Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24213℃ 6评论22喜欢
JMX(Java Management Extensions,即Java管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。启动JMX监控,在启动java程序的时候最少需要在环境变量里面配置以下的选项:[code lang="bash"]-Dcom.sun.m w397090770 9年前 (2016-03-25) 6185℃ 0评论10喜欢
里氏替换法则(Liskov Substitution Principle LSP)是面向对象设计的六大基本原则之一(单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则)。这里说说里氏替换法则:父类的一个方法返回值是一个类型T,子类相同方法(重载或重写)返回值为S,那么里氏替换法则就要求S必须小于等于T,也就是说要么 w397090770 11年前 (2013-09-12) 4262℃ 3评论0喜欢
一、介绍 FairScheduler是一个资源分配方式,在整个时间线上,所有的applications平均的获取资源。Hadoop NextGen能够调度多种类型的资源。默认情况下,FairScheduler只是对内存资源做公平的调度(分配)。当集群中只有一个application运行时,那么此application占用这个集群资源。当其他的applications提交后,那些释放的资源将会被分配给新的 w397090770 9年前 (2015-12-03) 12057℃ 12评论15喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive w397090770 8年前 (2017-02-27) 3033℃ 0评论5喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 w397090770 3年前 (2021-07-17) 284℃ 0评论1喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1367℃ 0评论1喜欢
为期两个月开发的 Apache Flink 1.6.0 于今天(2018-08-09)正式发布了。Flink 社区艰难地解决了 360 个 issues,到这里查看完整版的 changelog 。Flink 1.6.0 是 1.x.y 版本系列上的第七个版本,1.x.y 中所有使用 @Public 标注的 API 都是兼容的。此版本继续使 Flink 用户能够无缝地运行快速数据处理并轻松构建数据驱动和数据密集型应用程序。Apache Fli w397090770 6年前 (2018-08-09) 1939℃ 0评论10喜欢
今天,Apache Beam 0.5.0 发布了,此版本通过新的State API添加对状态管道的支持,并通过新的Timer API添加对计时器的支持。 此外,该版本还为Elasticsearch和MQ Telemetry Transport(MQTT)添加了新的IO连接器,以及常见的一些错误修复和改进。对于此版本中的所有主要更改,请参阅release notes。如果想及时了解Spark、Hadoop或者Hbase相关的文 w397090770 8年前 (2017-02-10) 1026℃ 0评论2喜欢
本书由Vaibhav Kohli, Rajdeep Dua, John Wooten所著,全书共290页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Install Docker ecosystem tools and services, Microservices and N-tier applications 2、Create re-usable, portable containers with help of automation tools 3、Network and inter-link containers 4、Attach volumes securely to containe zz~~ 8年前 (2017-04-05) 1875℃ 2评论7喜欢
Apache Flink开源大数据处理系统最近比较火,特别是其流处理框架的设计。本文并不打算介绍Apache Flink的相关概念,如果你感兴趣可以到本博客的Flink分类目录查看Flink的相关文章。 转入正题了,下面将一步一步教你如何提交你的代码到Flink社区。1、提交Issue 既然能够提交代码肯定是发现了什么Bug,或者有什么好 w397090770 8年前 (2016-11-21) 3417℃ 0评论4喜欢
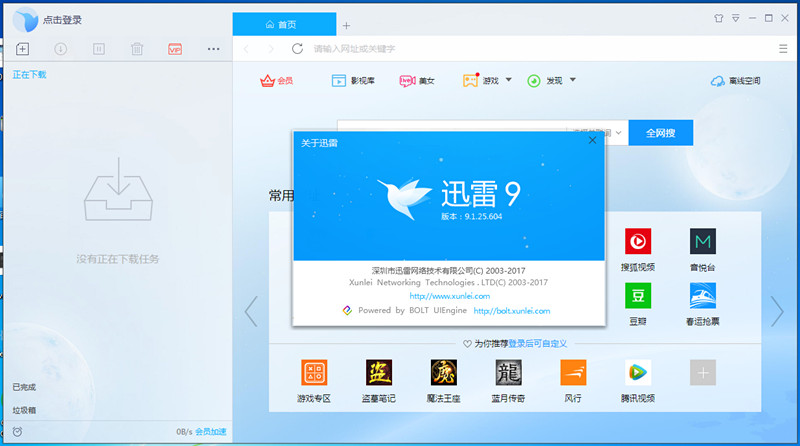
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6421℃ 0评论20喜欢
本视频是炼数成金的Spark大数据平台视频,本课程在总结上两期课程的经验,对课程重新设计并将更新过半的内容,将最新版的spark1.1.0展现给有兴趣的学员。 更新:由于版权问题,本视频不提供下载地址,敬请理解。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时 w397090770 10年前 (2015-03-24) 56872℃ 18评论99喜欢
Flink China社区线下 Meetup·上海站会议于 2018年7月29日 在上海市杨浦区政学路77号INNOSPACE进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程14:00-14:10 大沙 出品人开场发言14:10-14:40 阿里 巴真 《阿里在Flink的优化和改进分享》14:40-15:10 唯品会 王新春 《Flink在唯品会的实践》详细 w397090770 6年前 (2018-08-13) 2323℃ 0评论5喜欢
Dynamic filtering optimizations significantly improve the performance of queries with selective joins by avoiding reading of data that would be filtered by join condition. In this respect, dynamic filtering is similar to join pushdown discussed above, however it is the equivalent of inner join pushdown across data sources. As a consequence we derive the performance benefits associated with selective joins when performing federated queri w397090770 2年前 (2022-04-15) 422℃ 0评论1喜欢
使用用户设置好的聚合函数对每个Key中的Value进行组合(combine)。可以将输入类型为RDD[(K, V)]转成成RDD[(K, C)]。函数原型[code lang="scala"]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) : RDD[(K, C)]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitio w397090770 10年前 (2015-03-19) 22566℃ 0评论23喜欢
Apache ZooKeeper Essentials于2015年01月出版,全书共168页。本书是使用 Apache ZooKeeper 的快速入门指南。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop目录一共分为七章,目录安排如下:Chapter 1: A Crash Course in Apache ZooKeeperChapter 2: Understanding the Inner Workings of Apache ZooKeeperChapter 3: Programming with A w397090770 9年前 (2015-08-25) 3200℃ 0评论0喜欢
Hadoop经常用于处理大量的数据,如果期间的输出数据、中间数据能压缩存储,对系统的I/O性能会有提升。综合考虑压缩、解压速度、是否支持split,目前lzo是最好的选择。LZO(LZO是Lempel-Ziv-Oberhumer的缩写)是一种高压缩比和解压速度极快的编码,它的特点是解压缩速度非常快,无损压缩,压缩后的数据能准确还原,lzo是基于block w397090770 11年前 (2014-03-25) 17558℃ 4评论10喜欢
数据库事业部承载着阿里巴巴及阿里云的数据库服务,为超过数万家中国企业提供专业的数据库服务。我们提供在线事务处理、缓存文档服务、BigData NoSQL服务 、在线分析处理的全栈数据库产品。本团队提供基于Apache HBase\Phoenix\Spark\Cassandra\Solr\ES等,结合自研技术,打造存储、检索、计算的一站式的BigData NoSQL自主可控的服务,满足客 w397090770 7年前 (2018-01-30) 6476℃ 1评论28喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的 w397090770 7年前 (2018-01-01) 3480℃ 0评论10喜欢
下面的操作会影响到Spark输出RDD分区(partitioner)的: cogroup, groupWith, join, leftOuterJoin, rightOuterJoin, groupByKey, reduceByKey, combineByKey, partitionBy, sort, mapValues (如果父RDD存在partitioner), flatMapValues(如果父RDD存在partitioner), 和 filter (如果父RDD存在partitioner)。其他的transform操作不会影响到输出RDD的partitioner,一般来说是None,也就是没 w397090770 10年前 (2014-12-29) 16575℃ 0评论5喜欢
基本格式f1 f2 f3 f4 f5 program分 时 日 月 周 命令 第1列表示分钟1~59每分钟用*或者 */1表示;第2列表示小时1~23(0表示0点);第3列表示日期1~31;第4列表示月份1~12;第5列标识号星期0~6(0表示星期天);第6列要运行的命令 当 f1 为 * 时表示每分钟都要执行 program,f2 为* 时表示每小时都要执行程序, w397090770 10年前 (2015-02-22) 3919℃ 0评论7喜欢
这篇文章中将介绍C# 6.0的一个新特性,这将加深我们对Scala monad的理解。Null-conditional操作符 假如我们有一个嵌套的数据类型,然后我们需要访问这个嵌套类型里面的某个属性。比如Article可以没有作者(Author)信息;Author可以没有Address信息;Address可以没有City信息,如下:[code lang="csharp"]//////////////////////////////////// w397090770 9年前 (2016-02-24) 2137℃ 0评论6喜欢
备份数据库,还原数据库的情况,我们一般用一下两种方式来处理:1.使用into outfile 和 load data infile导入导出备份数据这种方法的好处是,导出的数据可以自己规定格式,并且导出的是纯数据,不存在建表信息,你可以直接导入另外一个同数据库的不同表中,相对于mysqldump比较灵活机动。我们来看下面的例子:(1)下面 w397090770 10年前 (2014-08-15) 4813℃ 0评论5喜欢
前言 如果你尝试使用Apache Log4J中的DailyRollingFileAppender来打印每天的日志,你可能想对那些日志文件指定一个最大的保存数,就像RollingFileAppender支持maxBackupIndex参数一样。不过遗憾的是,目前版本的Log4j (Apache log4j 1.2.17)无法在使用DailyRollingFileAppender的时候指定保存文件的个数,本文将介绍如何修改DailyRollingFileAppender类,使得它 w397090770 9年前 (2016-04-12) 5646℃ 0评论3喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Improve Presto Architectural Decisions with Shadow Cache at Facebook》的分享,作者来自 Facebook 的 Ke Wang 和 普林斯顿CS系的 Zhenyu Song。Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.Zhenyu Song is a Ph.D. student at Princeton CS Department. He works on using mach w397090770 3年前 (2021-11-16) 259℃ 0评论1喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19770℃ 4评论92喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第一篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-15) 12502℃ 2评论10喜欢
前面谈到了Guava中新引入的Range类,也了解了其中的作用,那么今天来谈谈Guava中用到Range来的地方:RangeSet类。RangeSet类是用来存储一些不为空的也不相交的范围的数据结构。假如需要向RangeSet的对象中加入一个新的范围,那么任何相交的部分都会被合并起来,所有的空范围都会被忽略。 讲了这么多,我们该怎么样利用RangeS w397090770 11年前 (2013-07-17) 7403℃ 1评论4喜欢
IntelliJ IDEA 2020.2 稳定版已发布,此版本带来了不少新功能,包括支持在 IDE 中审查和合并 GitHub PR、新增加的 Inspections 小组件(Inspections Widget)支持在文件的警告和错误之间快速导航、使用 Problems 工具窗口查看当前文件中的完整问题列表,并在更改会破坏其他文件时收到通知。此外还有针对部分框架和技术的新功能,包括支持使 w397090770 4年前 (2020-07-29) 373℃ 0评论2喜欢







![[电子书]Troubleshooting Docker PDF下载](https://www.iteblog.com/pic/books/Troubleshooting_Docker_iteblog.png)