在本文中,我将介绍八个基本的 Docker 容器命令,这些命令对于在 Docker 容器上执行基本操作很有用,比如运行,列表,停止,查看日志,删除等等。如果你对 Docker 的概念不熟悉,推荐你推荐你到网上查看相关的入门介绍,这篇文章就不详细介绍了。 现在我们赶快进入要了解的命令中:如果想及时了解Spark、Hadoop或者HBase相关的 w397090770 6年前 (2018-06-27) 1875℃ 0评论6喜欢
导读:向量化技术带来极致的CPU效率的同时,也已经成为了软件开发的趋势,而数据库的向量化不仅仅是 CPU 指令的向量化,还是一个巨大的性能优化工程。本文从CPU向量化原理出发,通过Cache、虚函数、SIMD等方面讨论CPU的性能优化,介绍了Apache Doris现有列存行式计算结构向列存列式计算结构的转变,同时展示了目前Apache D w397090770 3年前 (2022-03-01) 1215℃ 0评论3喜欢
Apache HBase 1.3.0于美国时间2017年01月17日正式发布。本版本是Hbase 1.x版本线的第三次小版本,大约解决了1700个issues,主要包括了大量的Bug修复和性能提升;其中以下的新特性值得关注:Date-based tiered compactions (HBASE-15181, HBASE-15339)Maven archetypes for HBase client applications (HBASE-14877)Throughput controller for flushes (HBASE-14969)Controlled delay (CoD w397090770 8年前 (2017-01-18) 3437℃ 0评论3喜欢
Linux(vi/vim)一般模式语法功能描述yy复制光标当前一行y数字y复制一段(从第几行到第几行)p箭头移动到目的行粘贴u撤销上一步dd删除光标当前行d数字d删除光标(含)后多少行x删除一个字母,相当于delX删除一个字母,相当于Backspaceyw复制一个词dw删除一个词 zz~~ 3年前 (2021-12-01) 171℃ 0评论0喜欢
本书于2014年12月出版,共374页,这里提供的本身完整版。 w397090770 9年前 (2015-08-21) 2631℃ 0评论3喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 482℃ 0评论1喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 763℃ 0评论1喜欢
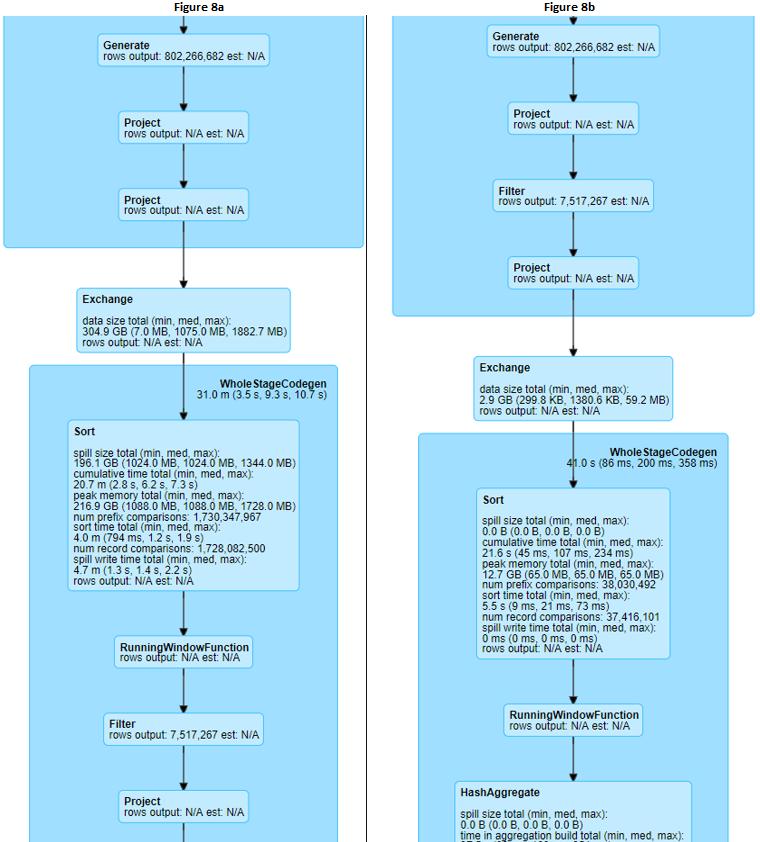
在本文中,我将分享一些关于如何编写可伸缩的 Apache Spark 代码的技巧。本文提供的示例代码实际上是基于我在现实世界中遇到的。因此,通过分享这些技巧,我希望能够帮助新手在不增加集群资源的情况下编写高性能 Spark 代码。背景我最近接手了一个 notebook ,它主要用来跟踪我们的 AB 测试结果,以评估我们的推荐引擎的性能 w397090770 5年前 (2019-11-26) 1581℃ 0评论4喜欢
《Spark Streaming作业提交源码分析接收数据篇》、《Spark Streaming作业提交源码分析数据处理篇》 最近一段时间在使用Spark Streaming,里面遇到很多问题,只知道参照官方文档写,不理解其中的原理,于是抽了一点时间研究了一下Spark Streaming作业提交的全过程,包括从外部数据源接收数据,分块,拆分Job,提交作业全过程。 w397090770 10年前 (2015-04-28) 9201℃ 2评论9喜欢
Presto 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体 w397090770 2年前 (2022-06-23) 1621℃ 0评论3喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-06-06) 30664℃ 40评论6喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 w397090770 8年前 (2017-02-09) 1973℃ 0评论1喜欢
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 在本博客的《Spark Streaming和Kafka整合开发指南(一)》文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据。本文将介绍如何使用Spark 1.3.0引入的Direct API从Kafka中读数据。 和基于Receiver接收数据不一样,这种方式 w397090770 10年前 (2015-04-21) 28423℃ 1评论26喜欢
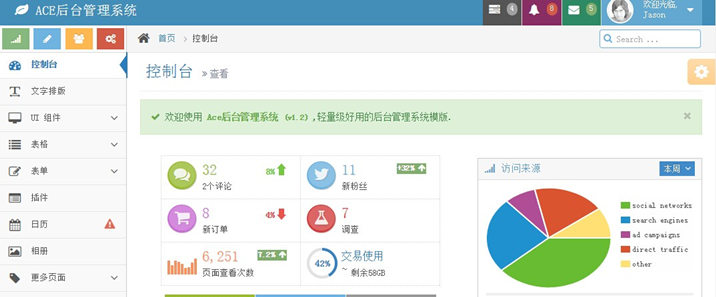
最近一段时间在做一个管理系统,在网上找了很久的前端展示框架,终于找到一款基于Bootstrap的后台管理系统模版:Ace。Bootstrap是Twitter 于2010年开发出来的前端框架,用过的同学应该知道,这款前端框架不仅界面很美观,而且兼容了很多的浏览器,大大加速了我们开发网站的速度!这篇文章讲到的Ace是基于Bootstrap的,所以界面自然 w397090770 10年前 (2015-01-19) 172272℃ 15评论459喜欢
我们在《Apache Cassandra 简介》文章中介绍了 Cassandra 的数据模型类似于 Google 的 Bigtable,对应的开源实现为 Apache HBase,而且我们在 《HBase基本知识介绍及典型案例分析》 文章中简单介绍了 Apache HBase 的数据模型。按照这个思路,Apache Cassandra 的数据模型应该和 Apache HBase 的数据模型很类似,那么这两者的数据存储模型是不是一样的呢? w397090770 6年前 (2019-04-28) 1768℃ 0评论4喜欢
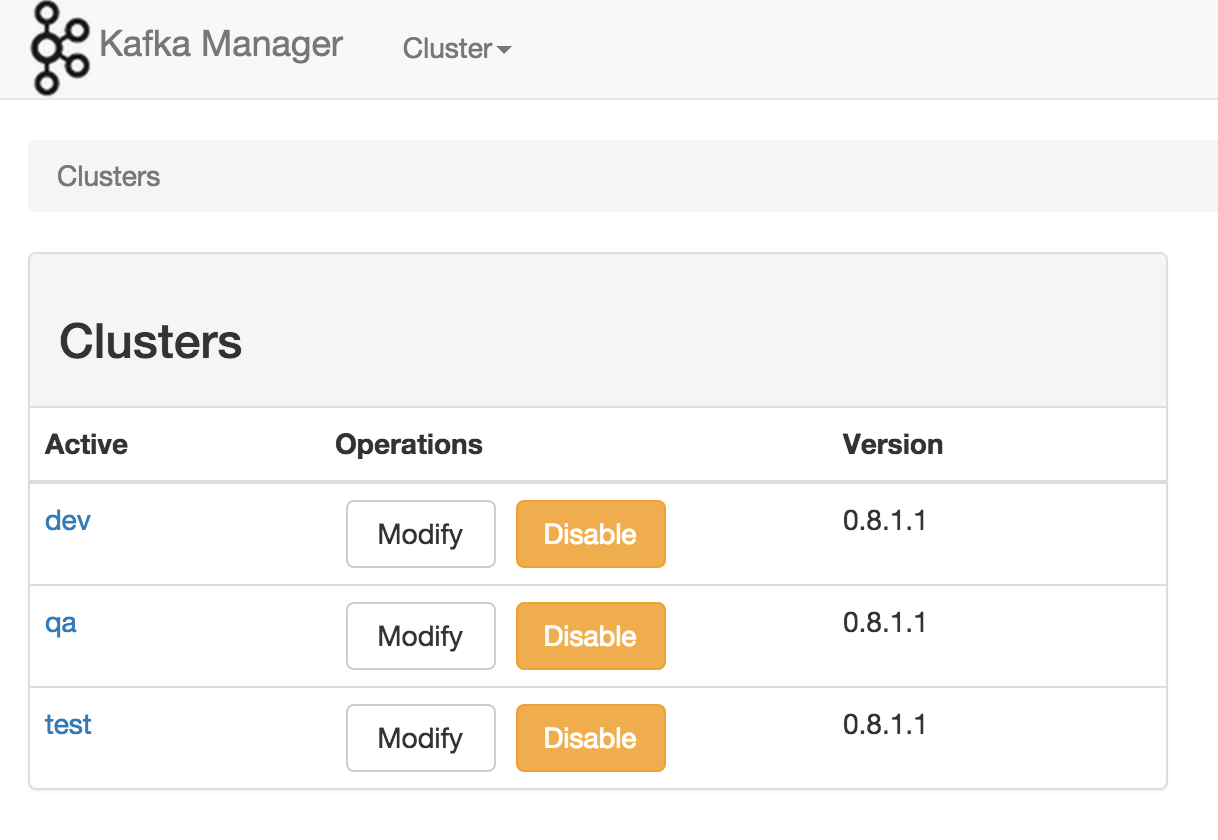
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka M w397090770 10年前 (2015-02-04) 22097℃ 0评论14喜欢
大家对加州大学伯克利分校的AMPLab可能不太熟悉,但是它的项目我们都有所耳闻——没错,它就是Spark和Mesos的诞生之地。AMPLab是加州大学伯克利分校一个为期五年的计算机研究计划,其初衷是为了理解机器和人如何合作处理和解决数据中的问题——使用数据去训练更加丰富的模型,有效的数据清理,以及进行可衡量的数据扩展。 w397090770 8年前 (2017-02-09) 1334℃ 0评论3喜欢
时隔两年,Apache Hadoop终于又有大改版,Apache基金会近日发布了Hadoop 2.8版,一次新增了2,919项更新功能或新特色。不过,Hadoop官网建议,2.8.0仍有少数功能在测试,要等到释出2.8.1或是2.8.2版才适合用于正式环境。在2.8.0版众多更新,主要分布于4大套件分别是:共用套件(Common)底层分散式档案系统HDFS套件(HDFS)MapReduce运算 w397090770 8年前 (2017-03-31) 2814℃ 2评论17喜欢
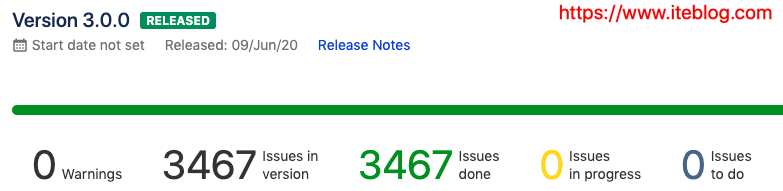
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 4年前 (2020-06-18) 1836℃ 0评论4喜欢
这几天由于项目的需要,需要将Flume收集到的日志插入到Hbase中,有人说,这不很简单么?Flume里面自带了Hbase sink,可以直接调用啊,还用说么?是的,我在本博客的《Flume-1.4.0和Hbase-0.96.0整合》文章中就提到如何用Flume和Hbase整合,从文章中就看出整个过程不太复杂,直接做相应的配置就行了。那么为什么今天还要特意提一下Flum w397090770 11年前 (2014-01-27) 5148℃ 1评论1喜欢
本博客前两篇文章介绍了如何在脚本中使用Scala(《在脚本中运行Scala》、《在脚本中使用Scala的高级特性》),我们可以在脚本里面使用Scala强大的语法,但细心的同学可能会发现每次运行脚本的时候会花上一大部分时间,然后才会有结果。我们来测试下面简单的Scala脚本:[code lang="shell"]#!/bin/shexec scala "$0" "$@" w397090770 9年前 (2015-12-17) 4749℃ 0评论8喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 3年前 (2021-07-31) 475℃ 0评论4喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展方向奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一 w397090770 9年前 (2016-05-24) 13079℃ 0评论26喜欢
在使用 Presto 时,我们经常会听说 Query、Stage、Task 等概念,很多人会搞不清楚这些概念,所以会导致一些误解,本文将简单地介绍一下这些基本的概念是指StatementStatement语句。其实就是指我们输入的SQL语句。Presto支持需要ANSI标准的SQL语句。这种语句由子句(Clause)、表达式(Expression)和断言(Predicate)组成。Presto为什么将语句(S w397090770 3年前 (2021-11-01) 1921℃ 0评论4喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 8年前 (2017-06-01) 2598℃ 1评论10喜欢
一、百度(武汉地区)第一部分:1、描述数据库的简单操作。2、描述TCP\IP四层模型,并简述之。3、描述MVC的内容。第二部分:1、给出a-z0-9,在其中选择三个字符组成一个密码,输出全部的情况,程序实现。2、字符串的反转,比如abcde,输出edcba.3、许多程序会大量使用字符串。对于不同的字符串,我们希望能够 w397090770 12年前 (2013-04-15) 13409℃ 0评论9喜欢
在本博客的《Apache Kafka-0.8.1.1源码编译》文章中简单地谈到如何用gradlew或sbt编译Kafka 0.8.1.1的代码。今天主要来谈谈如何部署一个分布式集群。以下本文所有的内容都是基于Kafka 0.8.1.1(Kafka 0.7.x的操作命令和本文略有不同,请注意!)在介绍Kafka分布式部署之前,先来了解一下Kafka的基本概念。 (1)Kafka维护按类区分的消息 w397090770 11年前 (2014-06-25) 9181℃ 0评论5喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 w397090770 4年前 (2020-11-12) 5793℃ 0评论9喜欢
在C++中一共有四种强制类型转换:dynamic_cast、const_cast 、static_cast、reinterpret_cast。除了dynamic_cast是在运行的时候进行类型转换的,其它三种都是在编译期间实现转换的。四种类型的转换介绍如下: dynamic_cast:只能在继承类对象的指针之间或引用之间进行类型转换,进行转换时,会根据对象的运行时类型信息,判断类型对象之间的 w397090770 12年前 (2013-04-04) 3241℃ 0评论2喜欢
从本质上说,fold函数将一种格式的输入数据转化成另外一种格式返回。fold, foldLeft和foldRight这三个函数除了有一点点不同外,做的事情差不多。我将在下文解释它们的共同点并解释它们的不同点。 我将从一个简单的例子开始,用fold计算一系列整型的和。[code lang="scala"]val numbers = List(5, 4, 8, 6, 2)numbers.fold(0) { (z, i) => w397090770 10年前 (2014-12-17) 36106℃ 0评论42喜欢