写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/好久没写Hive的那些事了,今 w397090770 11年前 (2014-02-19) 92554℃ 5评论132喜欢
下面所有的内容是针对Hadoop 2.x版本进行说明的,Hadoop 1.x和这里有点不一样。 在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:[code lang="JAVA"][wyp@wyp hadoop-2.2.0]$ $HADOOP_HOME/bin/hdfs namenode -format[/code] 格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构[code lang="JAVA"]c w397090770 11年前 (2014-03-04) 13290℃ 1评论17喜欢
如果你想搭建伪分布式Hadoop平台,请参见本博客《在Fedora上部署Hadoop2.2.0伪分布式平台》 经过好多天的各种折腾,终于在几台电脑里面配置好了Hadoop2.2.0分布式系统,现在总结一下如何配置。 前提条件: (1)、首先在每台Linux电脑上面安装好JDK6或其以上版本,并设置好JAVA_HOME等,测试一下java、javac、jps等命令 w397090770 11年前 (2013-11-06) 21278℃ 6评论27喜欢
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》 本文聚焦Apache Spark入门,了解其在大数据领域的地位,覆盖Apache Spark的安装及应用程序的建立,并解释一些常见的行为和操作。一、 为什么要选择Apache Spark 当前,我们正处在一个“大数据"的时代,每时每刻,都有各 w397090770 9年前 (2015-07-13) 6131℃ 1评论24喜欢
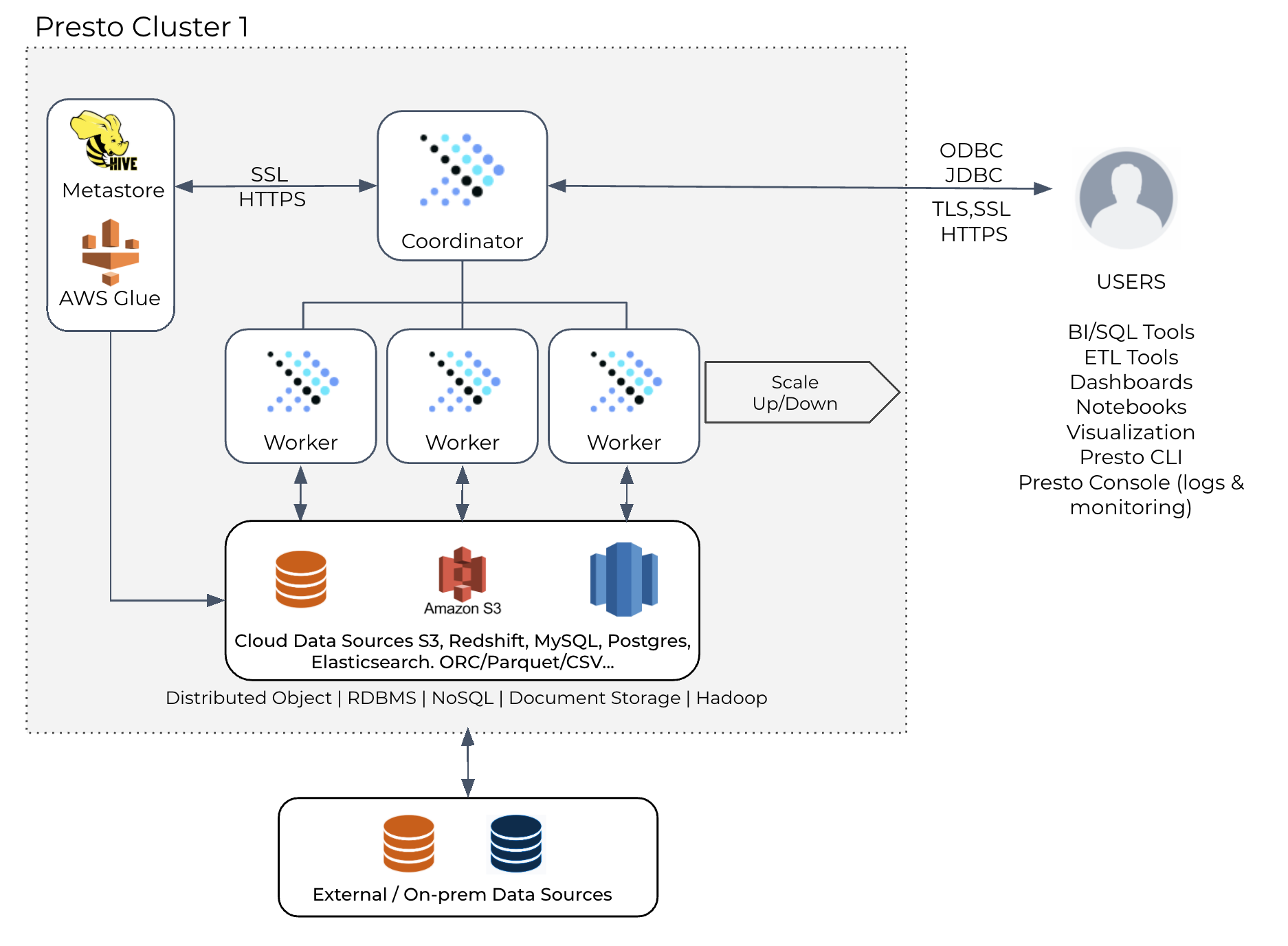
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Presto at Bytedance》,分享者常鹏飞,字节跳动软件工程师。Presto 在字节跳动中得到了广泛的应用,如数据仓库、BI工具、广告等。与此同时,字节跳动的 presto 团队也提供了许多重要的特性和优化,如 Hive UDF Wrapper、多个协调器、运行时过滤器等,扩展了 presto w397090770 3年前 (2021-12-14) 719℃ 0评论1喜欢
如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 10年前 (2014-09-10) 38700℃ 7评论32喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 8年前 (2016-07-25) 216066℃ 0评论844喜欢
概述Presto 最初设计是对数据仓库中的数据运行交互式查询,但现在它已经发展成为一个位于开放数据湖分析之上的统一 SQL 引擎,用于交互式和批处理工作负载,数据湖上的流行工作负载包括:报告和仪表盘:这包括为内部和外部开发人员提供自定义报告以获取业务洞察力,以及许多使用 Presto 进行交互式 A/B 测试分析的组织 w397090770 3年前 (2021-11-14) 1383℃ 0评论1喜欢
《Spark 2.0技术预览:更容易、更快速、更智能》文章介绍了Spark的三大新特性,本文是Reynold Xin在2016年5月5日的演讲,视频可以到这里看:http://go.databricks.com/apache-spark-2.0-presented-by-databricks-co-founder-reynold-xinPPT下载地址见下面。 w397090770 8年前 (2016-05-24) 3267℃ 0评论4喜欢
Solr 介绍Apache Solr 是基于 Apache Lucene™ 构建的流行,快速,开源的企业搜索平台。Solr 具有高可靠性,可扩展性和容错性,可提供分布式索引,复制和负载均衡查询,自动故障转移和恢复以及集中配置等特性。 Solr 为世界上许多大型互联网站点提供搜索和导航功能。Solr 是用 Java 编写、运行在 Servlet 容器(如 Apache Tomcat 或Jetty) w397090770 6年前 (2018-07-24) 2849℃ 0评论3喜欢
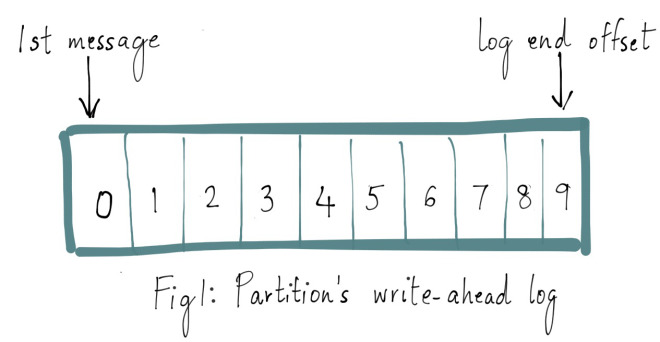
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 w397090770 5年前 (2019-05-26) 5104℃ 1评论14喜欢
TPCH(商业智能计算测试) 是美国交易处理效能委员会(TPC,Transaction Processing Performance Council) 组织制定的用来模拟决策支持类应用的一个测试集。目前在学术界和工业界普遍采用它来评价决策支持技术方面应用的性能。这种商业测试可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义, w397090770 7年前 (2017-12-10) 565℃ 0评论1喜欢
本视频是炼数成金的Spark大数据平台视频,本课程在总结上两期课程的经验,对课程重新设计并将更新过半的内容,将最新版的spark1.1.0展现给有兴趣的学员。 更新:由于版权问题,本视频不提供下载地址,敬请理解。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时 w397090770 10年前 (2015-03-24) 56872℃ 18评论99喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 w397090770 4年前 (2021-02-02) 632℃ 0评论3喜欢
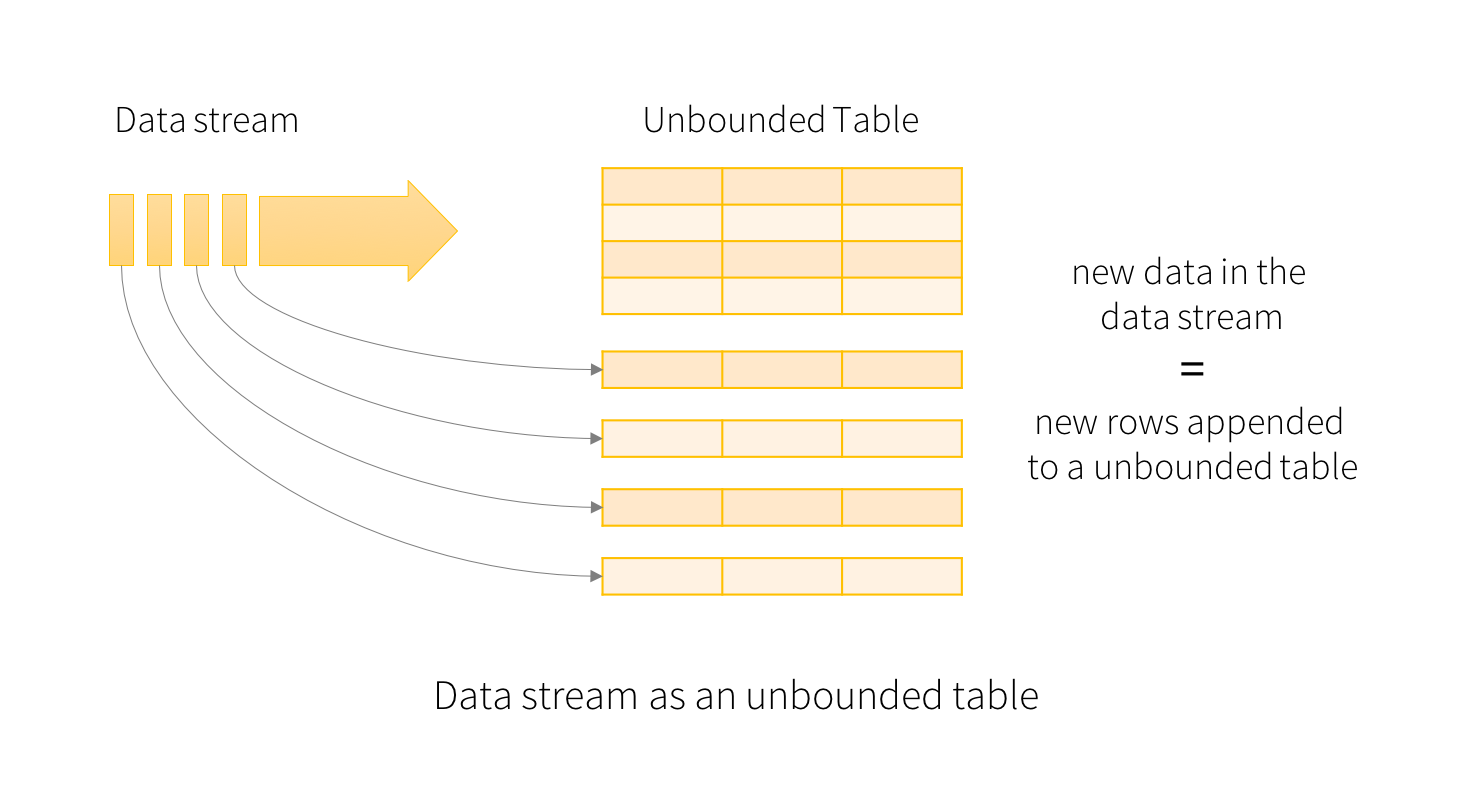
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10754℃ 2评论11喜欢
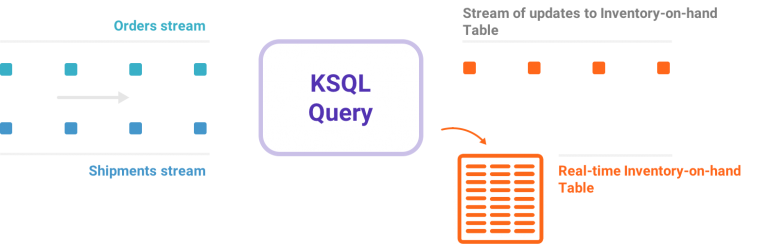
我非常高兴地宣布KSQL,这是面向Apache Kafka的一种数据流SQL引擎。KSQL降低了数据流处理这个领域的准入门槛,为使用Kafka处理数据提供了一种简单的、完全交互的SQL界面。你不再需要用Java或Python之类的编程语言编写代码了!KSQL具有这些特点:开源(采用Apache 2.0许可证)、分布式、可扩展、可靠、实时。它支持众多功能强大的数据流 w397090770 7年前 (2017-08-30) 7900℃ 0评论22喜欢
本博客盘点了过去两年晋升为 Apache TLP(Apache Top-Level Project) 的大数据相关项目,具体参见《盘点2017年晋升为Apache TLP的大数据相关项目》、《盘点2018年晋升为Apache TLP的大数据相关项目》,继承这个惯例,本文将给大家盘点2019年晋升为 Apache TLP 的大数据相关项目,由于今年晋升成 TLP 的大数据项目很少,只有三个,而且其中两个好 w397090770 5年前 (2019-12-30) 2208℃ 0评论7喜欢
关于 Apache Spark 2.2.0 的详细新功能介绍请参见:《Apache Spark 2.2.0新特性详细介绍》Apache Spark 2.2.0 持续了半年的开发,从RC1 到 RC6 终于在今天正式发布了。本版本是 2.x 版本线的第三个版本。在这个版本 Structured Streaming 的实验性标记(experimental tag)已经被移除,这也意味着后面的 2.2.x 之后就可以放心在线上使用了。除此之外,这 w397090770 7年前 (2017-07-12) 2814℃ 0评论8喜欢
在社会关系网中,入度越多的实体权威性越大;反之则越小。从上面的定义可以看出,权威性的衡量必须在有向图中进行,无向图是没有权威性的概念,不过无向图中可以用中心度去衡量实体的重要性。目前,比较常见的用于计算结点权威性的模型主要有三种:度权威(Degree Prestige)、邻近权威(Proximity Prestige)以及等级权威(Rank w397090770 11年前 (2013-05-30) 4077℃ 1评论5喜欢
我们在接触Hadoop的时候,第一个列子一般是运行Wordcount程序,在Spark我们可以用Java代码写一个Wordcount程序并部署在Yarn上运行。我们知道,在Spark源码中就存在一个用Java编写好的JavaWordCount程序,源码如下:[code lang="JAVA"]package org.apache.spark.examples;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apac w397090770 11年前 (2014-05-04) 28313℃ 1评论19喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2286℃ 0评论2喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); w397090770 6年前 (2018-11-10) 4506℃ 0评论6喜欢
rest 接口 现在我们已经有一个正常运行的节点(和集群),下一步就是要去理解怎样与其通信。幸运的是,Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同你的集群交互。下面是利用这个API,可以做的几件事情: 1、查你的集群、节点和索引的健康状态和各种统计信息 2、管理你的集群、节点、 zz~~ 8年前 (2016-08-31) 1427℃ 0评论2喜欢
点击试试使用Github登录我博客。 随着使用Github的人越来越多,为自己的网站添加Github登录功能也越来越有必要了。Github开放了登录API,第三方网站可以通过调用Github的OAuth相关API读取到登录用户的基本信息,从而使得用户可以通过Github登录到我们的网站。今天来介绍一下如何使用Github的OAuth相关API登录到Wordpress。 w397090770 10年前 (2015-04-12) 11934℃ 9评论12喜欢
我们知道,HDFS 被设计成存储大规模的数据集,我们可以在 HDFS 上存储 TB 甚至 PB 级别的海量数据。而这些数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及文件块, w397090770 6年前 (2018-10-09) 9291℃ 2评论31喜欢
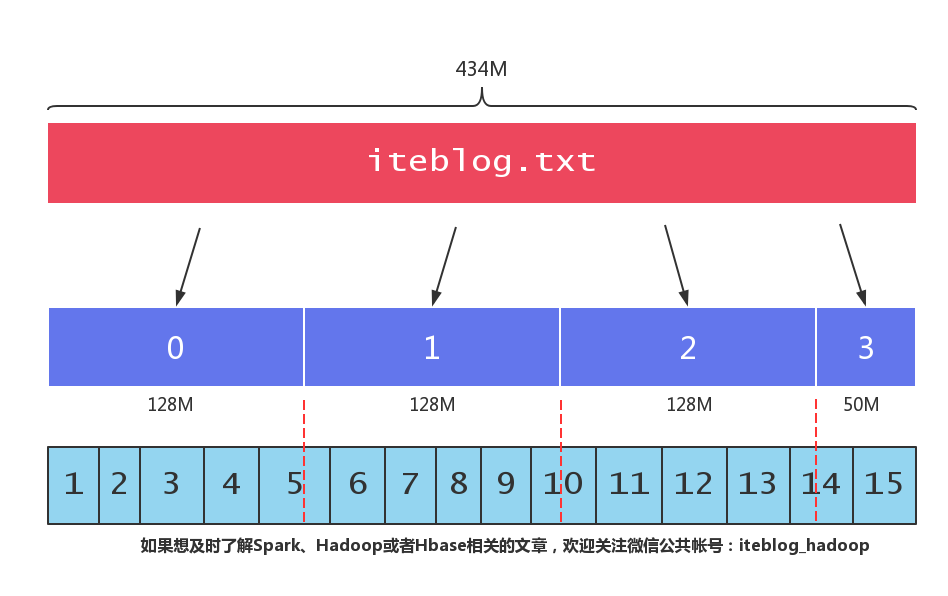
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 6年前 (2018-05-16) 2666℃ 4评论28喜欢
使用用户设置好的聚合函数对每个Key中的Value进行组合(combine)。可以将输入类型为RDD[(K, V)]转成成RDD[(K, C)]。函数原型[code lang="scala"]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C) : RDD[(K, C)]def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, numPartitio w397090770 10年前 (2015-03-19) 22566℃ 0评论23喜欢
2013年10月15号,Hadoop已经升级到2.2.0稳定版了,同时带来了很多新的特性,本人所在的公司经过一个月时间对Hadoop2.2.0的测试,在确保对业务没有影响的前提下将Hadoop集群顺利的升级到Hadoop2.2.0版本,本文主要介绍如何从Hadoop1.x(本博客用到的是hadoop-0.20.2-cdh3u4)版本的集群顺利地升级到Hadoop2.2.0。友情提示:请在读下文之间认真 w397090770 11年前 (2013-12-02) 12599℃ 2评论8喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive的设计目的是为了那 w397090770 11年前 (2014-01-06) 16061℃ 2评论8喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 878℃ 0评论2喜欢