第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 7年前 (2017-12-06) 2020℃ 0评论11喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1841℃ 0评论2喜欢
默认情况下,nginx将每天网站访问的日志都写在一个文件里面,随着时间的推移,这个文件势必越来越大,最终成为问题。不过我们可以写个脚本来自动地按天(或者小时)切割日志,并压缩(节约磁盘空间)。 脚本的内容如下:[code lang="bash"]#!/bin/bash logspath="/alidata/log/Nginx/access/"yesterday=`date -d '-1 day' +%Y%m%d`mv ${lo w397090770 10年前 (2015-01-02) 15873℃ 0评论10喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer,从而充分利用 Hadoop 并行计算框架的优势和能力,来处理大数据。而我们在官方文档或者是Hadoop权威指南看到的Hadoop Streaming例子都是使用 Ruby 或者 Python 编写的,官方说可以使用任何可执行文件 w397090770 8年前 (2017-03-14) 2700℃ 0评论2喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第五篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 zz~~ 8年前 (2016-10-01) 3833℃ 0评论6喜欢
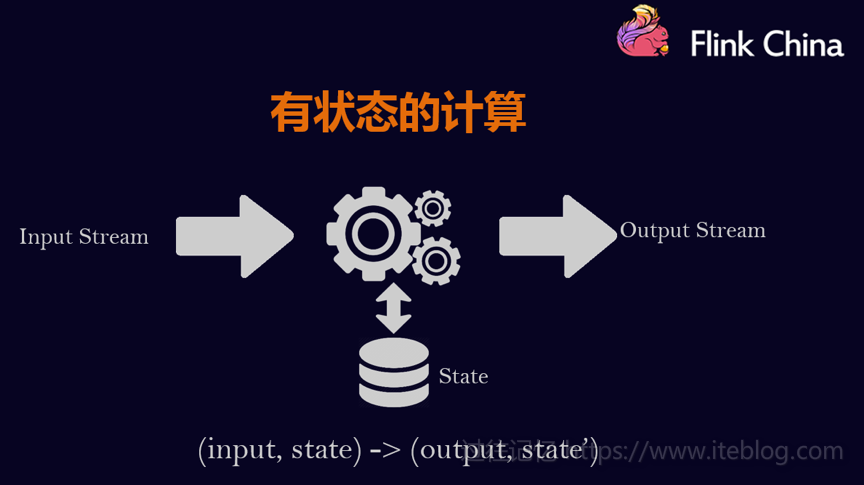
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9091℃ 0评论21喜欢
Apache Hudi 对个人和组织何时有用如果你希望将数据快速提取到HDFS或云存储中,Hudi可以提供帮助。另外,如果你的ETL /hive/spark作业很慢或占用大量资源,那么Hudi可以通过提供一种增量式读取和写入数据的方法来提供帮助。作为一个组织,Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快 w397090770 5年前 (2019-12-23) 1870℃ 0评论2喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3368℃ 0评论9喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 719℃ 0评论1喜欢
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 5年前 (2019-11-26) 1575℃ 0评论4喜欢
本资料来自2021年12月09日举办的 PrestoCon 2021,标题为《Presto at Tencent at Scale: Usability Extension, Stability Improvement and Performance Optimization》Presto 在腾讯内部为不同业务部门提供临时查询(ad-hoc queries)和交互式查询( interactive queries)场景。在这次演讲中,我们将分享腾讯在生产中的实践。并且将讨论腾讯在 Presto 上面的工作,以进一步 w397090770 3年前 (2021-12-08) 351℃ 0评论0喜欢
Apache Kafka 3.0 于2021年9月21日正式发布。本文将介绍这个版本的新功能。以下文章翻译自 《What's New in Apache Kafka 3.0.0》。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据我很高兴地代表 Apache Kafka® 社区宣布 Apache Kafka 3.0 的发布。 Apache Kafka 3.0 是一个大版本,其引入了各种新功能、API 发生重 w397090770 3年前 (2021-09-24) 568℃ 0评论2喜欢
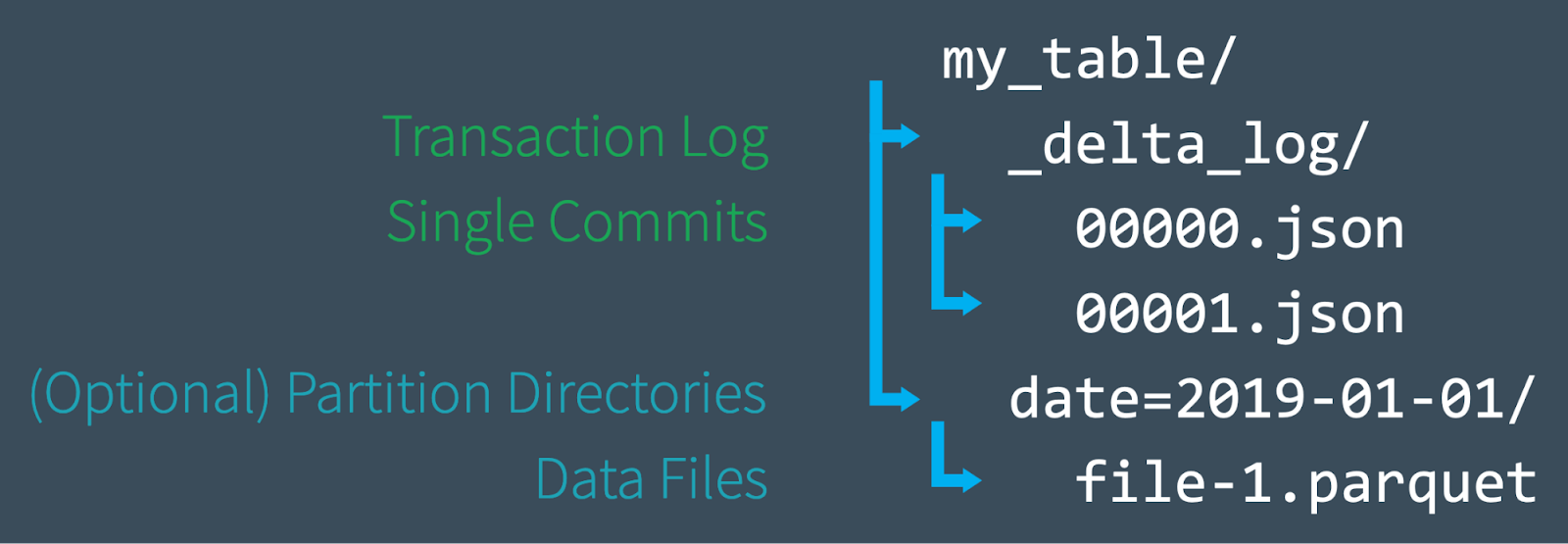
Delta Lake 支持 DML 命令,包括 DELETE, UPDATE, 以及 MERGE,这些命令简化了 CDC、审计、治理以及 GDPR/CCPA 工作流等业务场景。在这篇文章中,我们将演示如何使用这些 DML 命令,并会介绍这些命令的后背实现,同时也会介绍对应命令的一些性能调优技巧。Delta Lake: 基本原理如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 w397090770 4年前 (2020-10-12) 1438℃ 0评论0喜欢
Presto 是由 Facebook 开发并开源的分布式 SQL 交互式查询引擎,很多公司都是用它实现 OLAP 业务分析。本文列出了 Presto 常用的函数列表。数学函数数学函数作用于数学公式。下表给出了详细的数学函数列表。abs(x)返回 x 的绝对值。使用如下:[code lang="bash"]presto:default> select abs(1.23) as absolute; absolute ---------- 1.23[/code] w397090770 3年前 (2021-10-07) 5722℃ 0评论1喜欢
最近由Reynold Xin给Spark开发者发布的一封邮件透露,Spark社区很有可能会跳过Spark 1.7版本的发布,而直接转向Spark 2.x。 如果Spark 2.x发布,那么它将: (1)、Spark编译将默认使用Scala 2.11,但是还是会支持Scala 2.10。 (2)、移除对Hadoop 1.x的支持。不过也有可能移除对Hadoop 2.2以下版本的支持,因为Hadoop 2.0和2.1版本分 w397090770 9年前 (2015-11-13) 6983℃ 0评论16喜欢
在《Zookeeper 3.4.5分布式安装手册》、《Hadoop2.2.0完全分布式集群平台安装与设置》文章中,我们已经详细地介绍了如何搭建分布式的Zookeeper、Hadoop等平台,今天,我们来说说如何在Hadoop、Zookeeper上搭建完全分布式的Hbase平台。这里同样选择目前最新版的Hbase用于配合最新版的Hadoop-2.2.0,所以我们选择了Hbase-0.96.0。 1、下载并解压HB w397090770 11年前 (2014-01-19) 11165℃ 6评论1喜欢
本页面不再更新,请移步到 《2018 最新 hosts 文件持续更新》如果之前的hosts文件还有效可以不更新;由于大家使用的带宽种类,地区,被墙的程度不一样,所以有些地区使用本Hosts文件可能仍然无法使用Google;光靠修改Hosts文件是无法观看youtube里面的视频,重要的事说三遍:通过本hosts文件可以打开youtube网站,但是无法观看 w397090770 9年前 (2015-09-25) 194025℃ 376喜欢
如果你使用Apache Spark解决了中等规模数据的问题,但是在海量数据使用Spark的时候还是会遇到各种问题。High Performance Spark将会向你展示如何使用Spark的高级功能,所以你可以超越新手级别。本书适合软件工程师、数据工程师、开发者以及Spark系统管理员的使用。本书全名High Performance Spark:Best Practices for Scaling and Optimizing Apache Spark,作 w397090770 7年前 (2017-06-23) 10613℃ 0评论19喜欢
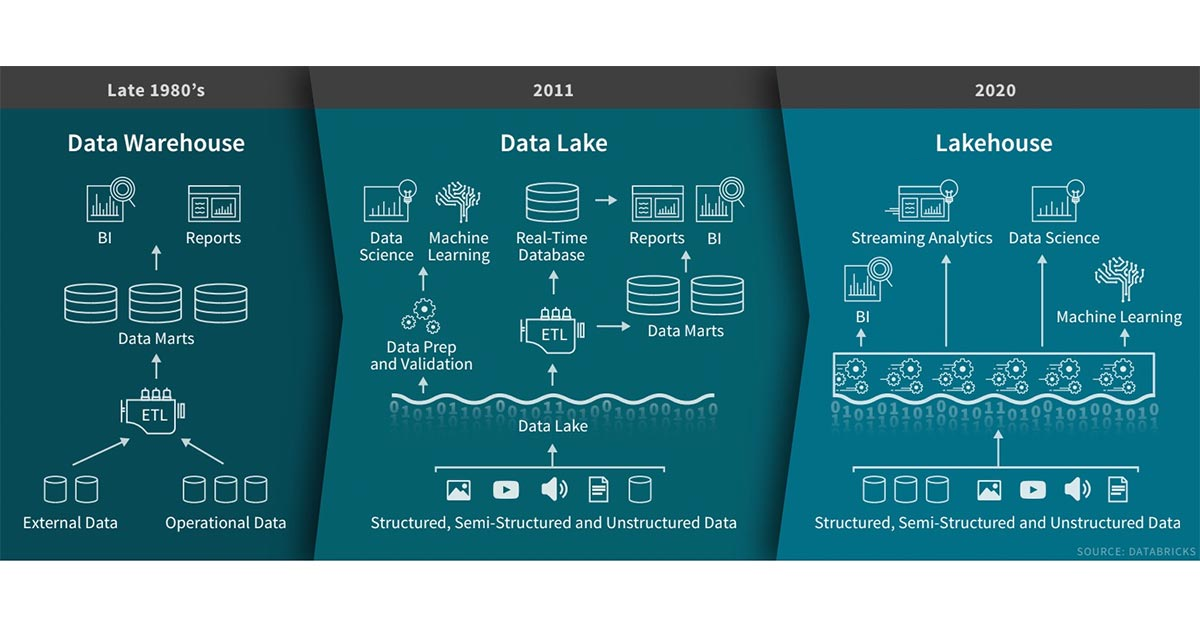
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3002℃ 0评论6喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》本博客收集到的Hadoop学习书籍分享地 w397090770 11年前 (2014-02-14) 202547℃ 5评论421喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 第三次北京Spark Meetup活动将于2014年10月26日星期日的下午1:30到6:00在海淀区中关村科学院南路2号融科资讯中心A座8层举行,本次分享的主题主要是MLlib与分布式机器学 w397090770 10年前 (2014-10-09) 4463℃ 6评论6喜欢
本文来自 恩爸 的文章,原文地址:https://blog.csdn.net/zzcclp/article/details/80161130前言一个偶然的机会,从某Spark微信群知道了CarbonData,从断断续续地去了解,到测试 1.2 版本,再到实际应用 1.3 版本的流式入库,也一年有余,在这期间,得到了 CarbonData 社区的陈亮,李昆,蔡强等大牛的鼎力支持,自己也从认识CarbonData 到应用 Carbo w397090770 6年前 (2018-05-02) 2747℃ 0评论7喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 10年前 (2014-09-08) 18320℃ 177评论16喜欢
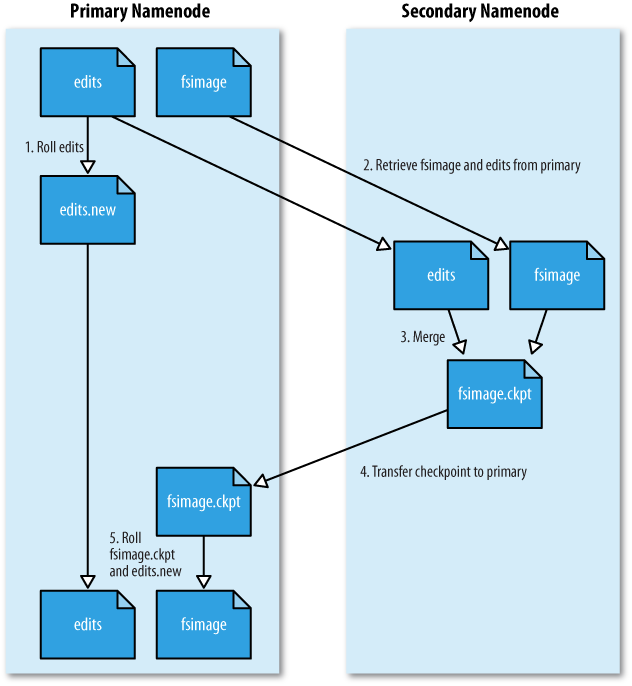
在《Hadoop文件系统元数据fsimage和编辑日志edits》文章中谈到了fsimage和edits的概念、作用等相关知识,正如前面说到,在NameNode运行期间,HDFS的所有更新操作都是直接写到edits中,久而久之edits文件将会变得很大;虽然这对NameNode运行时候是没有什么影响的,但是我们知道当NameNode重启的时候,NameNode先将fsimage里面的所有内容映像到 w397090770 11年前 (2014-03-10) 9758℃ 2评论18喜欢
Apache Spark 1.5版本目前正在社区投票中,相信到9月初应该会发布。这里先剧透一下Apache Spark 1.5版本的一些重要的修改和Bug修复。Apache Spark 1.5有来自220多位贡献者的1000多个commits。这里仅仅是列出重要的修改和Bug修复,详细的还请参见Apache JIRA changelog.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:itebl w397090770 9年前 (2015-08-26) 2904℃ 0评论6喜欢
在过去Spark社区创建了Spark 2.0的技术预览版,经过几天的投票,目前该技术预览版今天正式公布。《Spark 2.0技术预览:更容易、更快速、更智能》文章中详细介绍了Spark 2.0给我们带来的新功能,总体上Spark 2.0提升了下面三点: 1. 对标准的SQL支持,统一DataFrame和Dataset API。现在已经可以运行TPC-DS所有的99个查询,这99个查 w397090770 8年前 (2016-05-25) 2620℃ 0评论3喜欢
Apache Flink 1.1.3仍然在Flink 1.1系列基础上修复了一些Bug,推荐所有用户升级到Flink 1.1.3,只需要在你相关工程的pom.xml文件里面加入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>1.1.3</version></dependency><dependency> <groupId>org.apache w397090770 8年前 (2016-10-16) 1582℃ 0评论5喜欢
第十二次Shanghai Apache Spark Meetup聚会,由Splunk中国大力支持。活动将于2017年03月18日12:30~16:45在上海淞沪路303号901 (大学路智星路路口汇丰银行楼9楼)Splunk 中国进行。 举办地点交通方便,靠近地铁10号线江湾体育场站,座位有限(大约120),先到先得,速速行动啊。大会主题《利用Spark开发高并发,高可靠的分布式大数据采集调 w397090770 8年前 (2017-03-09) 1441℃ 0评论2喜欢
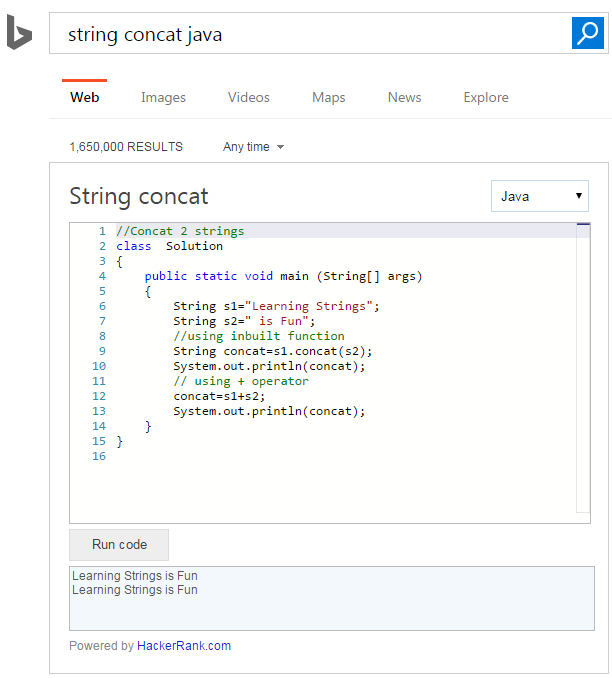
微软的搜索引擎Bing和HackerRank合作,在Bing的搜索结果里面加入了实时代码编辑器,它为数以百万计的程序员提供了一种简单的方法来搜索结果,主要是允许程序员在搜索结果中直接编辑和执行代码示例,实时查看运行结果。 通常情况下,工程师需要到Stackoverflow, Stackexchange或者其他的博客搜索他们需要的答案。现在我们有 w397090770 9年前 (2016-04-11) 1789℃ 0评论2喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 9年前 (2015-11-06) 7963℃ 0评论9喜欢



![Spark Summit 2016 San Francisco PPT免费下载[共95个]](https://www.iteblog.com/pic/iteblog.png)




![最新可访问Google的Hosts文件[最新更新]](https://www.iteblog.com/pic/host.jpg)
![[电子书]High Performance Spark完整版PDF下载](https://www.iteblog.com/pic/books/High_Performance_Spark_iteblog.jpg)
![传智播客Hadoop课程视频资料[共七天]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/9.jpg)