刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 w397090770 4年前 (2020-12-09) 1084℃ 0评论7喜欢
《Spark Python API函数学习:pyspark API(1)》 《Spark Python API函数学习:pyspark API(2)》 《Spark Python API函数学习:pyspark API(3)》 《Spark Python API函数学习:pyspark API(4)》 Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pyspark API。.wp-caption img{ max-width: 100%; height: auto;}如果想 w397090770 9年前 (2015-06-28) 36645℃ 0评论78喜欢
Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3363℃ 0评论7喜欢
Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始,Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro Data Source for Apache Spark。除此之外,它还提供以下功能:新函数 from_avro() 和 to_avro() w397090770 6年前 (2018-12-11) 3106℃ 0评论9喜欢
本文来自7月26日在上海举行的 Flink Meetup 会议,分享来自于刘康,目前在大数据平台部从事模型生命周期相关平台开发,现在主要负责基于flink开发实时模型特征计算平台。熟悉分布式计算,在模型部署及运维方面有丰富实战经验和深入的理解,对模型的算法及训练有一定的了解。本文主要内容如下:在公司实时特征开发的现 zz~~ 6年前 (2018-08-14) 7392℃ 0评论3喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 w397090770 4年前 (2021-02-02) 632℃ 0评论3喜欢
在 Zookeeper 中限制 transaction log 总大小主要有两种方法。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop限制 Zookeeper Transaction Log 里面的事务条数默认情况下,在写入 snapCount(100000) 事务后,Zookeeper 事务日志将会切换。如果 Zookeeper 的数据目录的空间不足与存储三个版本的 Zookeeper Transaction Lo w397090770 4年前 (2020-10-28) 737℃ 0评论1喜欢
《Spark Python API函数学习:pyspark API(1)》 《Spark Python API函数学习:pyspark API(2)》 《Spark Python API函数学习:pyspark API(3)》 《Spark Python API函数学习:pyspark API(4)》 Spark支持Scala、Java以及Python语言,本文将通过图片和简单例子来学习pyspark API。.wp-caption img{ max-width: 100%; height: auto;}如果想 w397090770 9年前 (2015-07-04) 21809℃ 0评论19喜欢
使用MapReduce解决任何问题之前,我们需要考虑如何设计。并不是任何时候都需要map和reduce job。MapReduce设计模式(MapReduce Design Pattern)整个MapReduce作业的阶段主要可以分为以下四种: 1、Input-Map-Reduce-Output 2、Input-Map-Output 3、Input-Multiple Maps-Reduce-Output 4、Input-Map-Combiner-Reduce-Output下面我将一一介绍哪种 w397090770 8年前 (2016-09-01) 5717℃ 0评论16喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11307℃ 6评论29喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 11年前 (2013-07-11) 4669℃ 0评论1喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-15) 19376℃ 5评论10喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive w397090770 8年前 (2017-02-27) 3033℃ 0评论5喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 8年前 (2016-07-25) 216066℃ 0评论844喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4361℃ 0评论10喜欢
在编写程序的时候,很多时候都需要检查输入的参数是否符合我们的需要,比如人的年龄需要大于0,名字不能为空;如果不符合这两个要求,我们将认为这个对象是不合法的,这时候我们需要编写判断这些参数是否合法的函数,我们可能这样写:[code lang="JAVA"]package com.wyp;import java.util.ArrayList;import java.util.List;/** * Crea w397090770 11年前 (2013-07-24) 6084℃ 4评论2喜欢
简介nodetool是cassandra自带的外围工具,通过JMX可以动态修改当前进程内存数据,注意cassandra是无主对等架构,默认的命令是操作本机当前进程,例如repair,如果需要做全集群修复,需要在每台机器上执行对应的nodetool命令。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop执行nodetool help命令可 w397090770 5年前 (2019-09-08) 3648℃ 0评论3喜欢
Apache Hive 1.0.1 和 1.1.1两个版本同时发布,他们分别是基于Hive 1.0.0和Hive 1.1.0,这两个版本都同时修复可同一个Bug:LDAP授权provider的漏洞。如果用户在HiveServer2里面使用到LDAP授权模式(hive.server2.authentication=LDAP),并且LDAP使用简单地未认证模式,或者是匿名绑定(anonymous bind),在这种情况下未得到合理授权的用户将得到认证(authe w397090770 9年前 (2015-05-25) 4997℃ 0评论3喜欢
一、百度(武汉地区)第一部分:1、描述数据库的简单操作。2、描述TCP\IP四层模型,并简述之。3、描述MVC的内容。第二部分:1、给出a-z0-9,在其中选择三个字符组成一个密码,输出全部的情况,程序实现。2、字符串的反转,比如abcde,输出edcba.3、许多程序会大量使用字符串。对于不同的字符串,我们希望能够 w397090770 12年前 (2013-04-15) 13371℃ 0评论9喜欢
摘要:本文整理自快手实时计算团队技术专家张静、张芒在 Flink Forward Asia 2021 的分享。主要内容包括: Flink SQL 在快手功能扩展性能优化稳定性提升未来展望 一、Flink SQL 在快手 经过一年多的推广,快手内部用户对 Flink SQL 的认可度逐渐提高,今年新增的 Flink 作业中,SQL 作业达到了 60%,与去年相比有了一倍的提升,峰值吞吐 w397090770 3年前 (2022-02-18) 1009℃ 0评论4喜欢
原文名:Paxos Made Simple [PDF下载] Leslie Lamport 2001/11/01翻译:phylipsbmy 原译文链接: http://duanple.blog.163.com/blog/static/709717672011440267333/审校:Jerry Lee oldratlee<at>gmail<dot>com译序“在PODC2001会议上,我总是听到人们在抱怨Paxos算法是那么的难以理解。人们总是被那些古希腊的名称弄得晕头转向,而使得他们觉得论文难以理解 w397090770 7年前 (2018-03-12) 3598℃ 0评论9喜欢
OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值。本文基于QQ音乐海量大数据实时分析场景,通过QQ音乐与腾讯云EMR产品深度合作的案例解读,还原一个不一样的大数据云端解决方案。一、背景介绍QQ音乐是腾讯音乐旗下一款领先的音乐流媒体产品,平台打造了“听 w397090770 4年前 (2020-10-21) 1165℃ 0评论0喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6131℃ 1评论24喜欢
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 9年前 (2015-10-21) 3870℃ 0评论4喜欢
本书将为您简要介绍ElasticSearch的基础知识以及Elasticsearch 5的新功能。通过本书将学习到Elasticsearch的基本功能和高级功能,例如查询,索引,搜索和修改数据。本书还介绍了一些高级知识,包括聚合,索引控制,分片,复制和聚类。中间部分介绍了ElasticSearch集群相关的知识,包括备份、监控、恢复等。读完本书,您将掌握Elastics zz~~ 8年前 (2017-02-28) 4963℃ 0评论13喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21278℃ 6评论27喜欢
这次整理的 PPT 来自于2018年09月03日至05日在 Berlin 进行的 flink forward 会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:https://berlin-2018.flink-forward.org/。本次会议共有超过350个 Flink 社区会员的人参与,因为原始的 PPT 是在 http://www.slideshare.net/ 网站,这个网站需要翻墙;为了学习交流的方便,本博客将这些 P w397090770 6年前 (2018-09-19) 2589℃ 2评论5喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 4年前 (2020-06-16) 1302℃ 0评论8喜欢
在这篇文章中,我将介绍如何在Spark中使用Akka-http并结合Cassandra实现REST服务,在这个系统中Cassandra用于数据的存储。 我们已经见识到Spark的威力,如果和Cassandra正确地结合可以实现更强大的系统。我们先创建一个build.sbt文件,内容如下:[code lang="scala"]name := "cassandra-spark-akka-http-starter-kit"version := "1.0" w397090770 8年前 (2016-10-17) 3867℃ 1评论5喜欢
Spark 1.1.0中兼容大部分Hive特性,我们可以在Spark中使用Hive。但是默认的Spark发行版本并没有将Hive相关的依赖打包进spark-assembly-1.1.0-hadoop2.2.0.jar文件中,官方对此的说明是:Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, it is not included in the default Spark assembly 所以,如果你直 w397090770 10年前 (2014-09-26) 12834℃ 5评论9喜欢


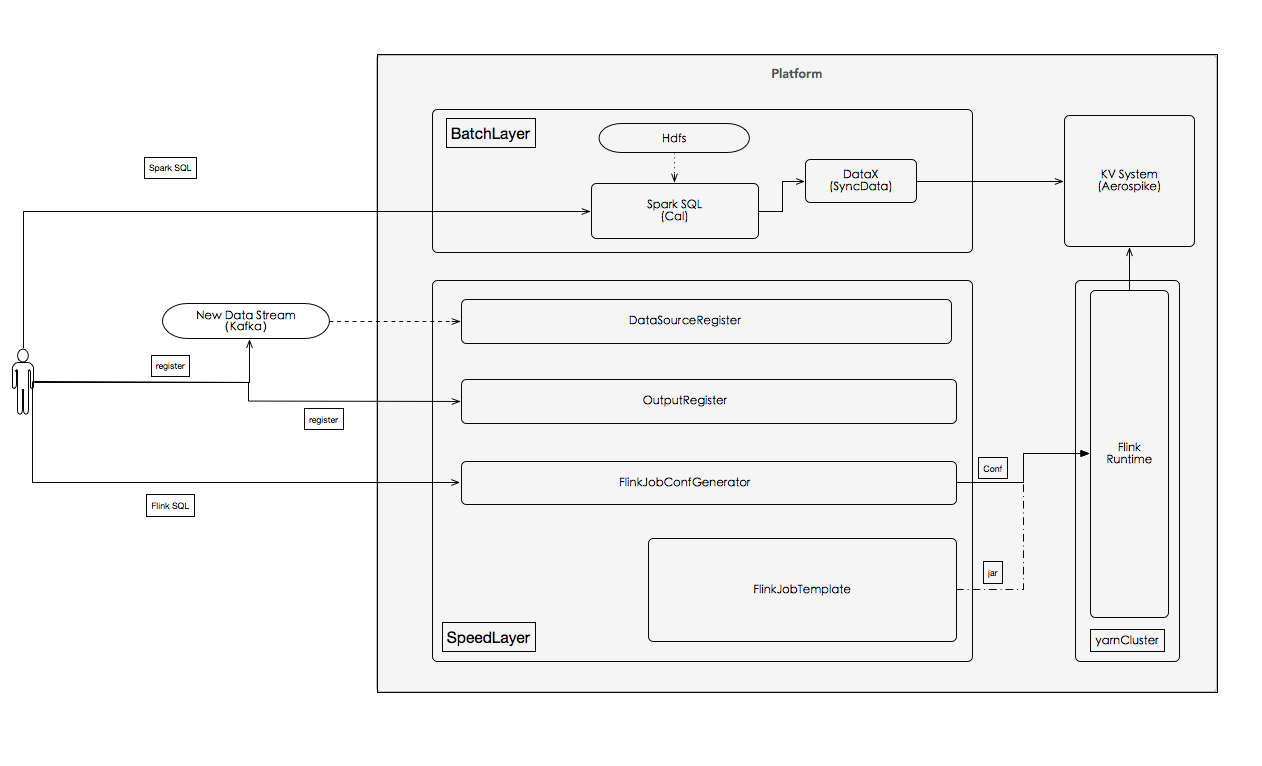














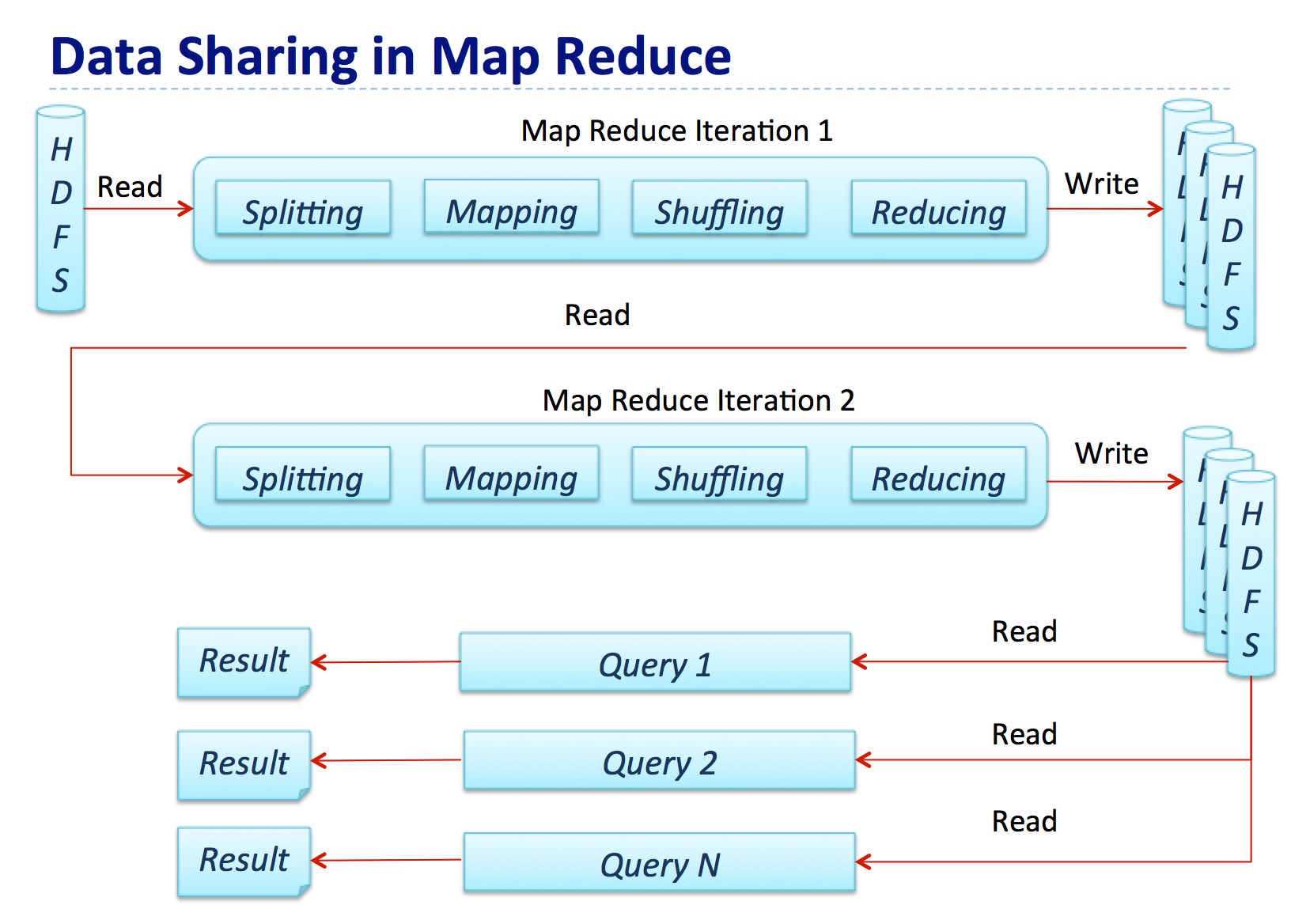
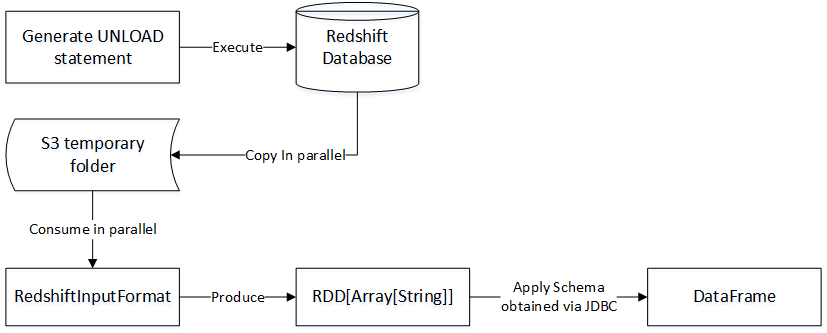
![[电子书]Mastering Elasticsearch 5.x - Third Edition PDF下载](https://www.iteblog.com/pic/elastic/Mastering_Elasticsearch_5.x-Third_Edition_iteblog.jpg)



