Apache Hadoop 3.0.0-alpha1相对于hadoop-2.x来说包含了许多重要的改进。这里介绍的是Hadoop 3.0.0的alpha版本,主要是便于检测和收集应用开发人员和其他用户的使用反馈。因为是alpha版本,所以本版本的API稳定性和质量没有保证,如果需要在正式开发中使用,请耐心等待稳定版的发布吧。本文将对Hadoop 3.0.0重要的改进进行介绍。Java最低 zz~~ 8年前 (2016-09-22) 3363℃ 0评论7喜欢
题目描述:给定a和n,计算a+aa+aaa+a...a(n个a)的和。输入:测试数据有多组,输入a,n(1<=a<=9,1<=n<=100)。输出:对于每组输入,请输出结果。样例输入:1 10样例输出:1234567900从题中就可以看出,当a = 9, n = 100的时候,一个int类型的数是存不下100位的数,所以不能运用平常的方法来求,下面介绍我的解法,我声明 w397090770 12年前 (2013-03-31) 4161℃ 0评论4喜欢
Spark GraphX in Action开头介绍了GraphX库可以干什么,并通过例子介绍了如何以交互的方式使用GraphX 。阅读完本书,您将学习到很多实用的技术,用于增强应用程序和将机器学习算法应用于图形数据中。 本书包括了以下几个知识点: (1)、Understanding graph technology (2)、Using the GraphX API (3)、Developing algorithms w397090770 8年前 (2017-02-12) 4727℃ 0评论5喜欢
有时候我们需要根据记录的类别分别写到不同的文件中去,正如本博客的 《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(一)》《Hadoop多文件输出:MultipleOutputFormat和MultipleOutputs深究(二)》以及《Spark多文件输出(MultipleOutputFormat)》等文章提到的类似。那么如何在Flink Streaming实现类似于《Spark多文件输出(MultipleOutputFormat)》文 w397090770 8年前 (2016-05-10) 8229℃ 4评论7喜欢
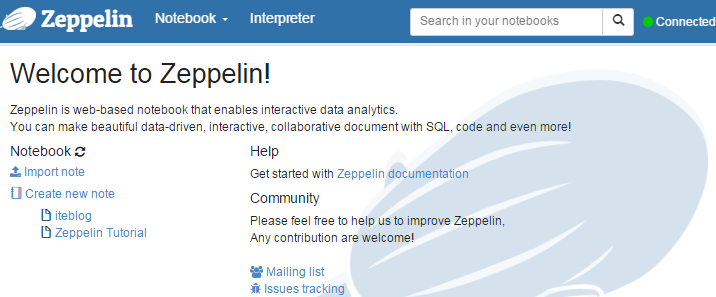
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 9年前 (2016-02-02) 20643℃ 9评论20喜欢
Linux内核代码有很多很经典的代码,仔细去看看,可以学到很多知识。今天说说Linux是怎么实现min和max的。max和min函数都是比较常用的,可以用函数,或者利用宏去实现,一般我们会这样去写:[code lang="CPP"]#define min(x,y) ((x)>(y)?(y):(x))#define max(x,y) ((x)>(y)?(x):(y))[/code]但是上面的写法是有副作用的。比如输入[code lang="CPP"]minv w397090770 12年前 (2013-04-06) 7364℃ 0评论1喜欢
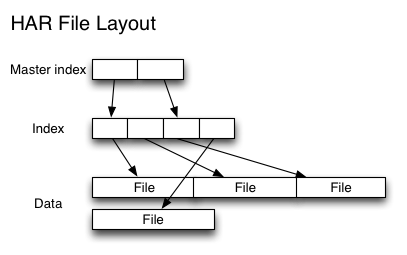
先来了解一下Hadoop中何为小文件:小文件指的是那些文件大小要比HDFS的块大小(在Hadoop1.x的时候默认块大小64M,可以通过dfs.blocksize来设置;但是到了Hadoop 2.x的时候默认块大小为128MB了,可以通过dfs.block.size设置)小的多的文件。如果在HDFS中存储小文件,那么在HDFS中肯定会含有许许多多这样的小文件(不然就不会用hadoop了)。而HDFS的 w397090770 11年前 (2014-03-17) 15387℃ 1评论10喜欢
Material-UI是实现了Google Material模式的CSS框架,其中包括了一系列的React组建。Material Design是2014年Google I/O发布的 势必将会成为统一 Android Mobile、Android Table、Desktop Chrome 等全平台设计语言规范,对从业人员意义重大。 为了更好地使用这个框架,推荐大家先了解一下React Library,然后再使用Material-UI。如果想及时了解Spark、H w397090770 10年前 (2015-05-02) 11325℃ 1评论14喜欢
Apache Hive 1.0.1 和 1.1.1两个版本同时发布,他们分别是基于Hive 1.0.0和Hive 1.1.0,这两个版本都同时修复可同一个Bug:LDAP授权provider的漏洞。如果用户在HiveServer2里面使用到LDAP授权模式(hive.server2.authentication=LDAP),并且LDAP使用简单地未认证模式,或者是匿名绑定(anonymous bind),在这种情况下未得到合理授权的用户将得到认证(authe w397090770 9年前 (2015-05-25) 4997℃ 0评论3喜欢
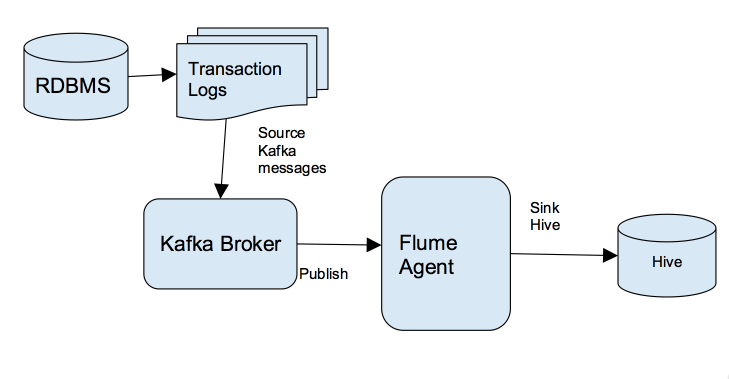
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 8年前 (2016-08-30) 11454℃ 6评论26喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u w397090770 7年前 (2018-02-14) 14950℃ 0评论21喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 4年前 (2020-06-28) 1020℃ 0评论1喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 10年前 (2014-09-08) 18320℃ 177评论16喜欢
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于美国时间 2022 年 6 月 16 日 宣布,Apache Doris 成功从 Apache 孵化器毕业,正式成为 Apache 顶级项目(Top-Level Project,TLP)。 以下内容译自 Apache Doris 官网(https://doris.apache.org/ )。Apache Doris 是一个基于 MPP 的现代化、高性能、实时的分析型数据库,以极速易用的 zz~~ 2年前 (2022-06-16) 654℃ 0评论2喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中,我们谈到了Hadoop 1.x上的fsimage和edits合并实现,里面也提到了Hadoop 2.x版本的fsimage和edits合并实现和Hadoop 1.x完全不一样,今天就来谈谈Hadoop 2.x中fsimage和edits合并的实现。 我们知道,在Hadoop 2.x中解决了NameNode的单点故障问题;同时SecondaryName已经不用了,而之前的Hadoop 1.x中是通过Se w397090770 11年前 (2014-03-12) 12492℃ 0评论20喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Improve Presto Architectural Decisions with Shadow Cache at Facebook》的分享,作者来自 Facebook 的 Ke Wang 和 普林斯顿CS系的 Zhenyu Song。Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.Zhenyu Song is a Ph.D. student at Princeton CS Department. He works on using mach w397090770 3年前 (2021-11-16) 259℃ 0评论1喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4661℃ 0评论11喜欢
背景我们基于 Apache Hadoop® 的数据平台以最小的延迟支持了数百 PB 的分析数据,并将其存储在基于 HDFS 之上的数据湖中。我们使用 Apache Hudi™ 作为我们表的维护格式,使用 Apache Parquet™ 作为底层文件格式。我们的数据平台利用 Apache Hive™、Apache Presto™ 和 Apache Spark™ 进行交互和长时间运行的查询,满足 Uber 不同团队的各种需求。 w397090770 3年前 (2022-03-13) 2329℃ 0评论1喜欢
想必大家在使用Maven从仓库下载Jar的时候都感觉速度非常慢吧。前几年国内的开源中国还提供了免费的Maven镜像,但是由于运营成本过高,此Maven仓库在运营两年后被迫关闭了。不过高兴的是,阿里云在2016年08月悄悄上线了Maven仓库,点这里:http://maven.aliyun.com。我们可以把下面的配置复制到$MAVEN_HOME/conf/setting.xml里面:如果想及时 w397090770 8年前 (2017-02-16) 18302℃ 1评论6喜欢
本书将向您展示如何利用Python的强大功能并将其用于Spark生态系统中。您将首先了解Spark 2.0的架构以及如何为Spark设置Python环境。通过本书,你将会使用Python操作RDD、DataFrames、MLlib以及GraphFrames等;在本书结束时,您将对Spark Python API有了全局的了解,并且学习到如何使用它来构建数据密集型应用程序。通过本书你将学习到以下的知识 zz~~ 8年前 (2017-03-09) 10778℃ 0评论12喜欢
ClickHouse作为一款开源列式数据库管理系统(DBMS)近年来备受关注,主要用于数据分析(OLAP)领域。作者根据以往经验和遇到的问题,总结出一些基本的开发和使用规范,以供使用者参考。随着公司业务数据量日益增长,数据处理场景日趋复杂,急需一种具有高可用性和高性能的数据库来支持业务发展,ClickHouse是俄罗斯的搜索公 w397090770 3年前 (2022-03-10) 1641℃ 0评论1喜欢
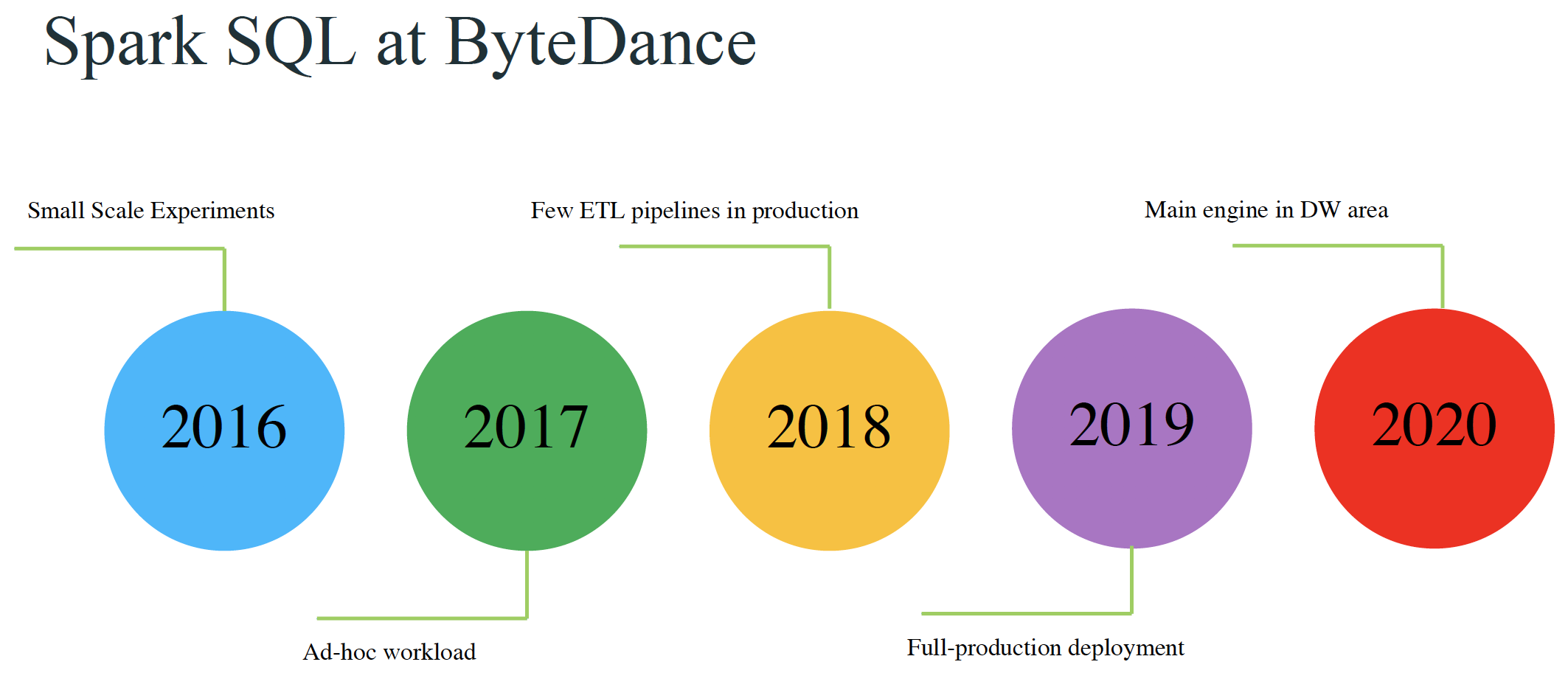
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 854℃ 0评论3喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2301℃ 0评论5喜欢
Presto 内部提供了大量内置的函数,可以满足我们大部分的日常需求。但总是有一些场景需要我们自己写 UDF,为了满足这个需求,Presto 给我们提供了 Function Namespace Managers 模块使得我们可以实现直接的 UDF。本文将给大家介绍一下如何使用 Presto 的 UDF 功能。如果需要使用 Function Namespace Managers 功能,需要把 presto-catalog-managers 模块里 w397090770 3年前 (2022-03-15) 1001℃ 0评论1喜欢
本程序用来仿照linux中的ls -l命令来实现的,主要运用的函数有opendir,readdir, lstat等。代码如下:[code lang="CPP"]#include <iostream>#include <vector>#include <cstdlib>#include <dirent.h>#include <sys/types.h>#include <sys/stat.h>#include <unistd.h>#include <cstring>#include <algorithm>using namespace std;void getFileAndDir(vector w397090770 12年前 (2013-04-04) 2649℃ 0评论0喜欢
MapReduce作业可以细分为map task和reduce task,而MRAppMaster又将map task和reduce task分为四种状态: 1、pending:刚启动但尚未向resourcemanager发送资源请求; 2、scheduled:已经向resourceManager发送资源请求,但尚未分配到资源; 3、assigned:已经分配到了资源且正在运行; 4、completed:已经运行完成。 map task的 w397090770 8年前 (2016-08-01) 3433℃ 0评论4喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 5年前 (2019-06-14) 922℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的数据分为表数据和元 w397090770 11年前 (2013-12-18) 14893℃ 0评论22喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8515℃ 0评论44喜欢
Zomato 是一家食品订购、外卖及餐馆发现平台,被称为印度版的“大众点评”。目前,该公司的业务覆盖全球24个国家(主要是印度,东南亚和中东市场)。本文将介绍该公司的 Food Feed 业务是如何从 Redis 迁移到 Cassandra 的。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoopFood Feed 是 Zomato 社交场景 w397090770 5年前 (2019-09-08) 1128℃ 0评论2喜欢

![[电子书]Spark GraphX in Action PDF下载](https://www.iteblog.com/pic/books/Spark_Graphx_in_Action_iteblog.png)









![[电子书]Learning PySpark PDF下载](https://www.iteblog.com/pic/books/Learning_PySpark_iteblog.jpg)