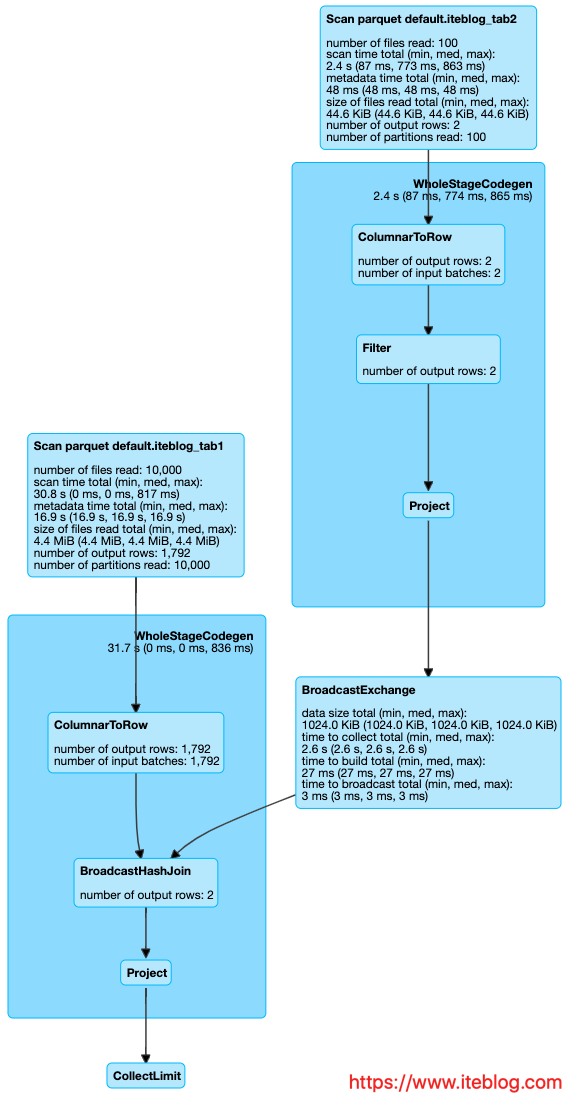
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 9年前 (2016-01-22) 12062℃ 16评论12喜欢
美国当地时间2020年05月11日,Apache Hudi 项目的共同创始人、PMC Vinoth Chandar 给社区发了一封标题为 [DISCUSS] Graduate Apache Hudi (Incubating) as a TLP 的邮件,来投票讨论 Apache Hudi 毕业成为 Apache TLP 项目。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop2020年05月19日共40人投票赞成 。不久社区给 Apache 董事 w397090770 4年前 (2020-05-22) 1173℃ 0评论1喜欢
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
PhantomJS是一个基于WebKit的服务器端JavaScript API,它基于BSD开源协议发布。PhantomJS无需浏览器即可实现对Web的支持,且原生支持各种Web标准,如DOM处理、JavaScript、CSS选择器、JSON、Canvas和可缩放矢量图形SVG。PhantomJS主要是通过JavaScript和CoffeeScript控制WebKit的CSS选择器、可缩放矢量图形SVG和HTTP网络等各个模块。PhantomJS主要支持Windows、M w397090770 9年前 (2016-04-29) 4204℃ 0评论5喜欢
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图像处理类库,名为:GraphFrames,该类库是构建在DataFrame之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。什么是GraphFrames 与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame因此GraphFrames与G w397090770 9年前 (2016-04-09) 4768℃ 0评论6喜欢
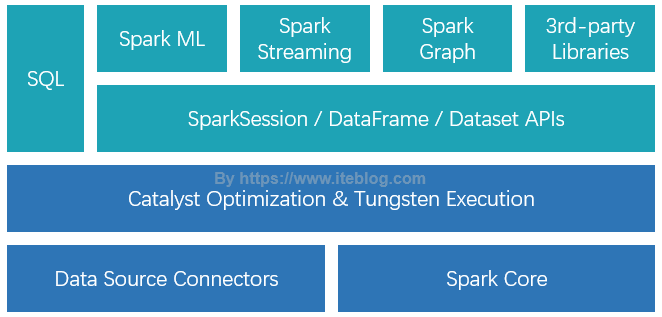
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 5年前 (2019-06-12) 10773℃ 0评论31喜欢
今天 Apache Kafka 项目的 2.0.0 版本正式发布了!距离 1.0 版本的发布,相距还不到一年。这一年不论是社区还是 Confluent 内部对于到底 Kafka 要向哪里发展都有很多讨论:从最初的标准消息系统,到现如今成为一个完整的包括导入导出和处理的流数据平台,从 0.8.2 一直到 1.0 版本,很多新特性和新部件被不断添加。但同时更重要的,关于 w397090770 6年前 (2018-06-28) 5266℃ 0评论6喜欢
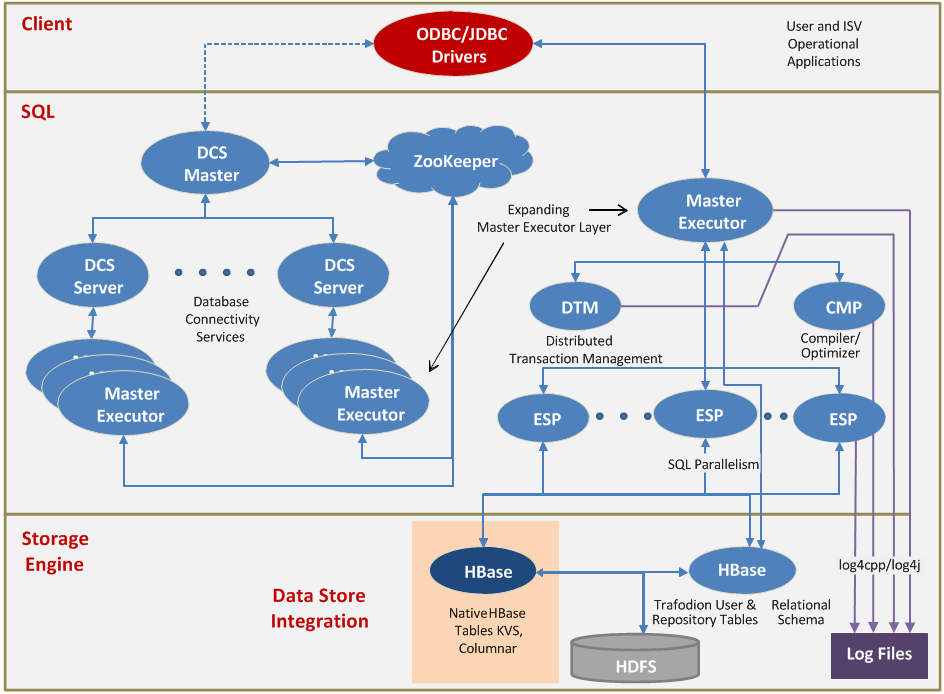
Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:完整的ANSI SQL语言支持完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护支持多种异构存储引擎的直接访问为应 w397090770 7年前 (2018-01-07) 2360℃ 0评论5喜欢
Carlos E. Perez对深度学习的2017年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中硬件将加速一倍摩尔定律(即2017年2倍) 如果你跟踪Nvidia和Intel的发展,这当然是显而易见的。Nvidia将在整个2017年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头 w397090770 8年前 (2016-12-13) 2196℃ 0评论3喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 10年前 (2014-06-16) 20781℃ 23评论14喜欢
在几年前,Oracle宣布不再维护Java 6的更新(看这里http://www.computerworld.com/article/2494112/application-security/oracle-to-stop-patching-java-6-in-february-2013.html),那么Java 6发现的新bug Oracle公司也就不再会去修改,这对用户来说就是不好的消息。 在前几天发布的Hadoop 2.7.0 (《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》)中的一个重要的 w397090770 10年前 (2015-05-06) 7463℃ 1评论4喜欢
本书重点介绍如何分析大量而且复杂的数据集。本书开头介绍了如何在各种集群管理上安装和配置Apache Spark,其中也会涵盖开发环境的设置。然后介绍了如何通过Spark SQL和实时流对各种数据源进行交互式查询,其中的实时流包括了Twitter Stream 和 Apache Kafka。然后,本书将专注于机器学习,包括监督学习,无监督学习和推荐引擎算 w397090770 8年前 (2017-02-12) 3182℃ 0评论3喜欢
背景随着同程旅行业务和数据规模越来越大,原有的机房不足以支撑未来几年的扩容需求,同时老机房的保障优先级也低于新机房。为了不受限于机房的压力,公司决定进行机房迁移。为了尽快完成迁移,需要1个月内完成上百PB数据量的集群迁移,迁移过程不允许停止服务。目前HADOOP集群主要有多个2.X版本,2019年升级到联 zz~~ 3年前 (2021-11-16) 614℃ 0评论1喜欢
重庆博尼施科技有限公司是一家商用车全周期方案服务商,利用车联网、云计算、移动互联网技术,在物流领域 为商用车的生产、销售、使用、售后、回收各个环节提供一站式解决方案,其中的新能源车辆监控系统就是由该公司提供的,本文是阿里云客户重庆博尼施科技有限公司介绍如何使用阿里云 HBase 来实现新能源车辆监控系统 w397090770 6年前 (2018-11-29) 4287℃ 2评论16喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 789℃ 0评论2喜欢
MySQL是一个开放源码的小型关联式数据库管理系统,开发者为瑞典MySQL AB公司。MySQL被广泛地应用在Internet上的中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多中小型网站为了降低网站总体拥有成本而选择了MySQL作为网站数据库。 MySQL是一种跨平台的数据库,在Ubuntu下安装Server的命令 w397090770 11年前 (2013-07-21) 3622℃ 0评论2喜欢
本书作者Venkat Ankam,由Packt Publishing出版社在2016年09月发行,全书供326页。本书基于Spark 2.0和Hadoop 2.7版本介绍,是适合数据分析师和数据科学家的参考手册,当然也适合那些想入门的人。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[code lang="bash"]Chapter 1: Big Data Analytics at a 10 zz~~ 8年前 (2016-11-21) 4677℃ 0评论6喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2301℃ 0评论5喜欢
在本博客的《Spark 0.9.1源码编译》和《Spark源码编译遇到的问题解决》两篇文章中,分别讲解了如何编译Spark源码以及在编译源码过程中遇到的一些问题及其解决方法。今天来说说如何部署分布式的Spark集群,在本篇文章中,我主要是介绍如何部署Standalone模式。 一、修改配置文件 1、将$SPARK_HOME/conf/spark-env.sh.template文件 w397090770 11年前 (2014-04-21) 9479℃ 1评论5喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2300℃ 0评论8喜欢
Material-UI是实现了Google Material模式的CSS框架,其中包括了一系列的React组建。Material Design是2014年Google I/O发布的 势必将会成为统一 Android Mobile、Android Table、Desktop Chrome 等全平台设计语言规范,对从业人员意义重大。 为了更好地使用这个框架,推荐大家先了解一下React Library,然后再使用Material-UI。如果想及时了解Spark、H w397090770 10年前 (2015-05-02) 11325℃ 1评论14喜欢
本文仅仅是简单地介绍如何在Ubuntu/Debian系统上安装Node.js(任何版本)和npm(Node Package Manager的简写),其他类Linux系统安装步骤和这个类似。 一、更新你的系统[code lang="bash"]iteblog# sudo apt-get updateiteblog# sudo apt-get install git-core curl build-essential openssl libssl-dev[/code] 二、安装Node.js 首先我们先从github上将Node w397090770 10年前 (2015-04-11) 27759℃ 0评论22喜欢
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-16) 6559℃ 0评论16喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 5年前 (2019-09-27) 1517℃ 0评论2喜欢
Spark的其中一个目标就是使得大数据应用程序的编写更简单。Spark的Scala和Python的API接口很简洁;但由于Java缺少函数表达式(function expressions), 使得Java API有些冗长。Java 8里面增加了lambda表达式,Spark开发者们更新了Spark的API来支持Java8的lambda表达式,而且与旧版本的Java保持兼容。这些支持将会在Spark 1.0可用。如果想及时了解 w397090770 10年前 (2014-07-10) 13193℃ 0评论18喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art w397090770 7年前 (2017-05-04) 1646℃ 0评论6喜欢
我在 这篇 文章中介绍了 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning),里面涉及到动态分区的优化思路等,但是并没有涉及到如何使用,本文将介绍在什么情况下会启用动态分区裁剪。并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这 w397090770 5年前 (2019-11-08) 2304℃ 0评论3喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 w397090770 8年前 (2017-02-09) 1954℃ 0评论1喜欢
HDFS设计之处并不支持给文件追加内容,这样的设计是有其背景的(如果想了解更多关于HDFS的append的曲折实现,可以参考《File Appends in HDFS》:http://blog.cloudera.com/blog/2009/07/file-appends-in-hdfs/),但从HDFS2.x开始支持给文件追加内容,可以参见https://issues.apache.org/jira/browse/HADOOP-8230。可以再看看http://www.quora.com/HDFS/Is-HDFS-an-append-only-file- w397090770 11年前 (2014-01-03) 34384℃ 3评论20喜欢
一. 问答题1) datanode在什么情况下不会备份?2) hdfs的体系结构?3) sqoop在导入数据到mysql时,如何让数据不重复导入?如果存在数据问题sqoop如何处理?4) 请列举曾经修改过的/etc下的配置文件,并说明修改要解决的问题?5) 描述一下hadoop中,有哪些地方使用了缓存机制,作用分别是什么?二. 计算题1、使用Hive或 w397090770 8年前 (2016-08-26) 4265℃ 1评论4喜欢






![[电子书]Spark Cookbook PDF下载](https://www.iteblog.com/pic/books/spark_cookbook_iteblog.jpg)


![[电子书]Big Data Analytics pdf下载](https://www.iteblog.com/pic/big-data-analytics-iteblog.jpg)