2017 年初,我们开始探索 Presto 来解决 OLAP 用例,我们意识到了这个惊人的查询引擎的潜力。与 Apache Hive 相比,它最初是一种临时查询工具,供数据工程师和分析师以更快的方式运行 SQL 来构建查询原型。 当时很多内部仪表板都由 AWS-Redshift 提供支持,并将数据存储和计算耦合在一起。我们的数据呈指数级增长(每隔几天翻一番), w397090770 3年前 (2022-03-18) 363℃ 0评论1喜欢
在实践经验中,我们知道数据总是在不断演变和增长,我们对于这个世界的心智模型必须要适应新的数据,甚至要应对我们从前未知的知识维度。表的 schema 其实和这种心智模型并没什么不同,需要定义如何对新的信息进行分类和处理。这就涉及到 schema 管理的问题,随着业务问题和需求的不断演进,数据结构也会不断发生变化。 w397090770 4年前 (2020-09-12) 579℃ 0评论0喜欢
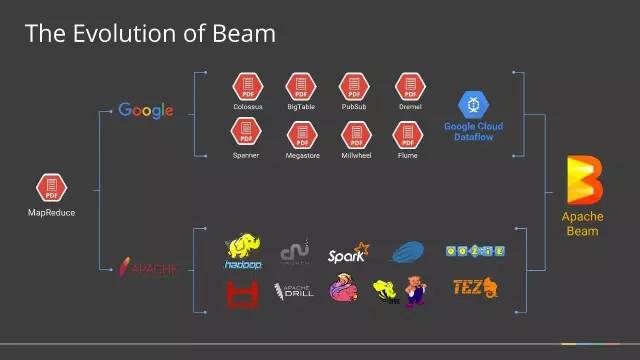
1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源。 2003年,谷歌发布了著名的大数据三篇论文,史称三驾马车:Google FS、MapReduce、BigTable。虽然谷歌没有公布这三个产品的源码,但是她这三个产品的详细设计论文开启了全球的大数据时代!从Doug Cutting大神根据 w397090770 8年前 (2017-02-10) 1801℃ 0评论4喜欢
2014年7月11日,Spark 1.0.1已经发布了,原文如下:We are happy to announce the availability of Spark 1.0.1! This release includes contributions from 70 developers. Spark 1.0.0 includes fixes across several areas of Spark, including the core API, PySpark, and MLlib. It also includes new features in Spark’s (alpha) SQL library, including support for JSON data and performance and stability fixes.Visit the relea w397090770 10年前 (2014-07-13) 6880℃ 0评论4喜欢
Apache Maven,是一个软件(特别是Java软件)项目管理及自动构建工具,由Apache软件基金会所提供。基于项目对象模型(缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建、报告和文档等步骤。曾是Jakarta项目的子项目,现为独立Apache项目。 那么,如何在Linux平台下面安装Maven呢?下面以CentOS平台为例,说明如 w397090770 11年前 (2013-10-21) 32225℃ 3评论13喜欢
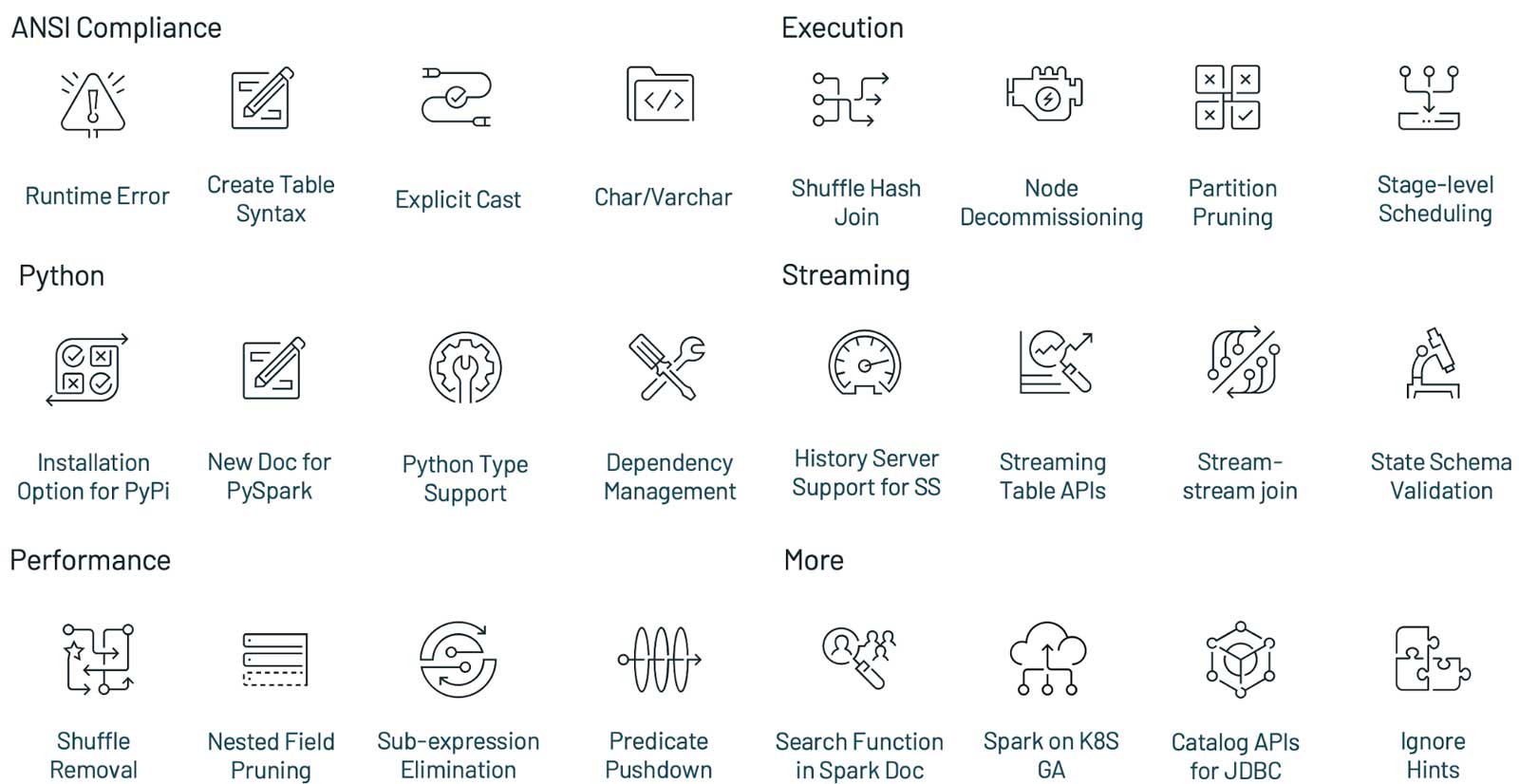
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 4年前 (2021-03-03) 2274℃ 0评论10喜欢
最近一段时间在做一个管理系统,在网上找了很久的前端展示框架,终于找到一款基于Bootstrap的后台管理系统模版:Ace。Bootstrap是Twitter 于2010年开发出来的前端框架,用过的同学应该知道,这款前端框架不仅界面很美观,而且兼容了很多的浏览器,大大加速了我们开发网站的速度!这篇文章讲到的Ace是基于Bootstrap的,所以界面自然 w397090770 10年前 (2015-01-19) 172226℃ 15评论459喜欢
数据分析中将两个数据集进行 Join 操作是很常见的场景。我在 这篇 文章中介绍了 Spark 支持的五种 Join 策略,本文我将给大家介绍一下 Apache Spark 中支持的 Join 类型(Join Type)。目前 Apache Spark 3.0 版本中,一共支持以下七种 Join 类型:INNER JOINCROSS JOINLEFT OUTER JOINRIGHT OUTER JOINFULL OUTER JOINLEFT SEMI JOINLEFT ANTI JOIN在实现上 w397090770 4年前 (2020-10-25) 1512℃ 0评论6喜欢
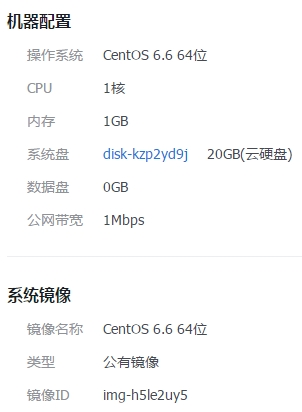
随着过往记忆大数据技术博客的浏览量逐渐增多(目前日IP达到5k+,PV达到1.5W+),博客的访问速度越来越慢,在高峰时期打开一个页面需要近10s的时间,这样的情况非常的糟糕,没多少人愿意等待近10s,所以优化网站的访问速度迫在眉睫! 先来介绍一下本博客的相关配置信息:博客购买的是腾讯云主机,CentOS 6.6 64位、1 w397090770 8年前 (2016-07-19) 1708℃ 0评论4喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13073℃ 5评论18喜欢
Hive 1.2.1源码编译依赖的Hadoop版本必须最少是2.6.0,因为里面用到了Hadoop的org.apache.hadoop.crypto.key.KeyProvider和org.apache.hadoop.crypto.key.KeyProviderFactory两个类,而这两个类在Hadoop 2.6.0才出现,否者会出现以下编译错误:[ERROR] /home/q/spark/apache-hive-1.2.1-src/shims/0.23/src/main/java/org/apache/hadoop/hive/shims/Hadoop23Shims.java:[43,36] package org.apache.hadoop.cry w397090770 9年前 (2015-11-11) 13620℃ 11评论6喜欢
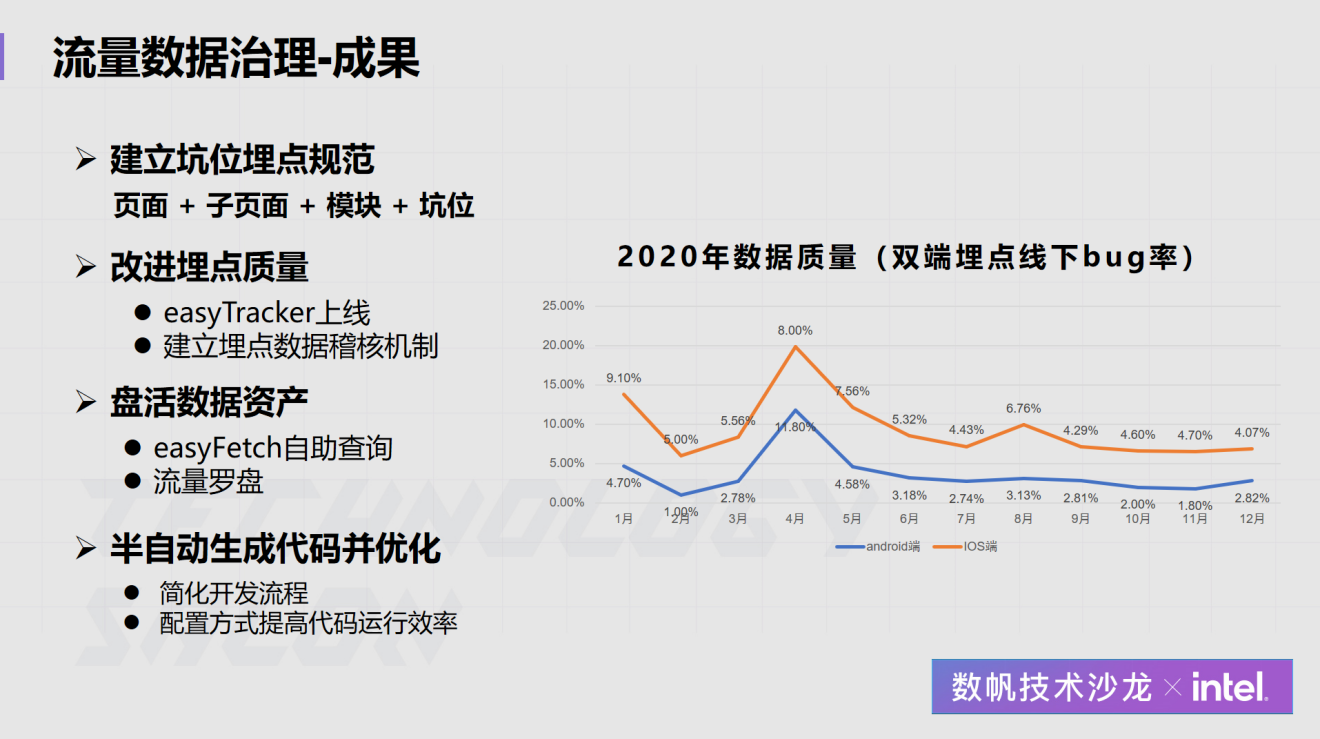
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 3年前 (2021-06-30) 975℃ 0评论1喜欢
Resources提供提供操作classpath路径下所有资源的方法。除非另有说明,否则类中所有方法的参数都不能为null。虽然有些方法的参数是URL类型的,但是这些方法实现通常不是以HTTP完成的;同时这些资源也非classpath路径下的。 下面两个函数都是根据资源的名称得到其绝对路径,从函数里面可以看出,Resources类中的getResource函数 w397090770 11年前 (2013-09-25) 6491℃ 0评论4喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive提供三种可以改变环境 w397090770 11年前 (2013-12-24) 25303℃ 2评论10喜欢
几天前(2016年7月27日),Apache社区发布了Apache Mesos 1.0.0, 这是 Apache Mesos 的一个里程碑事件。相较于前面的版本, 1.0.0首先是改进了与 docker 的集成方式,弃用了 docker daemon;其次,新版本大力推进解决了接口规范化问题,新的 HTTP API 使得开发者能够更容易的开发 Mesos 框架;最后, 为了更好的满足企业用户的多租户,安全,审 w397090770 8年前 (2016-07-31) 2026℃ 0评论2喜欢
很多人在面试中会被问到这样的题目,题目的含义是有如下的组合4=1+1+1+1、1+1+2、1+3、2+1+1、2+2。光从题目来看有两种理解: 将3 = 1 +2 和3 = 2 +1当作不同的组合。这种情况是比较简单的,直接将给定的n递归地分解成(n - 1) + 1当递归求得的结果和我们需要分解的整数n相等,则这次分解就完成了,我们可以把分解的组合输出来, w397090770 12年前 (2013-05-16) 3925℃ 0评论3喜欢
Apache Kafka 2.5.0 稳定版于美国当地时间2020年4月15日正式发布,这个版本包含了一系列的重要功能发布,比较重要的可以特性重要包括:支持 TLS 1.3 (目前默认是用 1.2)Kafka Streams DSL 中支持 Co-groups; Kafka Consumer 支持增量再平衡(Incremental rebalance)为更好地洞察算子运行,引入了新的指标;Apache Zookeeper 升级到 3.5.7不再支持 Scala w397090770 4年前 (2020-04-19) 1615℃ 0评论3喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-19) 7357℃ 6评论10喜欢
此次活动参与方式:关注iteblog_hadoop公众号,并在这里评论区留言(认真写评论,增加上榜的机会)。活动截止至3月14日19:00,留言点赞数排名前5名的粉丝,各免费赠送一本《Druid实时大数据分析原理与实践》如果想及时了解Spark、Hadoop、Flink或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书简介Druid 作为一 w397090770 8年前 (2017-03-08) 1589℃ 0评论5喜欢
一、活动时间 北京第九次Spark Meetup活动将于2015年08月22日进行;下午14:00-18:00。二、活动地点 北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼三、活动内容 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and w397090770 9年前 (2015-08-07) 2839℃ 0评论1喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19770℃ 4评论92喜欢
我们是负责58同城商业广告变现的商业工程技术团队,负责竞价排名类广告系统研发,包含广告投放系统,广告检索系统,以及广告投放策略的研究、实现。在这里,你将面临严密的商业逻辑的挑战,高并发、大数据量的挑战,如何认知数据、应用数据的挑战。高级大数据研发工程师 工作职责:负责或参与58商业数据仓库 w397090770 4年前 (2020-05-21) 1359℃ 0评论8喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art w397090770 7年前 (2017-05-04) 1646℃ 0评论6喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 8年前 (2017-02-23) 2561℃ 0评论1喜欢
在《Kafka集群扩展以及重新分布分区》文章中我们介绍了如何重新分布分区,在那里面我们基本上把所有的分区全部移动了,其实我们完全没必要移动所有的分区,而移动其中部分的分区。比如我们想把Broker 1与Broker 7上面的分区数据互换,如下图所示:可以看出,只有Broker 1与Broker 7上面的分区做了移动。来看看移动分区之 w397090770 9年前 (2016-03-31) 3338℃ 0评论4喜欢
在前面的《Guava学习之Multimap》文章中我们谈到了Guava类库中的Multimap,其特点是存在在Multimap中的键值对可以不唯一;而我们又知道,在Java集合类库中有个Map,它的特点是存放的键(Key)是唯一的,而值(Value)可以不唯一,如果我们需要键(Key)和值(Value)都唯一,该怎么实现?这就是今天要谈的BiMap结构。 在过去,如 w397090770 11年前 (2013-07-10) 7176℃ 2评论2喜欢
在使用Maven打包工程运行的时候,有时会出现以下的异常:[code lang="bash"]-bash-4.1# java -cp iteblog-1.0-SNAPSHOT.jar com.iteblog.ClientException in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:287) at sun.security.util.SignatureFileVerifier.process(Signatu w397090770 9年前 (2016-01-20) 13248℃ 0评论9喜欢
Learning Spark这本书链接是完整版,和之前的预览版是不一样的,我不是标题党。这里提供的Learning Spark电子书格式是mobi、pdf以及epub三种格式的文件,如果你有亚马逊Kindle电子书阅读器,是可以直接阅读mobi、pdf。但如果你用电脑,也可以下载相应的PC版阅读器 。如果你需要阅读器,可以找我。如果想及时了解Spark、Hadoop或者Hbase相 w397090770 10年前 (2015-02-11) 50864℃ 305评论70喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 308℃ 0评论0喜欢
双重检查锁定模式(也被称为"双重检查加锁优化","锁暗示"(Lock hint)) 是一种软件设计模式用来减少并发系统中竞争和同步的开销。双重检查锁定模式首先验证锁定条件(第一次检查),只有通过锁定条件验证才真正的进行加锁逻辑并再次验证条件(第二次检查)。该模式在某些语言在某些硬件平台的实现可能是不安全的。有 w397090770 4年前 (2020-06-19) 849℃ 0评论4喜欢