本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 854℃ 0评论3喜欢
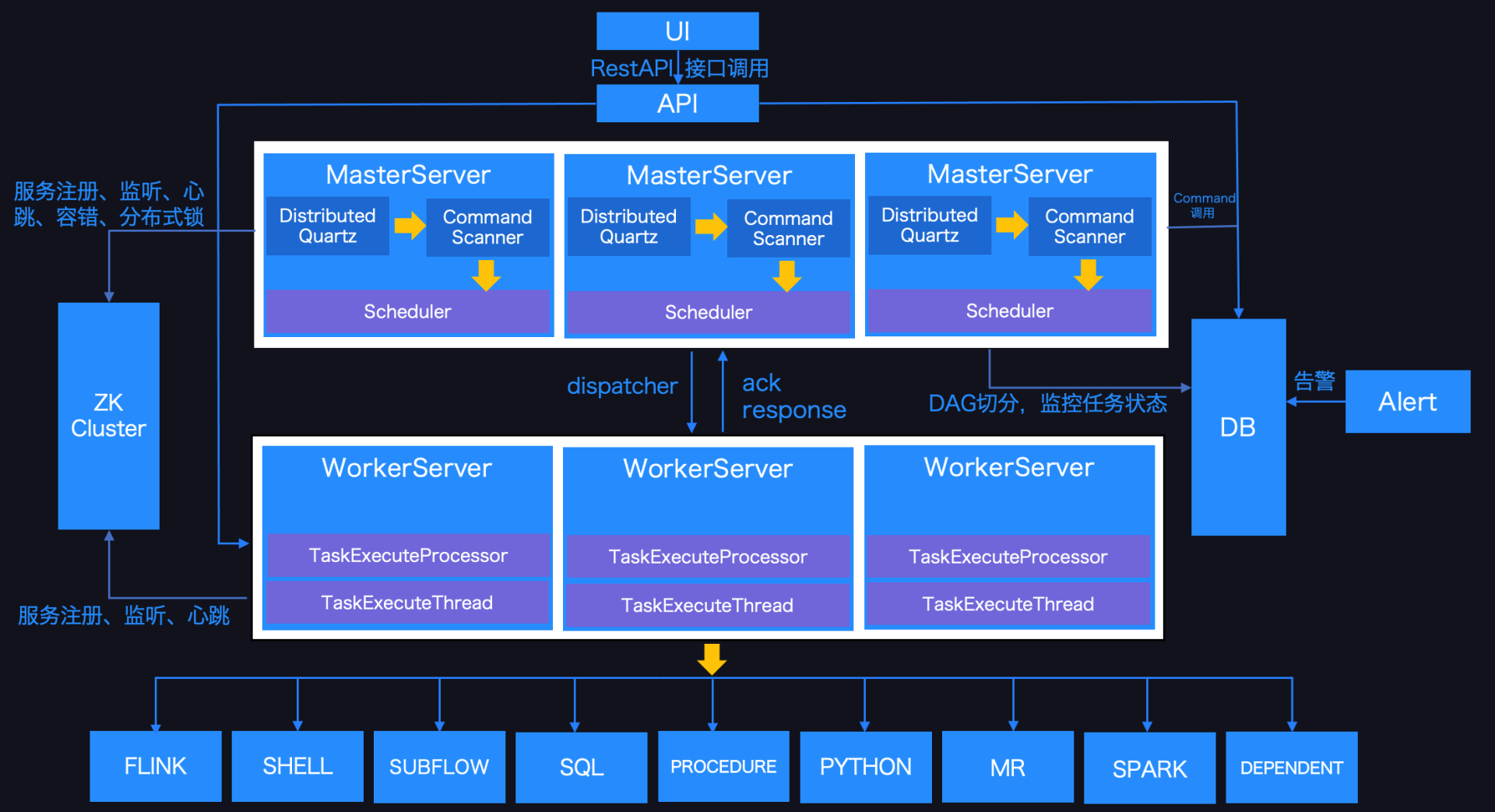
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 4年前 (2021-04-09) 1821℃ 0评论3喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11307℃ 6评论29喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 8年前 (2016-06-15) 3368℃ 0评论9喜欢
我们在 前面的文章文章中介绍了 Docker 默认是从 https://hub.docker.com/仓库下载镜像的,由于这个网址是国外的,所以在下载镜像的时候很可能会非常慢,所以大家应该想到 Docker 是否像 Maven 仓库一样也有一些国内的 Docker 镜像库呢?答案是肯定的。截止到本文撰写的时候,下面几个国内 Docker 镜像地址是可用的:网易 Docker 镜像库:h w397090770 5年前 (2020-02-03) 11325℃ 0评论4喜欢
求解问题如下:在本地磁盘里面有file1和file2两个文件,每一个文件包含500万条随机整数(可以重复),最大不超过2147483648也就是一个int表示范围。要求写程序将两个文件中都含有的整数输出到一个新文件中。要求: 程序的运行时间不超过5秒钟。 没有内存泄漏。 代码规范,能要考虑到出错情况。 代码具有高度可重用性 w397090770 12年前 (2013-04-03) 6912℃ 3评论5喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 下面是Spark meetup(Beijing)第 w397090770 10年前 (2014-08-29) 23964℃ 204评论16喜欢
本书是《Spark快速数据处理》第三版,全书基于Spark 2.0.0编写。本书适合Spark入门者,作者Krishna Sankar,由Packt出版社于2016年10月出版,全书共274页。通过本书你将学到以下知识: (1)、安装和设置你的Spark集群; (2)、使用Spark交互式Shell来实现简单的分布式应用程序; (3)、使用新的DataFrame API操作数据; w397090770 8年前 (2016-12-14) 4376℃ 0评论5喜欢
在即将发布的Apache Spark 2.0中将会提供机器学习模型持久化能力。机器学习模型持久化(机器学习模型的保存和加载)使得以下三类机器学习场景变得容易: 1、数据科学家开发ML模型并移交给工程师团队在生产环境中发布; 2、数据工程师把一个Python语言开发的机器学习模型训练工作流集成到一个Java语言开发的机器 w397090770 8年前 (2016-06-04) 3482℃ 3评论3喜欢
这篇文章中将介绍C# 6.0的一个新特性,这将加深我们对Scala monad的理解。Null-conditional操作符 假如我们有一个嵌套的数据类型,然后我们需要访问这个嵌套类型里面的某个属性。比如Article可以没有作者(Author)信息;Author可以没有Address信息;Address可以没有City信息,如下:[code lang="csharp"]//////////////////////////////////// w397090770 9年前 (2016-02-24) 2137℃ 0评论6喜欢
Apache HBase 1.2.1 于2016-04-12正式发布了,HBase 1.2.1是HBase 1.2.z版本线上的第一个维护版本,该版本的主题仍然是为Hadoop和NoSQL社区带来稳定和可靠的数据库。此版本在1.2.0版本上解决了27个issues。主要的Bug修改* [HBASE-15441] - Fix WAL splitting when region has moved multiple times* [HBASE-15219] - Canary tool does not return non-zero exit code when w397090770 9年前 (2016-04-14) 3125℃ 0评论2喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列的介 w397090770 8年前 (2016-07-14) 7590℃ 2评论4喜欢
北京第十次Spark Meetup活动于北京时间2016年03月27日在北京市海淀区丹棱街5号微软亚太研发集团总部大厦1号楼进行。活动内容如下:1. Spark in TalkingData,阎志涛.TalkingData研发副总裁2. Spark in GrowingIO,田毅,GrowingIO数据平台工程师,主要分享GrowingIO使用Spark进行数据处理过程中的各种小技巧,包括:多数据源的访问和使用Bitmap进行 w397090770 9年前 (2016-03-28) 2119℃ 0评论4喜欢
当前 velox 支持了 HDFS、S3 以及本地文件系统,其中 HDFS 和 S3 模块是需要在编译的时候显示指定的,比如我们要测试 HDFS 功能,编译 prestissimo 的时候需要显示指定 PRESTO_ENABLE_HDFS=ON,如下:[code lang="bash"]PRESTO_ENABLE_HDFS=ON make release[/code]Velox 解析 HDFS NN endpoint 逻辑核心代码如下:[code lang="CPP"]HdfsServiceEndpoint HdfsFileSystem::getServic w397090770 1年前 (2023-06-29) 609℃ 0评论3喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP w397090770 9年前 (2015-05-13) 46383℃ 0评论0喜欢
《Kafka: The Definitive Guide, 2nd Edition》于 2021年11月由 O'Reilly Media 出版, ISBN 为 9781492043089 ,全书 486 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍Every enterprise application creates data, whether it consists of log messages, metrics, user activity, or outgoing messages. Moving all this data is just as important as the w397090770 3年前 (2022-03-22) 1176℃ 0评论4喜欢
Flink China社区线下 Meetup·上海站会议于 2018年7月29日 在上海市杨浦区政学路77号INNOSPACE进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程14:00-14:10 大沙 出品人开场发言14:10-14:40 阿里 巴真 《阿里在Flink的优化和改进分享》14:40-15:10 唯品会 王新春 《Flink在唯品会的实践》详细 w397090770 6年前 (2018-08-13) 2323℃ 0评论5喜欢
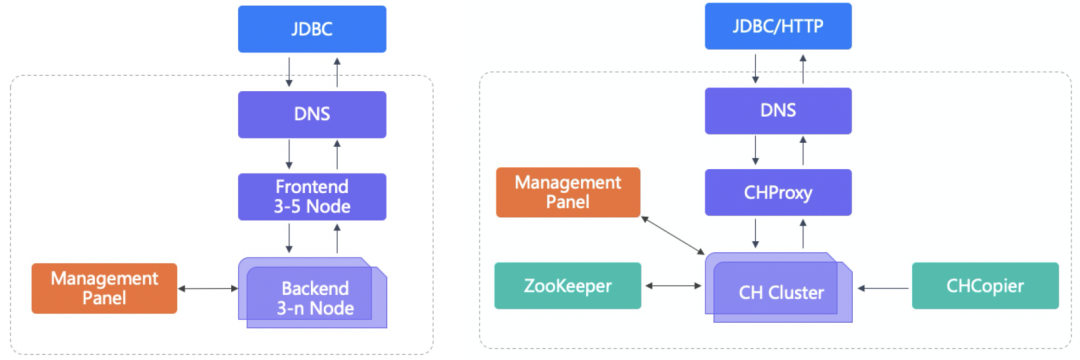
背景介绍Apache Doris是由百度贡献的开源MPP分析型数据库产品,亚秒级查询响应时间,支持实时数据分析;分布式架构简洁,易于运维,可以支持10PB以上的超大数据集;可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。 ClickHouse 是俄罗斯的搜索公司Yadex开源的MPP架构的分析引 w397090770 3年前 (2022-02-15) 2727℃ 0评论1喜欢
在使用Hadoop的时候,一般配置SSH使得我们可以无密码登录到主机,下面分别以Ubuntu和CentOS两个平台来举例说明如何配置SSH使得我们可以无密码登录到主机,当然,你得先安装好SSH服务器,并开启(关于如何在Linux平台下安装好SSH请参加本博客的《Linux平台下安装SSH》)在 Ubuntu 平台设置 SSH 无秘钥登录Ubuntu配置步骤如下所示:[c w397090770 11年前 (2013-10-24) 7786℃ 4评论3喜欢
相关文章:《Apache Flink 1.1.0和1.1.1发布,支持SQL》 Apache Flink 1.1.2于2016年09月05日正式发布,此版本主要是修复一些小bug,推荐所有使用Apache Flink 1.1.0以及Apache Flink 1.1.1的用户升级到此版本,我们可以在pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</a zz~~ 8年前 (2016-09-06) 1350℃ 0评论1喜欢
以下的话是由Apache Spark committer的Reynold Xin阐述。 从很多方面来讲,Spark都是MapReduce 模式的最好实现。比如从程序抽象的角度来看: 1、他抽象出Map/Reduce两个阶段来支持tasks的任意DAG。大多数计算通过依赖将maps和reduces映射到一起(Most computation maps (no pun intended) into many maps and reduces with dependencies among them. )。而在Spark的RDD w397090770 10年前 (2015-03-09) 8073℃ 0评论9喜欢
《Kafka in Action》于 2022年01月由 Manning 出版, ISBN 为 9781617295232 ,全书 272 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍作者有多年使用 Kafka 的真实世界的经验,这本书的实地感觉真的让它与众不同。---- From the foreword by Jun Rao, Confluent CofounderMaster the wicked-fast Apache Kafka streaming w397090770 3年前 (2022-03-02) 589℃ 0评论3喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 第三次北京Spark Meetup活动 w397090770 10年前 (2014-11-06) 15632℃ 134评论11喜欢
一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3146℃ 0评论1喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 8年前 (2017-02-23) 2561℃ 0评论1喜欢
1、新增"Explain dependency"语法,以json格式输出执行语句会读取的input table和input partition信息,这样debug语句会读取哪些表就很方便了[code lang="JAVA"]hive> explain dependency select count(1) from p;OK{"input_partitions":[{"partitionName":"default@p@stat_date=20110728/province=bj"},{"partitionName":"default@p@stat_date=20110728/provinc w397090770 11年前 (2013-11-04) 7532℃ 2评论4喜欢
到这个页面(https://hub.docker.com/_/centos?tab=tags)查看自己要下载的 Centos 版本:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop将指定版本的 CentOS 镜像拉到本地在本地使用下面命令进行拉取:[code lang="bash"][iteblog@iteblog.com]$ docker pull centos:centos7centos7: Pulling from library/centos6717b8ec66cd: Pull comp w397090770 3年前 (2021-10-17) 140℃ 0评论1喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 9年前 (2016-03-30) 16296℃ 0评论10喜欢
在《Zookeeper 3.4.5分布式安装手册》、《Hadoop2.2.0完全分布式集群平台安装与设置》文章中,我们已经详细地介绍了如何搭建分布式的Zookeeper、Hadoop等平台,今天,我们来说说如何在Hadoop、Zookeeper上搭建完全分布式的Hbase平台。这里同样选择目前最新版的Hbase用于配合最新版的Hadoop-2.2.0,所以我们选择了Hbase-0.96.0。 1、下载并解压HB w397090770 11年前 (2014-01-19) 11165℃ 6评论1喜欢
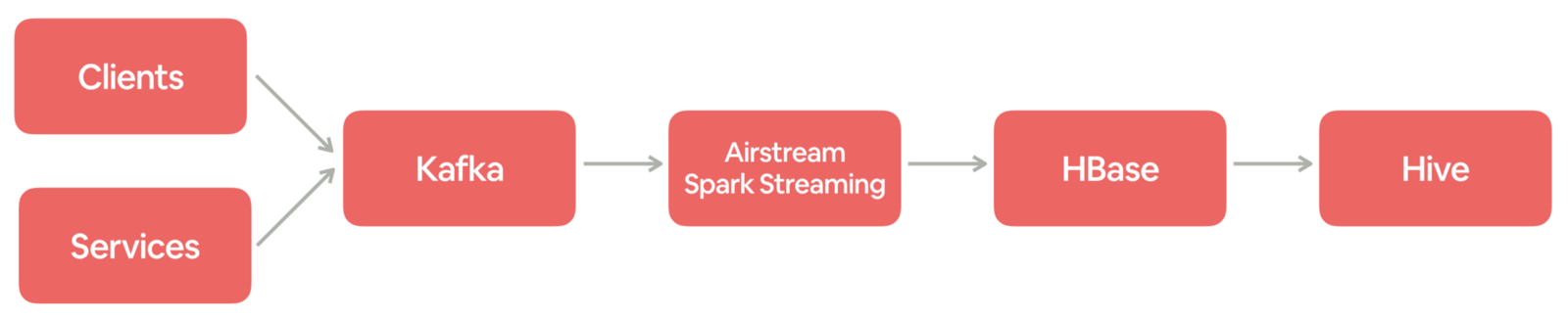
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 5年前 (2019-05-19) 2860℃ 0评论8喜欢

![Spark Summit 2016 San Francisco PPT免费下载[共95个]](https://www.iteblog.com/pic/iteblog.png)



![[电子书]Fast Data Processing with Spark 2, 3rd Edition下载](https://www.iteblog.com/pic/books/Fast_Data_Processing_with_Spark_2_iteblog.jpg)