1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2638℃ 0评论3喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-19) 7357℃ 6评论10喜欢
我们知道,HDFS 被设计成存储大规模的数据集,我们可以在 HDFS 上存储 TB 甚至 PB 级别的海量数据。而这些数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及文件块, w397090770 6年前 (2018-10-09) 9291℃ 2评论31喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 9年前 (2016-03-30) 16296℃ 0评论10喜欢
经过近一个月时间,终于差不多将之前在Flume 0.9.4上面编写的source、sink等插件迁移到Flume-ng 1.5.0,包括了将Flume 0.9.4上面的TailSource、TailDirSource等插件的迁移(当然,我们加入了许多新的功能,比如故障恢复、日志的断点续传、按块发送日志以及每个一定的时间轮询发送日志而不是等一个日志发送完才发送另外一个日志)。现在 w397090770 10年前 (2014-06-18) 17494℃ 13评论15喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2286℃ 0评论2喜欢
和 MySQL 以及其他计算引擎类似,MongoDB 给我们提供了 explain 命令来查看某个查询的执行计划,其使用也比较简单,具体如下:[code lang="bash"]db.collection.explain().<method(...)>[/code]explain 命令默认是打印出查询的 queryPlanner,也就是什么参数都不传递。从 3.5.5 版本开始,explain 命名还支持 executionStats 和 allPlansExecution 两种运行模式 w397090770 3年前 (2021-06-21) 381℃ 0评论0喜欢
《Spark源码分析:多种部署方式之间的区别与联系(1)》 《Spark源码分析:多种部署方式之间的区别与联系(2)》 从官方的文档我们可以知道,Spark的部署方式有很多种:local、Standalone、Mesos、YARN.....不同部署方式的后台处理进程是不一样的,但是如果我们从代码的角度来看,其实流程都差不多。 从代码中,我们 w397090770 10年前 (2014-10-24) 7705℃ 2评论14喜欢
如今,互联网上存在大量功能相同的Web服务,但是它们的非功能属性(Quality of Service,QoS)一般相差很大,以至于用户在选择合适的Web服务时,把服务的QoS作为评判服务好坏的重要指标。QoS并不是在Web服务领域中产生的,它最先用在计算机网络和实时系统的非功能需求中,后来很多领域都引入了QoS指标,而且不同领域所用的QoS w397090770 12年前 (2013-05-16) 3642℃ 0评论6喜欢
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了 D w397090770 5年前 (2019-08-13) 3502℃ 0评论3喜欢
本文将介绍如何在Google Compute Engine(https://cloud.google.com/compute/)平台上基于 Hadoop 1 或者 Hadoop 2 自动部署 Flink 。借助 Google 的 bdutil(https://cloud.google.com/hadoop/bdutil) 工具可以启动一个集群并基于 Hadoop 部署 Flink 。根据下列步骤开始我们的Flink部署吧。要求(Prerequisites)安装(Google Cloud SDK) 请根据该指南了解如何安装 Google Cl w397090770 9年前 (2016-04-21) 1796℃ 0评论3喜欢
Introduce Apache Flink 提供了可以恢复数据流应用到一致状态的容错机制。确保在发生故障时,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。 容错机制通过持续创建分布式数据流的快照来实现。对于状态占用空间小的流应用,这些快照非常轻量,可以高频率创建而对性能影 zz~~ 8年前 (2017-02-08) 4559℃ 0评论7喜欢
上海Spark Meetup第六次聚会将于2015年08月08日下午1:30 PM to 5:00 PM在上海市杨浦云计算创新基地发展有限公司举办,详细地址上海市杨浦区伟德路6号云海大厦13楼。本次聚会由Intel举办。大会主题主讲题目:Tachyon: 内存为中心可容错的分布式存储系统 摘要:在越来越多的大数据应用场景诸如机器学习,数据分析等, 内存成 w397090770 9年前 (2015-08-28) 4461℃ 0评论1喜欢
Spark GraphX in Action开头介绍了GraphX库可以干什么,并通过例子介绍了如何以交互的方式使用GraphX 。阅读完本书,您将学习到很多实用的技术,用于增强应用程序和将机器学习算法应用于图形数据中。 本书包括了以下几个知识点: (1)、Understanding graph technology (2)、Using the GraphX API (3)、Developing algorithms w397090770 8年前 (2017-02-12) 4727℃ 0评论5喜欢
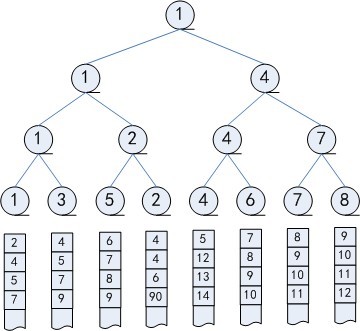
假设有k个称为顺串的有序序列,我们希望将他们归并到一个单独的有序序列中。每一个顺串包含一些记录,并且这些记录按照键值的大小,以非递减的顺序排列。令n为k个顺串中的所有记录的总数。并归的任务可以通过反复输出k个顺串中键值最小的记录来完成。键值最小的记录的选择有k种可能,它可能是任意有一个顺串中的第1个 w397090770 12年前 (2013-04-01) 6688℃ 2评论7喜欢
如果你使用Apache Spark解决了中等规模数据的问题,但是在海量数据使用Spark的时候还是会遇到各种问题。High Performance Spark将会向你展示如何使用Spark的高级功能,所以你可以超越新手级别。本书适合软件工程师、数据工程师、开发者以及Spark系统管理员的使用。本书作者Holden Karau, Rachel Warren,由O'Reilly于2016年03月出版,全书175页 w397090770 8年前 (2016-12-04) 4929℃ 0评论6喜欢
Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下,保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的,你也可以保存你想要的后缀名。假设test文件里面有一下的Hive查询语句:[code lang="JAVA"]select * from p limit 10;select count(*) from p;[/code]那么我们可以用下面的命令来查询:[cod w397090770 11年前 (2013-11-06) 10143℃ 2评论5喜欢
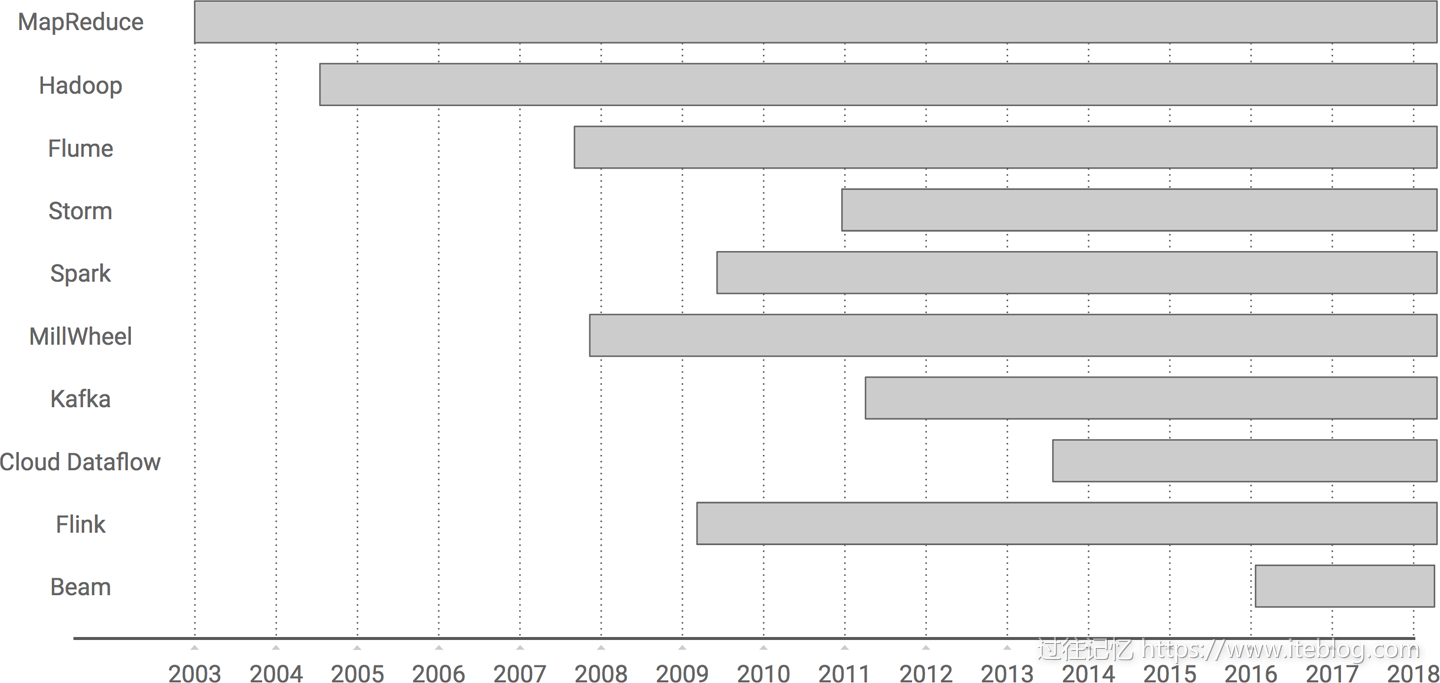
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 6年前 (2018-10-08) 10228℃ 2评论27喜欢
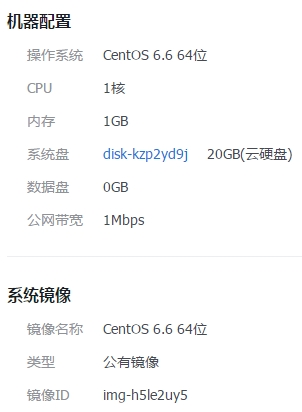
随着过往记忆大数据技术博客的浏览量逐渐增多(目前日IP达到5k+,PV达到1.5W+),博客的访问速度越来越慢,在高峰时期打开一个页面需要近10s的时间,这样的情况非常的糟糕,没多少人愿意等待近10s,所以优化网站的访问速度迫在眉睫! 先来介绍一下本博客的相关配置信息:博客购买的是腾讯云主机,CentOS 6.6 64位、1 w397090770 8年前 (2016-07-19) 1708℃ 0评论4喜欢
几天前(2016年7月27日),Apache社区发布了Apache Mesos 1.0.0, 这是 Apache Mesos 的一个里程碑事件。相较于前面的版本, 1.0.0首先是改进了与 docker 的集成方式,弃用了 docker daemon;其次,新版本大力推进解决了接口规范化问题,新的 HTTP API 使得开发者能够更容易的开发 Mesos 框架;最后, 为了更好的满足企业用户的多租户,安全,审 w397090770 8年前 (2016-07-31) 2026℃ 0评论2喜欢
2013年10月15号,Hadoop已经升级到2.2.0稳定版了,同时带来了很多新的特性,本人所在的公司经过一个月时间对Hadoop2.2.0的测试,在确保对业务没有影响的前提下将Hadoop集群顺利的升级到Hadoop2.2.0版本,本文主要介绍如何从Hadoop1.x(本博客用到的是hadoop-0.20.2-cdh3u4)版本的集群顺利地升级到Hadoop2.2.0。友情提示:请在读下文之间认真 w397090770 11年前 (2013-12-02) 12599℃ 2评论8喜欢
今天 Apache Kafka 项目的 2.0.0 版本正式发布了!距离 1.0 版本的发布,相距还不到一年。这一年不论是社区还是 Confluent 内部对于到底 Kafka 要向哪里发展都有很多讨论:从最初的标准消息系统,到现如今成为一个完整的包括导入导出和处理的流数据平台,从 0.8.2 一直到 1.0 版本,很多新特性和新部件被不断添加。但同时更重要的,关于 w397090770 6年前 (2018-06-28) 5266℃ 0评论6喜欢
2019年12月18日 Apache Kafka 2.4 正式发布了,这个版本有很多新功能,本文将介绍这个版本比较重要的功能,完整的更新可以参见 release notes如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopKafka broker, producer, 以及 consumer 新功能KIP-392: 允许消费者从最近的副本获取数据在 Kafka 2.4 版本之前,消费者 w397090770 5年前 (2019-12-25) 1530℃ 0评论4喜欢
为了提高 HBase 存储的利用率,很多 HBase 使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 w397090770 8年前 (2017-02-09) 1954℃ 0评论1喜欢
由于需要在Flume里面加入一些我需要的代码,这时候就需要重新编译Flume代码,因为在编译Flume源码的时候出现了很多问题,所以写出这篇博客,以此分享给那些也需要编译代码的人一些参考,这里以如何编译Flume-0.9.4源码为例进行说明。 首先下载Flume0.9.4源码(可以到https://repository.cloudera.com/content/repositories/releases/com/cloudera/fl w397090770 11年前 (2014-01-22) 12258℃ 1评论4喜欢
Presto 在 Facebook 的诞生最开始是为了填补当时 Facebook 内部实时查询和 ETL 处理之间的空白。Presto 的核心目标就是提供交互式查询,也就是我们常说的 Ad-Hoc Query,很多公司都使用它作为 OLAP 计算引擎。但是随着近年来业务场景越来越复杂,除了交互式查询场景,很多公司也需要批处理;但是 Presto 作为一个 MPP 计算引擎,将一个 MPP 体 w397090770 2年前 (2022-06-23) 1552℃ 0评论3喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 那么,如何在Linux平台下面安装Maven呢?下面以CentOS平台为例,说明如 w397090770 11年前 (2013-10-21) 32225℃ 3评论13喜欢
一、前言在 2019 年 1 月份的时候,我们发表过一篇博客 从 Hive 迁移到 Spark SQL 在有赞的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91% 以上,最后也分享一些在 Spark 踩过的坑和经验希望能帮助到大家 w397090770 5年前 (2020-01-05) 1694℃ 0评论2喜欢
auto_ptr是这样一种指针:它是“它所指向的对象”的拥有者。这种拥有具有唯一性,即一个对象只能有一个拥有者,严禁一物二主。当auto_ptr指针被摧毁时,它所指向的对象也将被隐式销毁,即使程序中有异常发生,auto_ptr所指向的对象也将被销毁。设计动机在函数中通常要获得一些资源,执行完动作后,然后释放所获得的资源 w397090770 12年前 (2013-03-30) 2722℃ 0评论4喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 12988℃ 1评论14喜欢
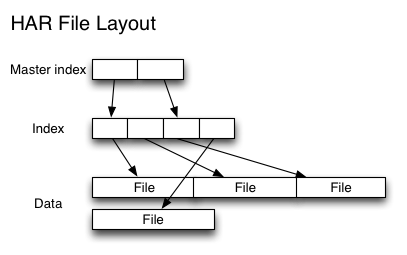





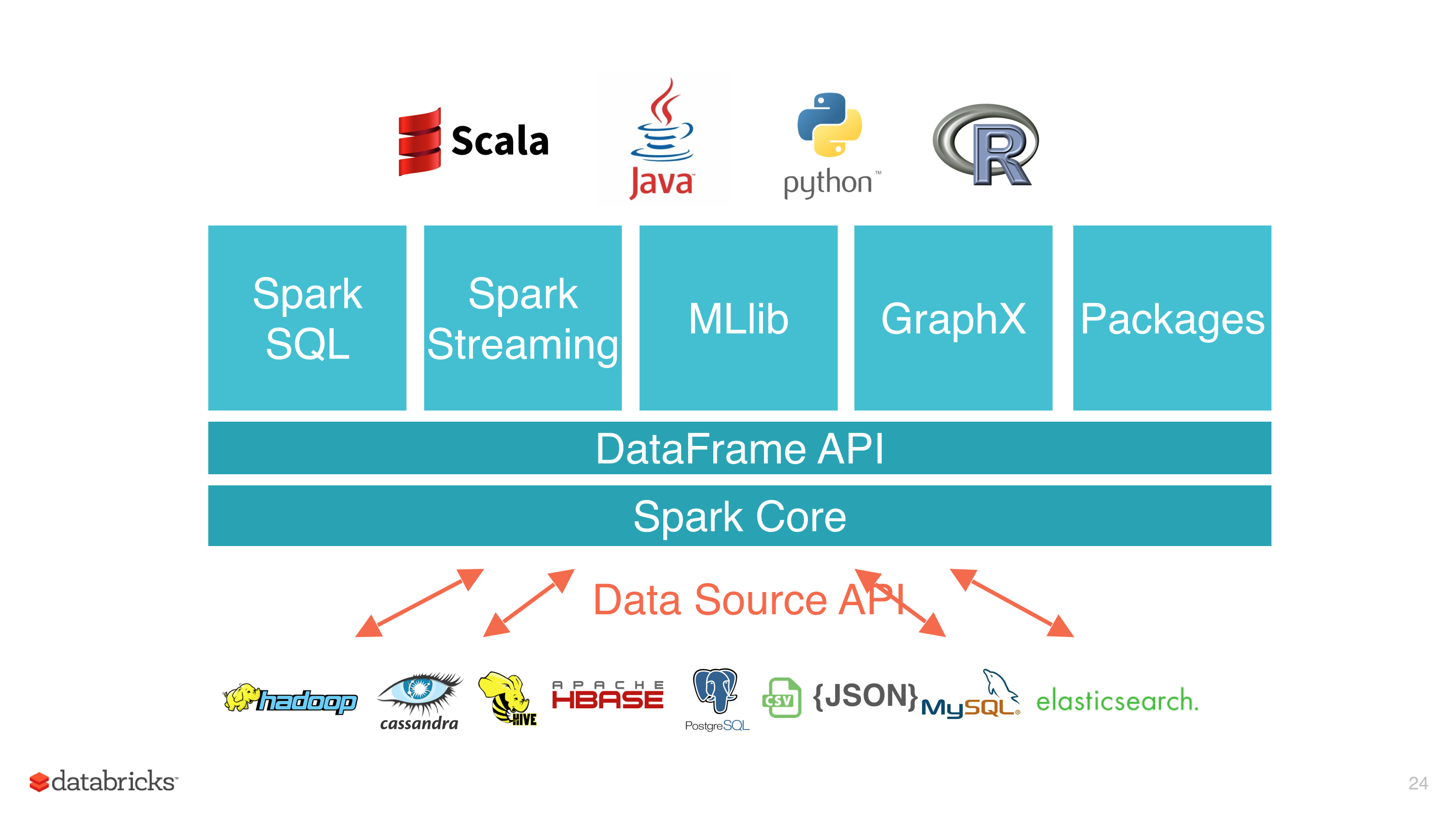


![[电子书]Spark GraphX in Action PDF下载](https://www.iteblog.com/pic/books/Spark_Graphx_in_Action_iteblog.png)
![[电子书]High Performance Spark下载](https://www.iteblog.com/pic/books/High_Performance_Spark.jpg)