w397090770 7年前 (2017-05-18) 1730℃ 0评论3喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 我们都知道,Apache Spark内置了很多操作数据的API。但是很多时候,当我们在现实中开发应用程序的时候,我们需要解决现实中遇到的问题,而这些问题可能在Spark中没有相应的API提供,这时候,我们就需要通过扩展Spark API来实现我们自己的方法。我们可 w397090770 10年前 (2015-03-30) 7184℃ 2评论15喜欢
WordPress 的自定义字段就是文章的meta 信息(元信息),利用这个功能,可以扩展文章的功能,是学习WordPress 插件开发和主题深度开发的必备。对自定义字段的操作主要有四种:添加、更新(修改)、删除、获取(值)。 1、首先自定义字段的添加函数,改函数可以为文章往数据库中添加一个字段:[code lang="php"]<?php add_ w397090770 10年前 (2015-04-30) 3527℃ 0评论8喜欢
本视频是炼数成金的Spark大数据平台视频,本课程在总结上两期课程的经验,对课程重新设计并将更新过半的内容,将最新版的spark1.1.0展现给有兴趣的学员。 更新:由于版权问题,本视频不提供下载地址,敬请理解。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时 w397090770 10年前 (2015-03-24) 56872℃ 18评论99喜欢
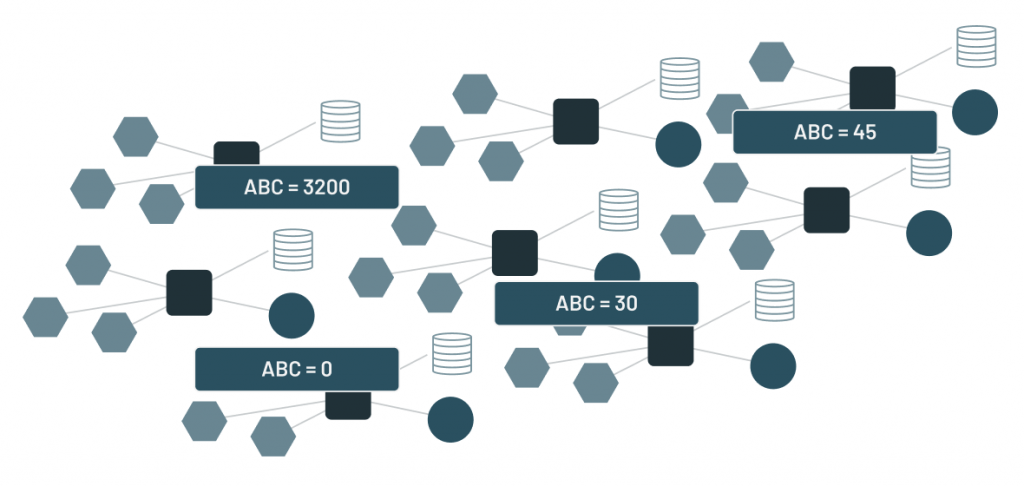
本文是 Forest Rim Technology 数据团队撰写的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被称为是数据仓库之父,最早的数据仓库概念提出者,被《计算机世界》评为计算机行业历史上最具影响力的十大人物之一。原始数据的挑战随着大量应用程序的出现,产生了相同的数据在不同地方出现不同值的情况。为了做出决定,用户必须找 w397090770 3年前 (2021-05-25) 604℃ 0评论0喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 122.246.148.77 8090 高匿名 HTTP 浙 w397090770 9年前 (2015-05-15) 41125℃ 0评论0喜欢
二叉树的前序遍历给你二叉树的根节点 root ,返回它节点值的 前序 遍历。示例 1:输入: [code lang="bash"] 1 \ 2 / 3 [/code]输出: [1,2,3]示例 2:输入: [code lang="bash"] 1 /2[/code]输出: [1,2]递归首先我们需要了解什么是二叉树的前序遍历:按照访问根节点——左子树——右子树的方式遍历这棵树,而在 w397090770 6年前 (2018-05-02) 58℃ 0评论0喜欢
本文将介绍如何在 Kafka 中使用 Avro 来序列化消息,并提供完整的 Producter 代码共大家使用。AvroAvro 是一个数据序列化的系统,它可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。因为本文并不是专门介绍 Avro 的文章,如需要更加详细地 zz~~ 7年前 (2017-09-22) 7136℃ 2评论23喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列 w397090770 8年前 (2016-05-23) 22152℃ 0评论27喜欢
Spark Streaming提供了高效便捷的流式处理模式,但是在有些场景下,使用默认的配置达不到最优,甚至无法实时处理来自外部的数据,这时候我们就需要对默认的配置进行相关的修改。由于现实中场景和数据量不一样,所以我们无法设置一些通用的配置(要不然Spark Streaming开发者就不会弄那么多参数,直接写死不得了),我们需 w397090770 10年前 (2015-04-27) 26941℃ 0评论34喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 10年前 (2014-06-16) 20781℃ 23评论14喜欢
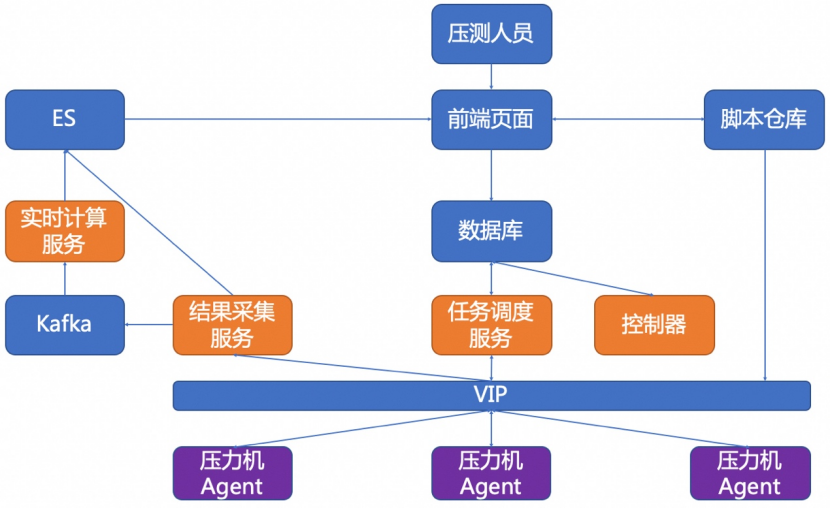
导读:压测是目前科技企业及传统企业进行系统容量评估、容量规划的最佳实践方式,本文将基于京东ForceBot平台在大促(京东618、京东双11)备战中的实践历程,给大家分享平台在压测方面的技术变革。ForceBot平台是一款分布式性能测试平台,能够为全链路压测构造千万量级的压测流量,并结合全域流量录制回放、瞬时发压、智能寻点 zz~~ 3年前 (2021-09-24) 299℃ 0评论1喜欢
在几年前,Oracle宣布不再维护Java 6的更新(看这里http://www.computerworld.com/article/2494112/application-security/oracle-to-stop-patching-java-6-in-february-2013.html),那么Java 6发现的新bug Oracle公司也就不再会去修改,这对用户来说就是不好的消息。 在前几天发布的Hadoop 2.7.0 (《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》)中的一个重要的 w397090770 10年前 (2015-05-06) 7463℃ 1评论4喜欢
本书于2017-07由Packt Publishing出版,作者Md. Rezaul Karim, Sridhar Alla,全书1587页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Understand object-oriented & functional programming concepts of ScalaIn-depth understanding of Scala collection APIsWork with RDD and DataFrame to learn Spark’s core abstractionsAnalysin zz~~ 7年前 (2017-08-21) 7817℃ 0评论31喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
简介nodetool是cassandra自带的外围工具,通过JMX可以动态修改当前进程内存数据,注意cassandra是无主对等架构,默认的命令是操作本机当前进程,例如repair,如果需要做全集群修复,需要在每台机器上执行对应的nodetool命令。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop执行nodetool help命令可 w397090770 5年前 (2019-09-08) 3648℃ 0评论3喜欢
2015年中国大数据技术大会已经圆满落幕,本届大会历时三天(2015-12-10~2015-12-12),以更加国际化的视野,从政策法规、技术实践和产业应用等角度深入探讨大数据落地后的挑战,作为大数据产业界、科技界与政府部门密切合作的重要平台,吸引了数千名大数据技术爱好者到场参会。 本届大会邀请了近百余位国内外顶尖的 w397090770 9年前 (2015-12-18) 5513℃ 0评论11喜欢




![[电子书]Mastering Apache Storm PDF下载](https://www.iteblog.com/pic/books/Mastering_Apache_Storm_iteblog.png)









![[电子书]Scala and Spark for Big Data Analytics PDF下载](https://www.iteblog.com/pic/books/Scala_and_Spark_for_Big_Data_Analytics_iteblog.png)
