本页面不再更新,请移步到 《2018 最新 hosts 文件持续更新》如果之前的hosts文件还有效可以不更新;由于大家使用的带宽种类,地区,被墙的程度不一样,所以有些地区使用本Hosts文件可能仍然无法使用Google;光靠修改Hosts文件是无法观看youtube里面的视频,重要的事说三遍:通过本hosts文件可以打开youtube网站,但是无法观看 w397090770 9年前 (2015-09-25) 194025℃ 376喜欢
分享嘉宾:Xiaochun He OPPO,编辑整理:门君仪 澳洲国立大学 导读:OPPO是一家智能终端制造公司,有着数亿的终端用户,手机 、IoT设备产生的数据源源不断,设备的智能化服务需要我们对这些数据做更深层次的挖掘。海量的数据如何低成本存储、高效利用是大数据部门必须要解决的问题。目前业界流行的解决方案是数据湖,本次 w397090770 3年前 (2022-02-18) 408℃ 0评论2喜欢
Apache ZooKeeper Essentials于2015年01月出版,全书共168页。本书是使用 Apache ZooKeeper 的快速入门指南。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop目录一共分为七章,目录安排如下:Chapter 1: A Crash Course in Apache ZooKeeperChapter 2: Understanding the Inner Workings of Apache ZooKeeperChapter 3: Programming with A w397090770 9年前 (2015-08-25) 3200℃ 0评论0喜欢
数据湖分析Data Lake Analytics是阿里云数据库自研的云原生数据湖分析系统,目前已有数千企业在使用,是阿里云 库、仓、湖战略高地之一 !!!现紧急招聘【 数据湖平台工程师】 产品链接:https://www.aliyun.com/product/datalakeanalytics !!!如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop团队内部拥有多 w397090770 4年前 (2020-05-22) 916℃ 0评论1喜欢
Mahout项目发展到了今天已经实现了许多的算法。下面列出Mahout项目主要的算法名称,供大家参考。一、协同过滤 Collaborative Filtering 1、基于用户的协同过滤 User-Based Collaborative Filtering 2、基于项目的协同过滤统 Item-Based Collaborative Filtering 3、交替最小二乘张量分解 Matrix Factorization with Alternating Least Squares 4、基 w397090770 10年前 (2014-09-23) 9512℃ 0评论17喜欢
在C++中,对象所占的内存在程序结束运行之前一直被占用,需要我们明确释放;而在Java中,当没有对象引用指向原先分配给某个对象的内存时,该内存便成为垃圾。JVM的一个系统级线程会自动释放该内存块。 垃圾收集意味着程序不再需要的对象是"无用信息",这些信息将被丢弃。当一个对象不再被引用的时候,内存回收它 w397090770 11年前 (2013-10-14) 7459℃ 2评论9喜欢
当前数据湖方向非常热门,市面上也出现了三款开源的数据湖产品:Delta Lake、Apache Hudi 以及 Apache Iceberg。这段时间抽了点时间看了下使用 Apache Spark 读写 Apache Iceberg 的代码。完全看代码肯定有些吃力,所以使用了代码调试功能。由于 Apache Iceberg 支持 Apache Spark 2.x 以及 3.x,并在创建了不同的模块。其相当于 Spark 的 Connect。Apache Spa w397090770 4年前 (2020-10-04) 1798℃ 0评论3喜欢
Elasticsearch最少需要Java 7版本,在本文写作时,推荐使用Oracle JDK 1.8.0_73版本。Java的安装和平台有关,所以本文并不打算介绍如何在各个平台上安装Java。在你安装ElasticSearch之前,先运行以下的命令检查你Java的版本:[code lang="java"]java -versionecho $JAVA_HOME[/code] 一旦我们将 Java 安装完成, 我们就可以下载并安装 Elasticsearch w397090770 8年前 (2016-08-29) 1513℃ 0评论1喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-10-10) 163679℃ 11评论384喜欢
由于需要在Flume里面加入一些我需要的代码,这时候就需要重新编译Flume代码,因为在编译Flume源码的时候出现了很多问题,所以写出这篇博客,以此分享给那些也需要编译代码的人一些参考,这里以如何编译Flume-0.9.4源码为例进行说明。 首先下载Flume0.9.4源码(可以到https://repository.cloudera.com/content/repositories/releases/com/cloudera/fl w397090770 11年前 (2014-01-22) 12258℃ 1评论4喜欢
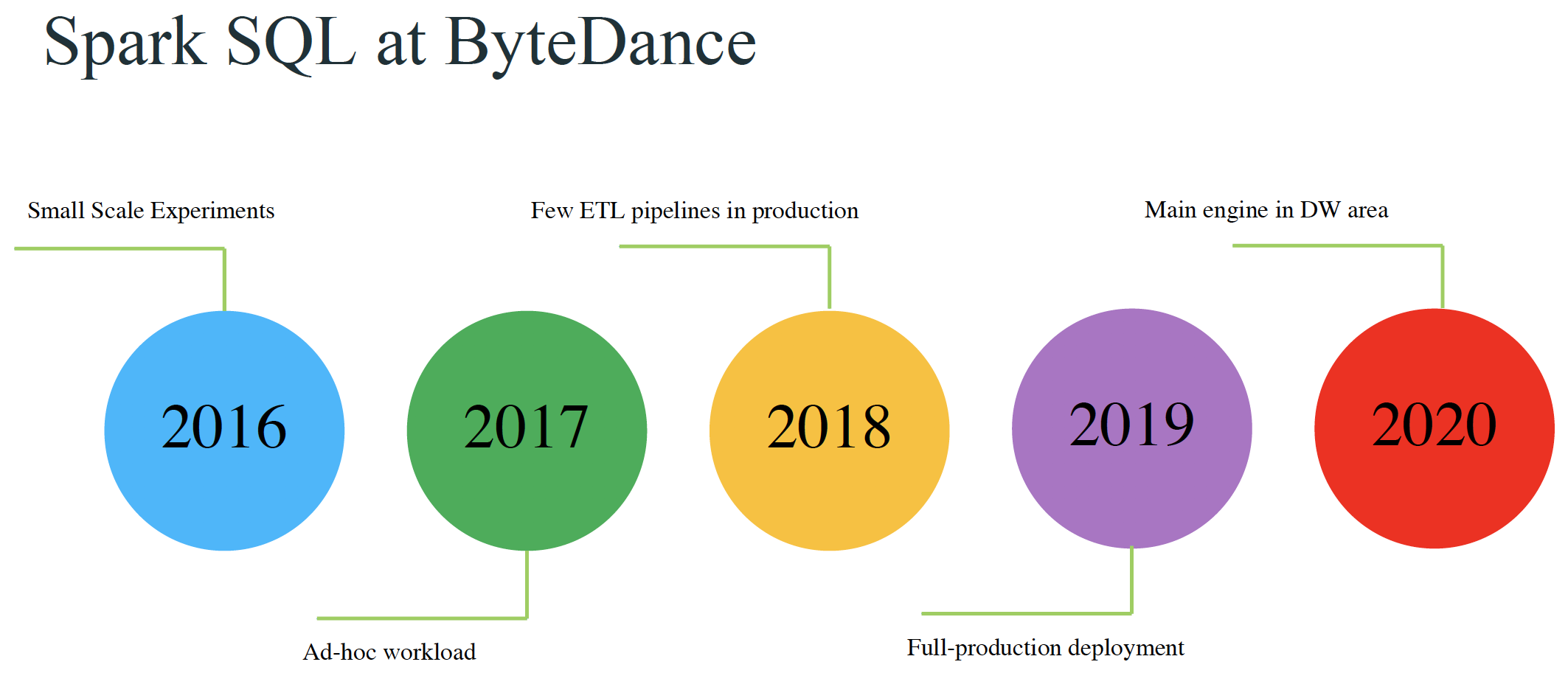
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 854℃ 0评论3喜欢
北京第九次Spark Meetup活动于2015年08月22日下午14:00-18:00在北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼进行。活动内容如下: 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and Apache Zeppelin committer 3、《Apache Kylin introductio w397090770 9年前 (2015-09-04) 2669℃ 0评论4喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 878℃ 0评论2喜欢
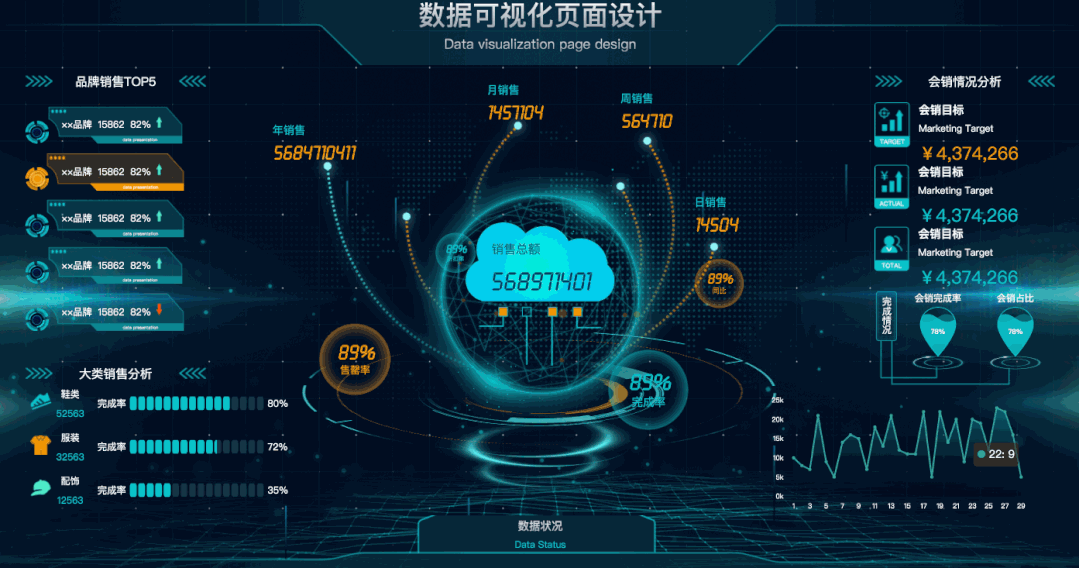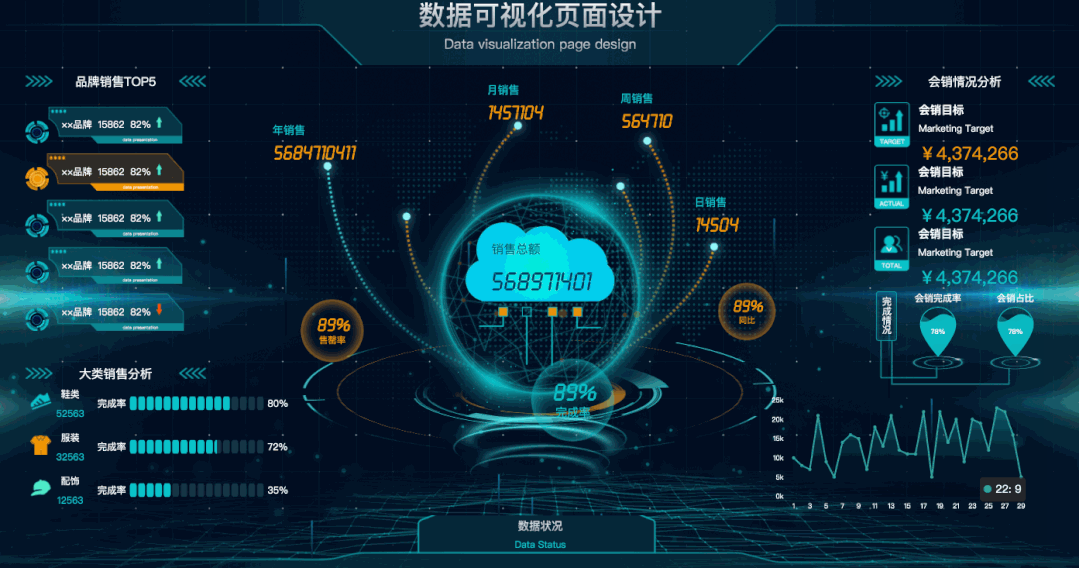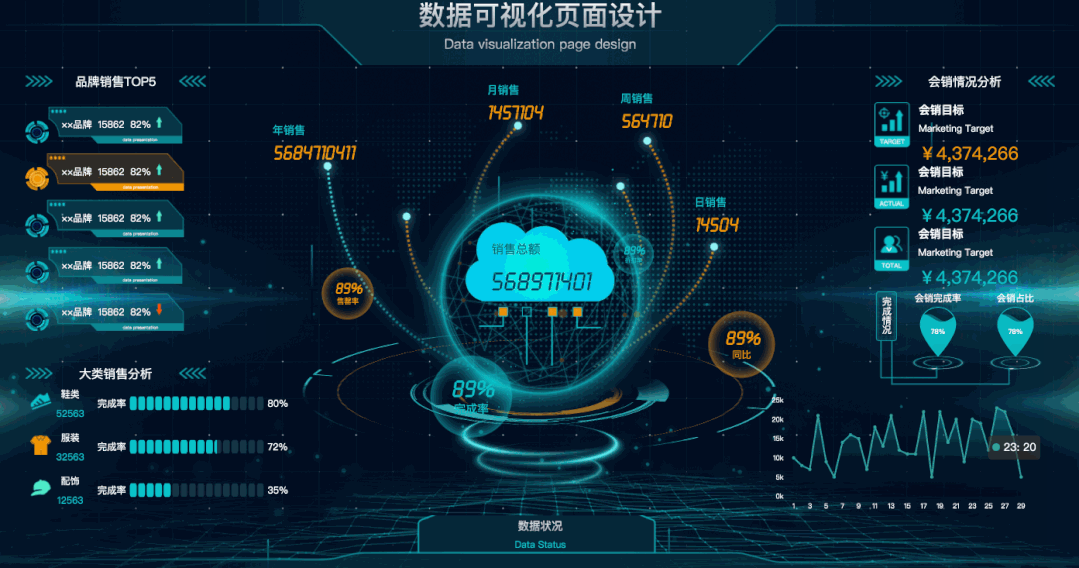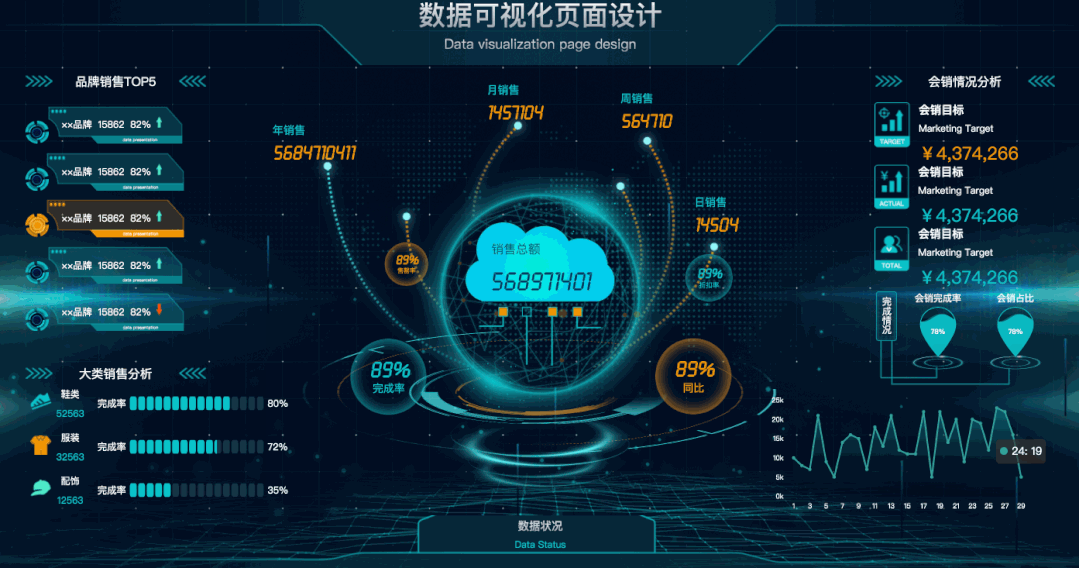
今天给大家分享30款开源的可视化大屏(含源码)。下载到本地后,直接运行文件夹中的index.html,即可看到大屏。01 数据可视化页面设计有动画效果,显得高大上!主要图表:柱状图、水球图、折线图等。02 数据可视化演示系统不仅有动画效果,还有科技感光效。主要图表:柱状图、折线图、饼图、地图等 zz~~ 3年前 (2021-12-23) 3724℃ 0评论4喜欢
在很多应用场景都需要对结果数据进行排序,Spark中有时也不例外。在Spark中存在两种对RDD进行排序的函数,分别是 sortBy和sortByKey函数。sortBy是对标准的RDD进行排序,它是从Spark 0.9.0之后才引入的(可以参见SPARK-1063)。而sortByKey函数是对PairRDD进行排序,也就是有Key和Value的RDD。下面将分别对这两个函数的实现以及使用进行说明。 w397090770 10年前 (2014-12-26) 83764℃ 7评论91喜欢
Web服务描述语言(WSDL)是一种用于描述Web服务或者网络端点的基于XML的语言。WSDL协议描述了Web服务之间的额消息处理机制、Web服务的位置,以及Web服务之间的通信协议。 WSDL与SOAP和UDDI一起工作,支持Web服务与Internet上的其他WEb服务、应用程序和设备交互作用。从本质上讲,UDDI提供了发布和定位Web服务的功能,WSDL描述了W w397090770 12年前 (2013-04-24) 3421℃ 0评论3喜欢
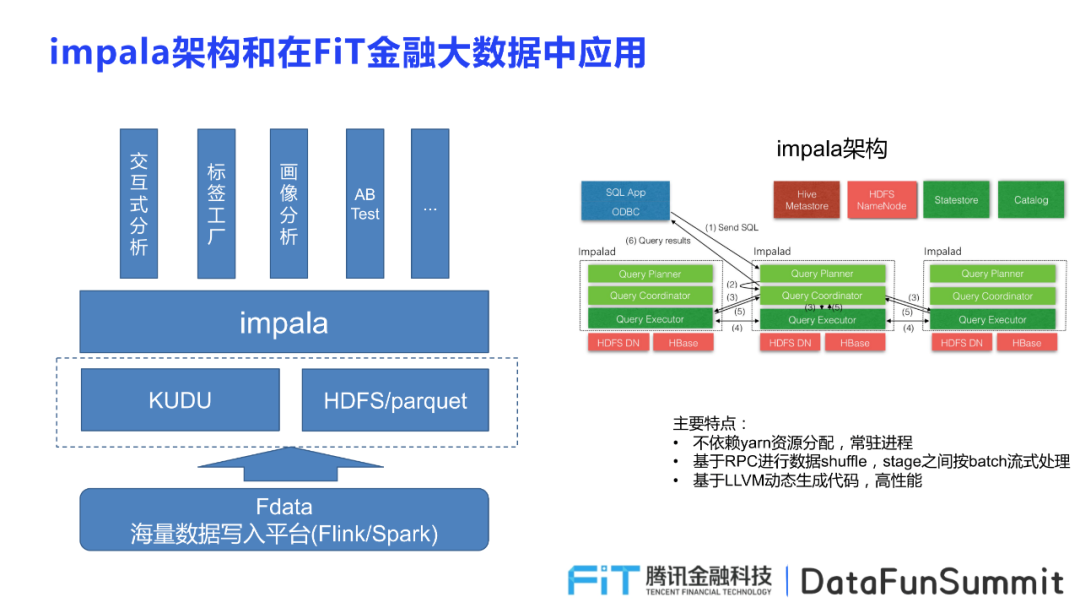
导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。Impala的架构 首先介绍Impala的整体架构,帮助大家从宏观角度理 w397090770 3年前 (2021-10-28) 389℃ 0评论1喜欢
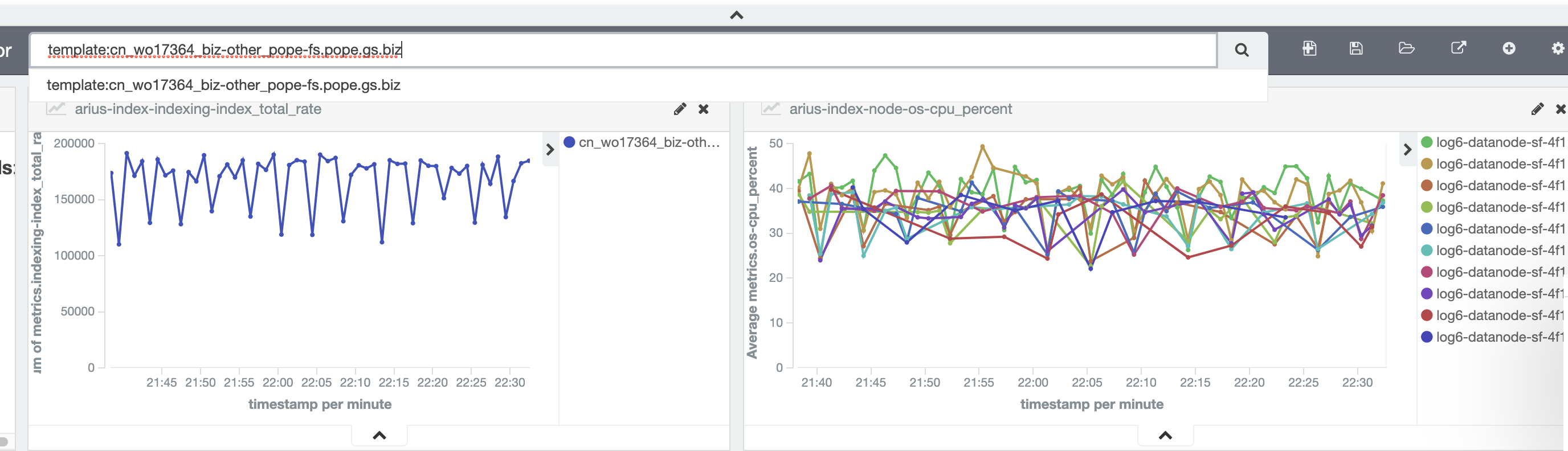
桔妹导读:滴滴ElasticSearch平台承接了公司内部所有使用ElasticSearch的业务,包括核心搜索、RDS从库、日志检索、安全数据分析、指标数据分析等等。平台规模达到了3000+节点,5PB 的数据存储,超过万亿条数据。平台写入的峰值写入TPS达到了2000w/s,每天近 10 亿次检索查询。为了承接这么大的体量和丰富的使用场景,滴滴ElasticSearch需要 w397090770 4年前 (2020-08-19) 1425℃ 0评论8喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 4年前 (2020-10-25) 1512℃ 0评论6喜欢
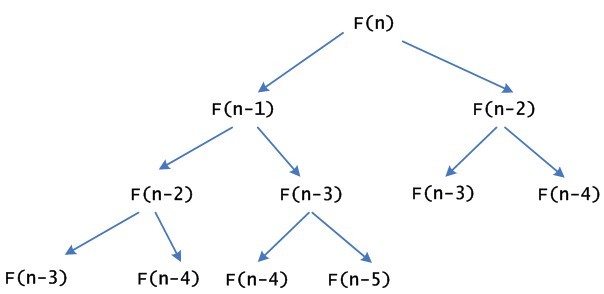
斐波那契数列又译费波拿契数、斐波那契数列、费氏数列、黄金分割数列。根据高德纳(Donald Ervin Knuth)的《计算机程序设计艺术》(The Art of Computer Programming),1150年印度数学家Gopala和金月在研究箱子包装物件长阔刚好为 1 和 2 的可行方法数目时,首先描述这个数列。 在西方,最先研究这个数列的人是比萨的列奥那多(又名费波 w397090770 12年前 (2013-04-16) 5892℃ 0评论6喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 在本博客的《Spark RDD API扩展开发(1)》文章中我介绍了如何在现有的RDD中添加自定义的函数。本文将介绍如何自定义一个RDD类,假如我们想对没见商品进行打折,我们想用Action操作来实现这个操作,下面我将定义IteblogDiscountRDD类来计算商品的打折,步骤如 w397090770 10年前 (2015-03-31) 11975℃ 0评论8喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1841℃ 0评论2喜欢
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序。但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序。基于此,本文提供三种方法来对MapReduce的输出进行全局排序。生成测试数据在介绍如何实现之前,我们先来生成一些测试数据,实现如下:[code lang="bash"]#! w397090770 7年前 (2017-05-10) 14494℃ 0评论29喜欢
代码生成是很多计算引擎中常用的执行优化技术,比如我们熟悉的 Apache Spark 和 Presto 在表达式等地方就使用到代码生成技术。这两个计算引擎虽然都用到了代码生成技术,但是实现方式完全不一样。在 Spark 中,代码生成其实就是在 SQL 运行的时候根据相关算子动态拼接 Java 代码,然后使用 Janino 来动态编译生成相关的 Java 字节码并 w397090770 3年前 (2021-09-28) 666℃ 0评论3喜欢
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 w397090770 4年前 (2020-04-17) 2371℃ 0评论3喜欢
我们在开发过程中,难免会进行一些误操作,比如下面我们提交 723cc1e commit 的时候把 2b27deb 和 0ff665e 不小心也提交到这个分支了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据0ff665e 是属于其他还没有合并到 master 分支的 MR,所以我们这里肯定不能把它带上来。我们需要把它删了。值得 w397090770 3年前 (2021-07-09) 581℃ 0评论1喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 8年前 (2016-08-31) 3333℃ 0评论5喜欢
我们在安装软件的时候,有时会出现由于依赖的软件没有被安装,会导致软件安装的失败,其实我们可以用命令来安装依赖的软件,这里以Ubuntu为例进行说明。 我在安装wps-office的时候,显示安装成功了,但是还是无法运行,后来才知道原来有些依赖的软件没有安装,导致wps无法运行。我们可以用户下面的命令查看依赖的 w397090770 10年前 (2014-11-21) 7106℃ 0评论2喜欢
在Scala中一个很强大的功能就是模式匹配,本文并不打算介绍模式匹配的概念以及如何使用。本文的主要内容是讨论Scala模式匹配泛型类型擦除问题。先来看看泛型类型擦除是什么情况:scala> def test(a:Any) = a match { | case a :List[String] => println("iteblog is ok"); | case _ => |} 按照代码的意思应该是匹配L w397090770 9年前 (2015-10-28) 6425℃ 0评论11喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7392℃ 0评论3喜欢