近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL " rel="nofollow"]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4428℃ 0评论14喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章中简单地介绍了Spark 2.0带来的新技术等。Spark 2.0是Apache Spark的下一个主要版本。此版本在架构抽象、API以及平台的类库方面带来了很大的变化,为该框架明年的发展奠定了方向,所以了解Spark 2.0的一些特性对我们能够使用它有着非常重要的作用。本博客将对Spark 2.0进行一序列 w397090770 8年前 (2016-07-12) 9765℃ 4评论11喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 w397090770 8年前 (2017-02-23) 16263℃ 0评论12喜欢
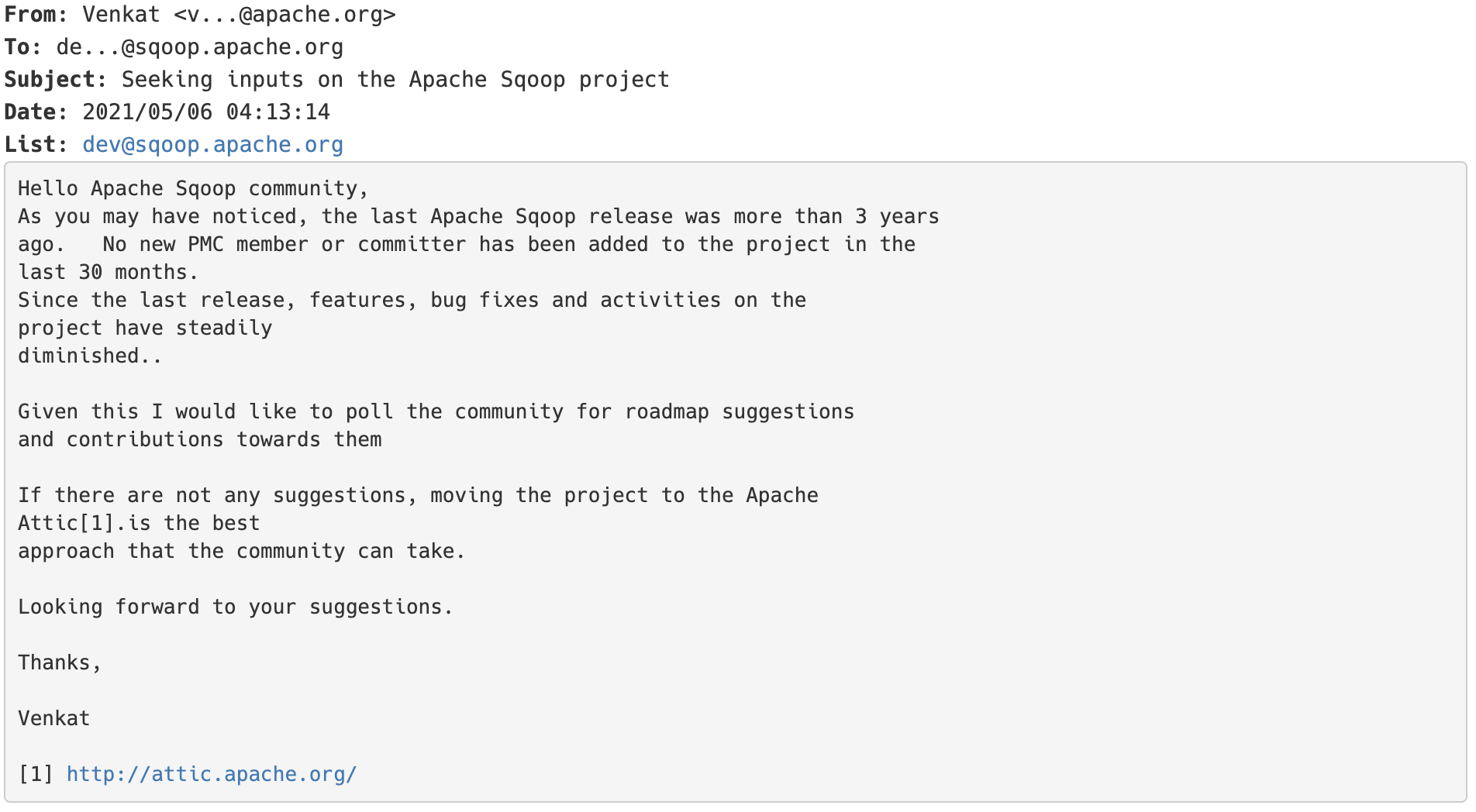
2021年05月06日,Apache Sqoop 的 PMC venkatrangan 给 Sqoop 项目的 dev 邮件列表发送了一篇名为《Seeking inputs on the Apache Sqoop project》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从邮件内容可以看出,Apache Sqoop 最后一次 release 的时间是三年前,最近30个月没有任何新的 PMC 和 committer 加入到 w397090770 3年前 (2021-06-27) 746℃ 0评论2喜欢
在Elasticsearch下,一个文档除了有数据之外,它还包含了元数据(Metadata)。每创建一条数据时,都会对元数据进行写入等操作,当然有些元数据是在创建mapping的时候就会设置,元数据在Elasticsearch下起到了非常大的作用。本文将对ElasticSearch中的元数据进行介绍,后续文章将分别对这些元数据进行解说。身份元数据(Identity meta-field w397090770 8年前 (2016-08-28) 4527℃ 0评论4喜欢
一般我们都是用SBT来维护Scala工程,但是在国内网络环境下,使用SBT来创建Scala工程一般都很难成功,或者等待很长的时间才创建完成,所以不建议使用。不过我们也是可以使用Maven来创建Scala工程。在命令行使用下面语句即可创建Scala工程:[code lang="bash"]/** * User: 过往记忆 * Date: 2015-05-24 * Time: 上午11:05 * bolg: * 本文地 w397090770 9年前 (2015-05-24) 23403℃ 1评论17喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 7年前 (2017-06-08) 4223℃ 0评论18喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* w397090770 6年前 (2018-07-24) 1490℃ 0评论4喜欢
经过一晚上的奋战终于通过调用新浪登录的登录API替代Wordpress内置的登录注册模块。只要你有新浪微博帐号即可绑定到本博客。添加微博登录功能主要解决两个问题:(1)、方便用户登录/注册;(2)、防止机器人注册本网站。以下是登录页面图: 点击上面使用微博帐号登录即可调用微博登录。如果你是第一次登录,需 w397090770 10年前 (2015-04-04) 4967℃ 0评论3喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2303℃ 0评论9喜欢
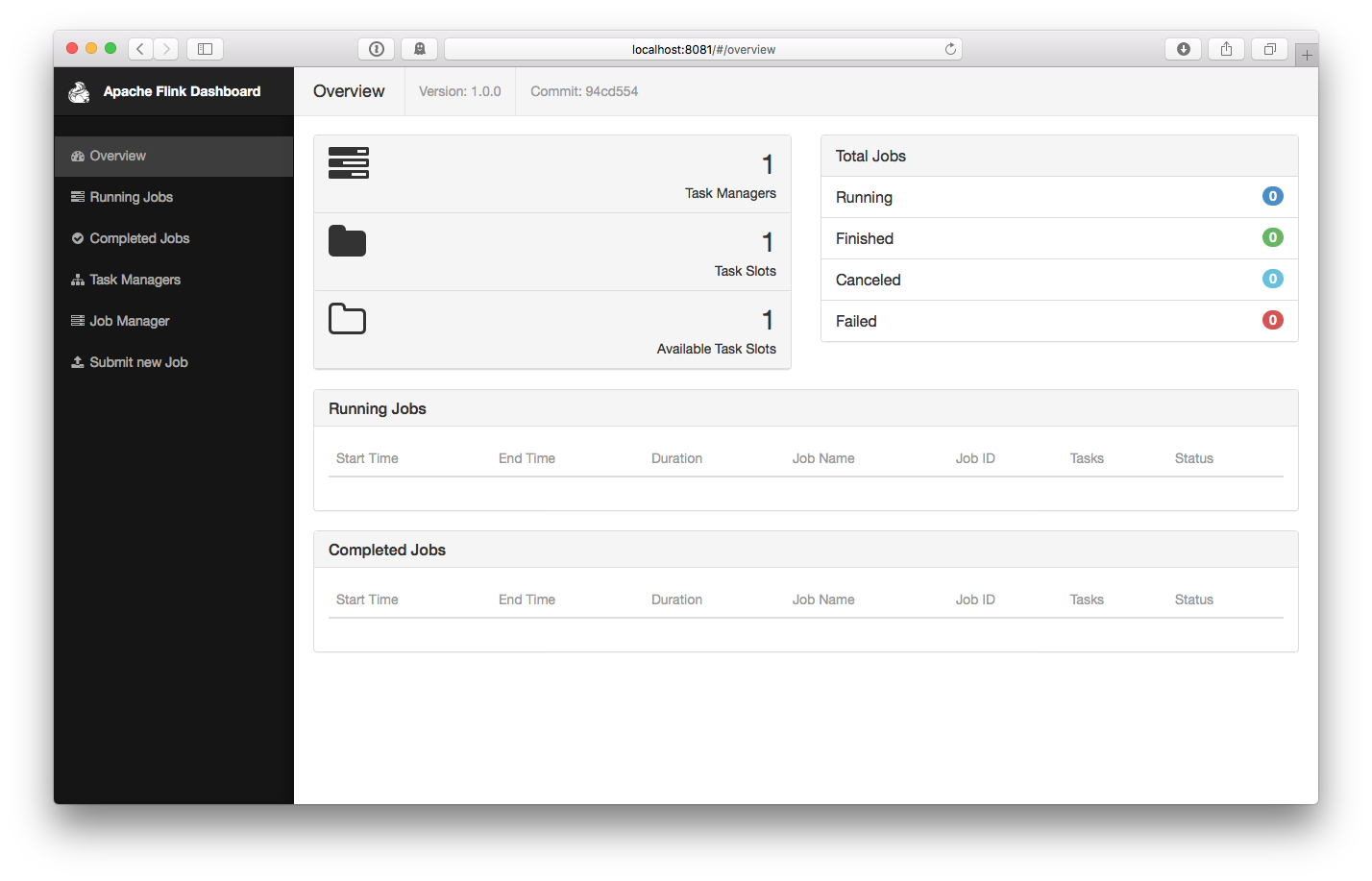
安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结 w397090770 9年前 (2016-04-05) 17696℃ 0评论23喜欢
Spark 1.2.0于美国时间2014年12月18日发布,Spark 1.2.0兼容Spark 1.0.0和1.1.0,也就是说不需要修改代码即可用,很多默认的配置在Spark 1.2发生了变化 1、spark.shuffle.blockTransferService由nio改成netty 2、spark.shuffle.manager由hash改成sort 3、在PySpark中,默认的batch size改成0了, 4、Spark SQL方面做的修改: spark.sql.parquet.c w397090770 10年前 (2014-12-19) 4595℃ 1评论2喜欢
Flink 是一种非常复杂的框架,它提供了多种调整其执行的方法。本文将介绍四种不同的方法来提升你的 Flink 应用程序的性能。使用 Flink Tuples当你使用类似于 groupBy, join, 或者 keyBy 算子时,Flink 提供了多种用于在你的数据集上选择 key 的方法。你可以使用 key 选择函数,如下:[code lang="java"]// Join movies and ratings datasetsmovies.join w397090770 7年前 (2017-12-10) 5334℃ 0评论16喜欢
默认情况下,使用WordPress系统的博客登录页面都比较简单,登陆页面显示的logo是WordPress 的logo,链接也是WordPress的链接,如下图所示:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 值得高兴的是,WordPress博客系统为我们提供了很多钩子(hook)来自定义这些信息,比如Logo、链接、提 w397090770 8年前 (2016-09-03) 1906℃ 0评论6喜欢
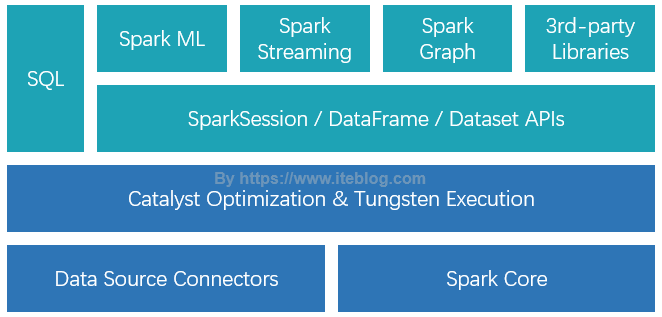
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 5年前 (2019-06-12) 10773℃ 0评论31喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16667℃ 1评论6喜欢
本书于2015年03月出版,全书共19页,这里是完整版。 w397090770 9年前 (2015-08-21) 1851℃ 0评论3喜欢
Apache Spark 2.4 与昨天正式发布,Apache Spark 2.4 版本是 2.x 系列的第五个版本。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Spark 2.4 为我们带来了众多的主要功能和增强功能,主要如下:新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中 w397090770 6年前 (2018-11-09) 3332℃ 0评论1喜欢
我们先来看看aggregate函数的官方文档定义:Aggregate the elements of each partition, and then the results for all the partitions, using given combine functions and a neutral "zero value". This function can return a different result type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U and one operation for merging two U's, as in scala.TraversableOnce. Both of these functions w397090770 10年前 (2015-02-12) 37385℃ 5评论23喜欢
一、首先到oracle的官网下载Berkeley db数据库源文件下载地址http://download.oracle.com/otn/berkeley-db/db-5.3.15.tar.gz二、下载之后的文件是一个打包好的文件,需要在命令行里面利用tar来解压(当然你也可以利用一些可视化工具来解压),步骤如下在命令行里面输入[code lang="CPP"] tar -zxvf db-5.3.15.tar.gz[/code]解压之后进入db-5.3.15目录有以下 w397090770 12年前 (2013-04-04) 3942℃ 0评论0喜欢
在本博客的《Apache Kafka-0.8.1.1源码编译》文章中简单地谈到如何用gradlew或sbt编译Kafka 0.8.1.1的代码。今天主要来谈谈如何部署一个分布式集群。以下本文所有的内容都是基于Kafka 0.8.1.1(Kafka 0.7.x的操作命令和本文略有不同,请注意!)在介绍Kafka分布式部署之前,先来了解一下Kafka的基本概念。 (1)Kafka维护按类区分的消息 w397090770 10年前 (2014-06-23) 19046℃ 0评论20喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 878℃ 0评论2喜欢
我们在使用Hadoop、Spark或者是Hbase,最常遇到的问题就是进行相关系统的配置,比如集群的URL地址,MapReduce临时目录、最终输出路径等。这些属性需要有一个系统(类)进行管理。然而,Hadoop没有使用 Java.util.Properties 管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是单独开发了一个配置文件管理类,这个类就 w397090770 8年前 (2017-04-21) 7707℃ 0评论18喜欢
Scala又一强大的功能就是可以以脚本的形式运行。我们可以创建一个测试文件iteblog.sh,内容如下:[code lang="scala"]#!/bin/shexec scala "$0" "$@"!#println("Hello, Welcome to !")[/code]然后我们就可以下面之一的方式运行这个Scala脚本:[code lang="scala"][iteblog@www.iteblog.com iteblog]$ sh scala.sh Hello, Welcome to ![/code] w397090770 9年前 (2015-12-11) 5690℃ 0评论8喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Scala 程序。构建工具 Flink工程可以使用不同的工具进行构建,为了快速构建Flink工程, Flink为下面的构建工具分别提供了模板: 1、SBT 2、Maven这些模板可以帮助我们组织项目结构并初始化一些构建文件。SBT创建工程1、使用Giter8可以使用下 w397090770 9年前 (2016-04-07) 10170℃ 0评论8喜欢
题目描述:输入两个整数序列。其中一个序列表示栈的push顺序,判断另一个序列有没有可能是对应的pop顺序。为了简单起见,我们假设push序列的任意两个整数都是不相等的。比如输入的push序列是1、2、3、4、5、6、7,那么2、1、4、3、7、6、5就有可能是一个pop系列。但序列4、3、5、1、2、7、6就不可能是push序列1、2、3、4、5的pop序列 w397090770 12年前 (2013-03-30) 4359℃ 0评论7喜欢
我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀 w397090770 9年前 (2016-04-04) 18101℃ 0评论42喜欢
在本博客的《使用Spark SQL读取Hive上的数据》文章中我介绍了如何通过Spark去读取Hive里面的数据,不过有时候我们在创建SQLContext实例的时候遇到类似下面的异常:[code lang="java"]java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(Se w397090770 9年前 (2016-01-11) 16415℃ 5评论14喜欢
一.问答题1、map方法是如何调用reduce方法的?2、fsimage和edit的区别?3、hadoop1和hadoop2的区别?4、列举几个配置文件优化?5、写出你对zookeeper的理解6、datanode首次加入cluster的时候,如果log报告不兼容文件版本,那需要namenode执行格式化操作,这样处理的原因是?7、hbase 集群安装注意事项二. 思考题1. linux w397090770 8年前 (2016-08-26) 3163℃ 0评论1喜欢
bsie是使得IE6可以支持Bootstrap的补丁,Bootstrap是 twitter.com 推出的非常棒web UI工具库。目前,bsie使得IE6能支持bootstrap大部分特性,可惜,还有一些实在无法支持...下面的这个表格就是当前已经被支持的bootstrap的组件和特性:[code lang="bash"]组件 特性-----------------------------------------------------------grid fixed, fluidnavbar w397090770 9年前 (2015-12-26) 2317℃ 7评论3喜欢