流处理系统月刊是一份专门收集关于Spark、Flink、Kafka、Apex等流处理系统的技术干货月刊,完全免费,每天更新,欢迎关注。下面资源如无法正常访问,请使用《最新可访问Google的Hosts文件》或《Tunnello:免费的浏览器翻墙插件》进行科学上网。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoo w397090770 8年前 (2016-10-07) 4348℃ 0评论5喜欢
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 目前本站昨晚已经把里面的85(今天早上发现又上传了25个视频,晚上我补全)个视频全部从Youtube下载下来,已经上传到百度网盘(访问https://github.com/397090770/spark-summit-east-2017获 w397090770 8年前 (2017-02-15) 2790℃ 0评论15喜欢
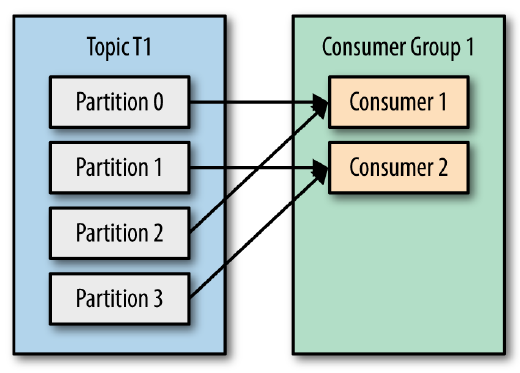
问题用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 对应分区中的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group w397090770 7年前 (2017-07-22) 17749℃ 3评论27喜欢
每次当你在Yarn上以Cluster模式提交Spark应用程序的时候,通过日志我们总可以看到下面的信息:[code lang="java"]21 Oct 2014 14:23:22,006 INFO [main] (org.apache.spark.Logging$class.logInfo:59) - Uploading file:/home/spark-1.1.0-bin-2.2.0/lib/spark-assembly-1.1.0-hadoop2.2.0.jar to hdfs://my/user/iteblog/...../spark-assembly-1.1.0-hadoop2.2.0.jar21 Oct 2014 14:23:23,465 INFO [main] (org.ap w397090770 10年前 (2014-11-10) 10900℃ 2评论12喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 6176℃ 0评论9喜欢
ZooKeeper使用ACL来控制访问其znode(ZooKeeper的数据树的数据节点)。ACL的实现方式非常类似于UNIX文件的访问权限:它采用访问权限位 允许/禁止 对节点的各种操作以及能进行操作的范围。不同于UNIX权限的是,ZooKeeper的节点不局限于 用户(文件的拥有者),组和其他人(其它)这三个标准范围。ZooKeeper不具有znode的拥有者的概念。 w397090770 9年前 (2015-12-02) 7265℃ 1评论4喜欢
国内区 Apple ID 转美国区的教程参见:2021年最新中国区 Apple ID 转美国区教程注意:下面的操作步骤是在2021年10月29日进行的,过程中都没有使用到 VPN 软件。使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple I w397090770 3年前 (2021-10-22) 4246℃ 0评论7喜欢
昨天Kafka集群磁盘容量达到了90%,于是赶紧将Log的保存时间设置成24小时,但是发现设置完之后Log仍然没有被删除。于是今天特意去看了一下Kafka日志删除相关的代码,于是有了这篇文章。 在使用Kafka的时候我们一般都会根据需求对Log进行保存,比如保存1天、3天或者7天之类的,我们可以通过以下的几个参数实现:[code lan w397090770 9年前 (2016-03-28) 5511℃ 0评论17喜欢
作为一家数据驱动型公司,Pinterest 的许多关键商业决策都是基于数据分析做出的。分析平台是由大数据平台团队提供的,它使公司内部的其他人能够处理 PB 级的数据,以得到他们需要的结果。数据分析是 Pinterest 的一个关键功能,不仅可以回答商业问题,还可以解决工程问题,对功能进行优先排序,识别用户面临的最常见问题, w397090770 3年前 (2021-06-20) 607℃ 0评论0喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u w397090770 7年前 (2018-02-14) 14950℃ 0评论21喜欢
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 10年前 (2014-08-11) 9892℃ 0评论14喜欢
一、前言本文主要介绍了 Presto 的简单原理,以及 Presto 在有赞的实践之路。二、Presto 介绍Presto 是由 Facebook 开发的开源大数据分布式高性能 SQL 查询引擎。起初,Facebook 使用 Hive 来进行交互式查询分析,但 Hive 是基于 MapReduce 为批处理而设计的,延时很高,满足不了用户对于交互式查询想要快速出结果的场景。为了解决 Hive w397090770 4年前 (2020-12-21) 789℃ 0评论2喜欢
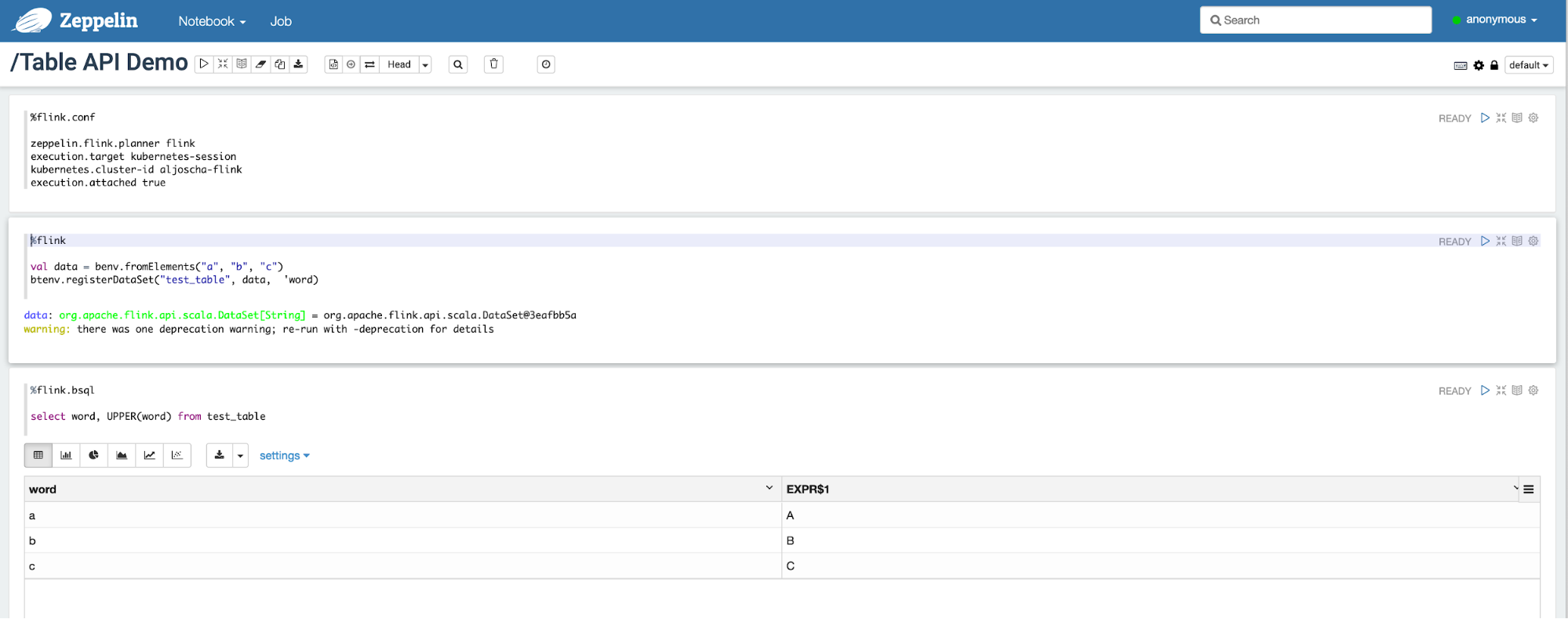
Apache Flink 1.10.0 于 2020年02月11日正式发布。Flink 1.10 是一个历时非常长、代码变动非常大的版本,也是 Flink 社区迄今为止规模最大的一次版本升级,Flink 1.10 容纳了超过 200 位贡献者对超过 1200 个 issue 的开发实现,包含对 Flink 作业的整体性能及稳定性的显著优化、对原生 Kubernetes 的初步集成以及对 Python 支持(PyFlink)的重大优化。 w397090770 5年前 (2020-02-12) 3459℃ 0评论3喜欢
最近在Yarn上使用Spark,不管是yarn-cluster模式还是yarn-client模式,都出现了以下的异常:[code lang="java"]Application application_1434099279301_123706 failed 2 times due to AM Container for appattempt_1434099279301_123706_000002 exited with exitCode: 127 due to: Exception from container-launch:org.apache.hadoop.util.Shell$ExitCodeException:at org.apache.hadoop.util.Shell.runCommand(Shell.java:464) w397090770 9年前 (2015-06-19) 7858℃ 0评论3喜欢
本博客曾经介绍了《如何手动添加依赖的jar文件到本地Maven仓库》这里的方法非常的简单,而且局限性很大:只能提供给本人开发使用,无法共享给其他需要的人。本文将介绍如何把自己开发出来的Java包发布到Maven中央仓库(http://search.maven.org/),这样任何人都可以搜索到这个包并使用它。如果你现在还不了解Maven是啥东西,请你 w397090770 8年前 (2016-09-27) 9709℃ 2评论23喜欢
一致性哈希算法(Consistent Hashing)最早在1997年由 David Karger 等人在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出,其设计目标是为了解决因特网中的热点(Hot spot)问题;一致性哈希最初在 P2P 网络中作为分布式哈希表( DHT)的常用数据分布算法,目前这个算法在分布式系统中成 w397090770 6年前 (2019-02-01) 3844℃ 0评论7喜欢
我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀 w397090770 9年前 (2016-04-04) 18101℃ 0评论42喜欢
在高德纳的计算机程序设计艺术中,有如下问题:可否在一未知大小的集合中,随机取出一元素?。或者是Google面试题: I have a linked list of numbers of length N. N is very large and I don’t know in advance the exact value of N. How can I most efficiently write a function that will return k completely random numbers from the list(中文简化的意思就是:在不知道文件总行 w397090770 9年前 (2015-11-09) 10260℃ 0评论16喜欢
建议用Spark 1.3.0提供的写关系型数据库的方法,参见《Spark RDD写入RMDB(Mysql)方法二》。 在《Spark与Mysql(JdbcRDD)整合开发》文章中我们介绍了如何通过Spark读取Mysql中的数据,当时写那篇文章的时候,Spark还未提供通过Java来使用JdbcRDD的API,不过目前的Spark提供了Java使用JdbcRDD的API。 今天主要来谈谈如果将Spark计算的结果 w397090770 10年前 (2015-03-10) 36908℃ 5评论33喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19770℃ 4评论92喜欢
随着网站的文章越来越多,网站的图片也不知不觉的多了起来,图片多起来带来的问题就是访问的人多的时候会导致页面加载速度越来越慢,这严重影响了网站的用户体验,所以网站图片异步加载势在必行。 图片异步加载就是图片只有在视野范围内才加载,没出现在范围内的图片就暂不加载,等用户滑动滚动条时再逐步 w397090770 8年前 (2016-07-08) 3443℃ 0评论7喜欢
使用 MAC 写移动硬盘的时候会出现 Read-only file system,我们可以使用下面方法来解决。[code code="bash"]iteblog: iteblog $ diskutil info /Volumes/Seagate\ Backup\ Plus\ Drive/ Device Identifier: disk2s1 Device Node: /dev/disk2s1[/code]记下上面的 Device Node。然后使用下面命令弹出我们插入的移动硬盘:[code code="bash"]iteblog: iteblog $ hdiutil eje w397090770 4年前 (2021-01-05) 2238℃ 0评论2喜欢
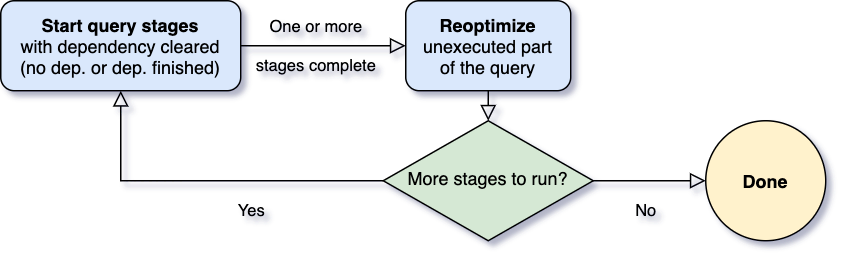
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 4年前 (2020-05-30) 1703℃ 0评论4喜欢
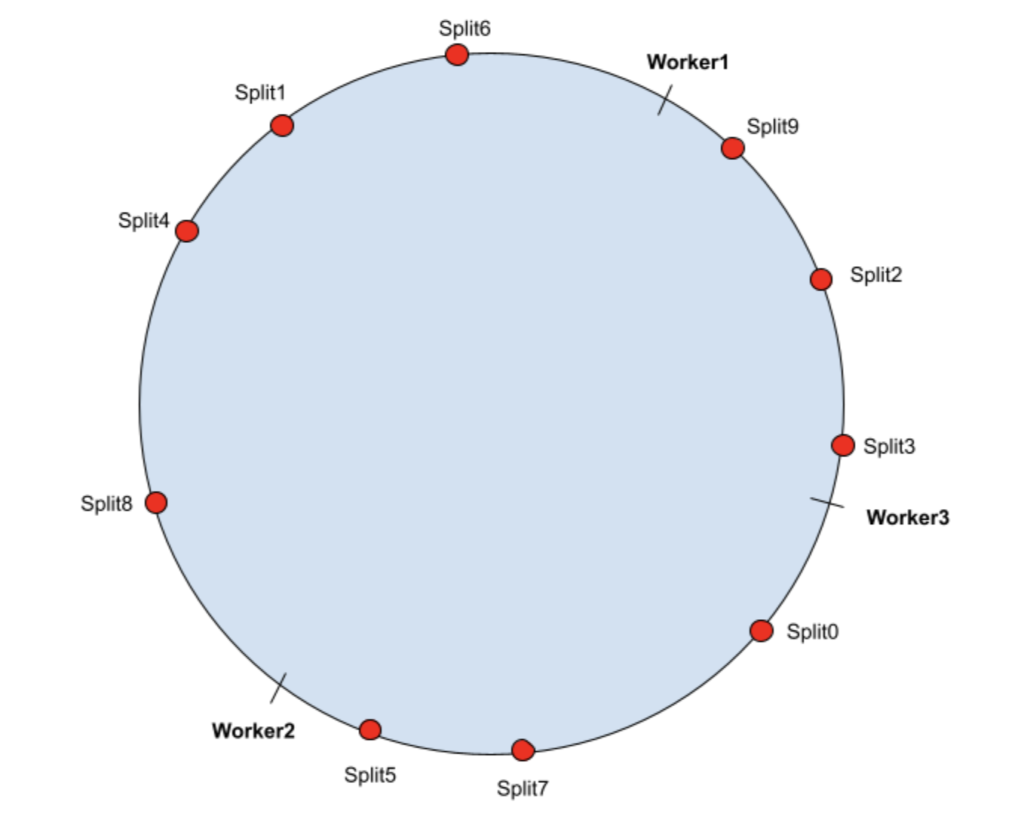
R目前,越来越多的用户开始在 Presto 里面使用 Alluxio,它通过利用 SSD 或内存在 Presto workers 上缓存热数据集,避免从远程存储读取数据。 Presto 支持基于哈希的软亲和调度(hash-based soft affinity scheduling),强制在整个集群中只缓存一到两份相同的数据,通过允许本地缓存更多的热数据来提高缓存效率。 但是,当前使用的哈希算法在集 w397090770 3年前 (2022-04-01) 443℃ 0评论1喜欢
TreeMultimap类是Multimap接口的实现子类,其中的key和value都是根据默认的自然排序或者用户指定的排序规则排好序的。在任何情况下,如果你想判断TreeMultimap中两个元素是否相等,都不要使用equals方法去实现,而需要用compareTo或compare函数去判断。下面探讨一下TreeMultimap类的源码实现:[code lang="JAVA"] TreeMultimap里面一共有两 w397090770 11年前 (2013-10-09) 7349℃ 1评论2喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上述任务,而且还有更多的功能。与大多数下载管理器不同 w397090770 9年前 (2016-02-19) 1737℃ 0评论1喜欢
由于本文比较长,考虑到篇幅问题,所以将本文拆分为二,请阅读本文之前先阅读本文的第一部分《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》。为你带来的不变,敬请谅解。 与MultipleOutputFormat类不一样的是,MultipleOutputs可以为不同的输出产生不同类型,到这里所说的MultipleOutputs类还是旧版本的功能,后 w397090770 11年前 (2013-11-27) 21509℃ 0评论17喜欢
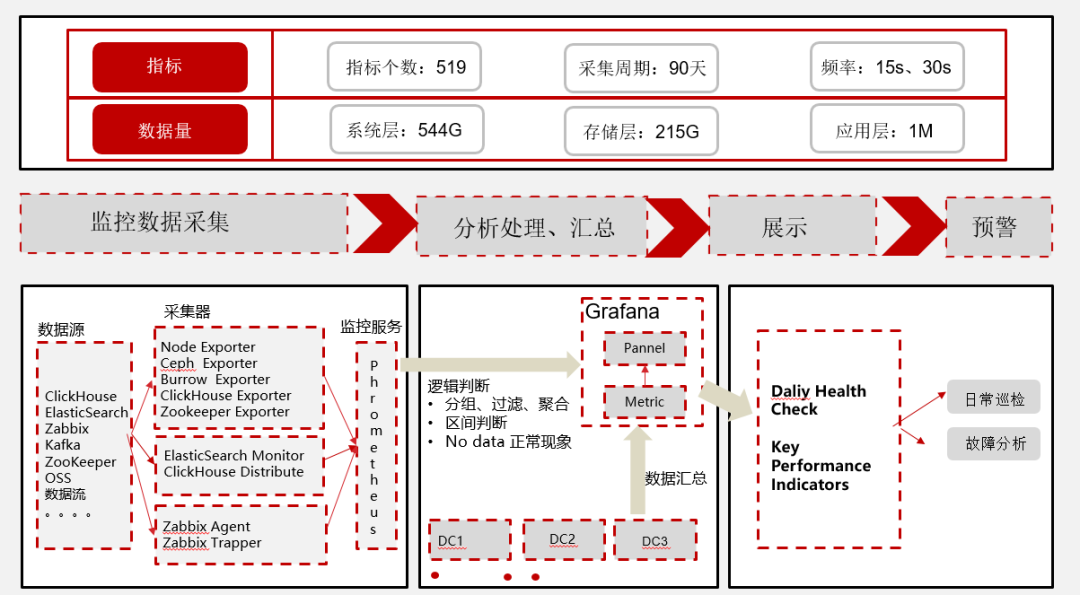
导语:随着互联网业务的迅速发展,用户对系统的要求也越来越高,而做好监控为系统保驾护航,能有效提高系统的可靠性、可用性及用户体验。监控系统是整个运维环节乃至整个项目及产品生命周期中最重要的一环。百分点大数据技术团队基于大数据平台项目,完成了百亿流量、约3000+台服务器集群规模的大数据平台服务的监控, zz~~ 3年前 (2021-09-24) 566℃ 0评论4喜欢
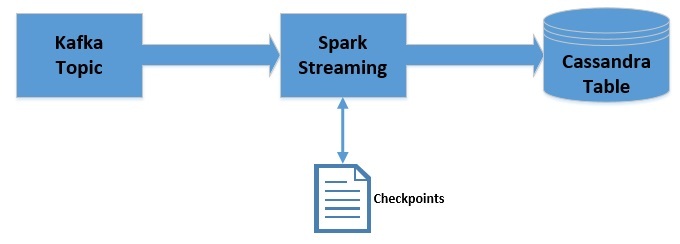
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4041℃ 0评论8喜欢
背景熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较 w397090770 5年前 (2020-01-10) 1476℃ 0评论2喜欢