Apache Pinot 是一个分布式实时分布式 OLAP 数据存储,旨在以高吞吐量和低延迟提供可扩展的实时分析。该项目最初于 2013 年由 LinkedIn 创建,2015 年开源,于 2018 年 10 月进入 Apache 孵化器,2021年08月02日正式毕业成为 Apache 顶级项目。Apache Pinot 可以直接从流数据源(例如 Apache Kafka 和 Amazon Kinesis)中提取,并使事件可用于即时查询。 w397090770 3年前 (2022-01-01) 962℃ 0评论1喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca w397090770 3年前 (2021-11-01) 782℃ 0评论3喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19109℃ 3评论15喜欢
在这篇我们介绍了 Spark Delta Lake 0.4.0 的发布,并提到这个版本支持 Python API 和部分 SQL。本文我们将详细介绍 Delta Lake 0.4.0 Python API 的使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在本文中,我们将基于 Apache Spark™ 2.4.3,演示一个准时航班情况业务场景中,如何使用全新的 Delta Lake 0.4.0 w397090770 5年前 (2019-10-04) 963℃ 0评论1喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书籍分 w397090770 11年前 (2013-12-02) 87925℃ 59评论297喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-03-23) 6635℃ 0评论3喜欢
1.hbase怎么预分区?2.hbase怎么给web前台提供接口来访问?3.htable API有没有线程安全问题,在程序中是单例还是多例?4.hbase有没有并发问题?5.metaq消息队列,zookeeper集群,storm集群,就可以完成对商城推荐系统功能吗?还有没有其他的中间件?6.storm 怎么完成对单词的计数?7.hdfs的client端,复制到第三个副本时宕机, w397090770 8年前 (2016-08-26) 4144℃ 0评论2喜欢
2021年01月21日,Apache 官方博客宣布 Apache® Superset™ 成为顶级项目。Apache® Superset™ 是一个现代化的大数据探索和可视化平台,它允许用户使用简单的无代码可视化构建器和最先进的 SQL 编辑器轻松快速地构建仪表盘(dashboards)。该项目于2015年在 Airbnb 启动,并于2017年5月进入 Apache 孵化器。说白了,其实 Apache Superset 算是一个大数据 w397090770 4年前 (2021-01-22) 756℃ 0评论1喜欢
Apache Flume: Distributed Log Collection for Hadoop于2013年07月出版,全书共108页。 w397090770 9年前 (2015-08-25) 2851℃ 1评论4喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 6年前 (2018-07-22) 9635℃ 0评论10喜欢
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting牵头开发。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。 在Hive中,我们可以将数据 w397090770 11年前 (2014-04-08) 15806℃ 1评论6喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相关属性绝大多数的属性控制应用程序的内部设置,并且默认值 w397090770 10年前 (2014-09-25) 18040℃ 1评论20喜欢
Splitter:在Guava官方的解释为:Extracts non-overlapping substrings from an input string, typically by recognizing appearances of a separator sequence. This separator can be specified as a single character, fixed string, regular expression or CharMatcher instance. Or, instead of using a separator at all, a splitter can extract adjacent substrings of a given fixed length. w397090770 11年前 (2013-09-09) 7068℃ 1评论0喜欢
Hadoop分布式文件系统实现了一个和POSIX系统类似的文件和目录的权限模型。每个文件和目录有一个所有者(owner)和一个组(group)。文件或目录对其所有者、同组的其他用户以及所有其他用户分别有着不同的权限。对文件而言,当读取这个文件时需要有r权限,当写入或者追加到文件时需要有w权限。对目录而言,当列出目录内容 w397090770 9年前 (2016-03-21) 7902℃ 9喜欢
Java 8 流的新类 java.util.stream.Collectors 实现了 java.util.stream.Collector 接口,同时又提供了大量的方法对流 ( stream ) 的元素执行 map and reduce 操作,或者统计操作。本章节,我们就来看看那些常用的方法,顺便写几个示例练练手。Collectors.averagingDouble()Collectors.averagingDouble() 方法将流中的所有元素视为 double 类型并计算他们的平均值 w397090770 3年前 (2022-03-31) 175℃ 0评论1喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在《Hive内置数据类型》文章中,我们提到了Hive w397090770 11年前 (2014-01-07) 139346℃ 1评论481喜欢
在默认情况下,Wordpress是不带有博客访问或者是博文的访问次数的,这对于某些人(比如我)来说是很不喜欢的,我想统计一下我博客或者博文到底被人家看了多少次。如下图所示: 在前面的两篇博文中(为WordPress的suffusion主题添加文章浏览次数,怎么给wordPress3.5.1添加文章统计)谈到了如何给博文添加访客浏览记录。 w397090770 12年前 (2013-04-30) 7945℃ 2评论9喜欢
MongoDB 4.2 稳定版于近日正式发布了,此版本带来了许多最大的特性,比如分布式事务(Distributed Transactions)、客户端字段级别加密(Client-Side Field-Level Encryption)、按需物化视图(On-Demand Materialized Views)以及通配符索引(Wildcard Indexes)。下面我们来简单介绍一下各个新特性。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 5年前 (2019-08-18) 1978℃ 0评论3喜欢
Apache Spark 发布了 Delta Lake 0.4.0,主要支持 DML 的 Python API、将 Parquet 表转换成 Delta Lake 表 以及部分 SQL 功能。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面详细地介绍这些功能部分功能的 SQL 支持SQL 的支持能够为用户提供极大的便利,如果大家去看数砖的 Delta Lake 产品,你肯定已 w397090770 5年前 (2019-10-01) 1292℃ 0评论4喜欢
这次整理的 PPT 来自于2018年09月03日至05日在 Berlin 进行的 flink forward 会议,这种性质的会议和大家熟知的Spark summit类似。本次会议的官方日程参见:https://berlin-2018.flink-forward.org/。本次会议共有超过350个 Flink 社区会员的人参与,因为原始的 PPT 是在 http://www.slideshare.net/ 网站,这个网站需要翻墙;为了学习交流的方便,本博客将这些 P w397090770 6年前 (2018-09-19) 2589℃ 2评论5喜欢
流处理系统月刊是一份专门收集关于Spark、Flink、Kafka、Apex等流处理系统的技术干货月刊,完全免费,每天更新,欢迎关注。下面资源如无法正常访问,请使用《最新可访问Google的Hosts文件》或《Tunnello:免费的浏览器翻墙插件》进行科学上网。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoo w397090770 8年前 (2016-10-07) 4348℃ 0评论5喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 9年前 (2015-08-06) 11307℃ 6评论29喜欢
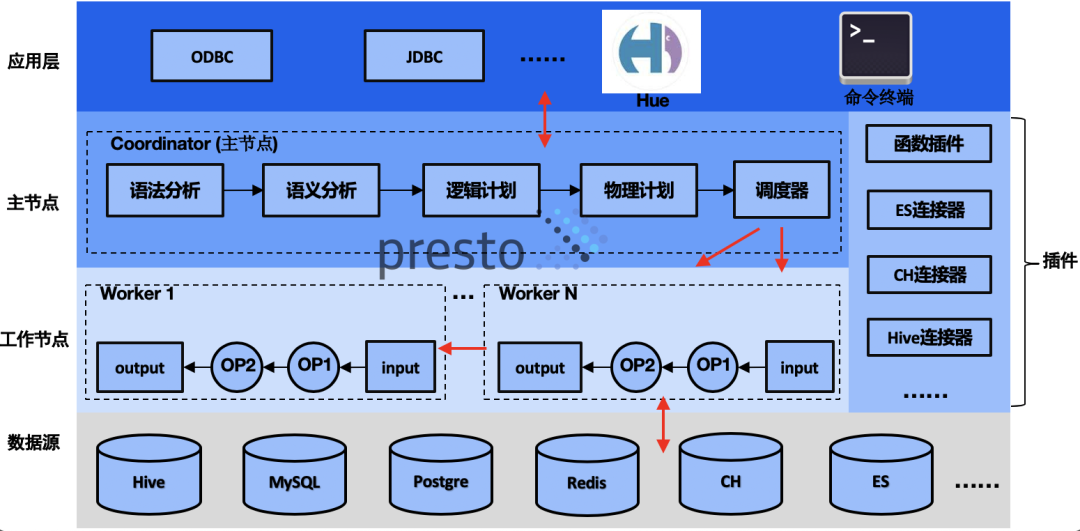
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 3年前 (2021-09-08) 536℃ 0评论1喜欢
本文为阿里巴巴技术专家余根茂在社区发的一篇文章。Structured Streaming 最初是在 Apache Spark 2.0 中引入的,它已被证明是构建分布式流处理应用程序的最佳平台。SQL/Dataset/DataFrame API 和 Spark 的内置函数的统一使得开发人员可以轻松实现复杂的需求,比如支持流聚合、流-流 Join 和窗口。自从 Structured Streaming 发布以来,社区的开发人 w397090770 4年前 (2020-07-30) 738℃ 0评论1喜欢
使用 MAC 写移动硬盘的时候会出现 Read-only file system,我们可以使用下面方法来解决。[code code="bash"]iteblog: iteblog $ diskutil info /Volumes/Seagate\ Backup\ Plus\ Drive/ Device Identifier: disk2s1 Device Node: /dev/disk2s1[/code]记下上面的 Device Node。然后使用下面命令弹出我们插入的移动硬盘:[code code="bash"]iteblog: iteblog $ hdiutil eje w397090770 4年前 (2021-01-05) 2238℃ 0评论2喜欢
背景 舜飞科技的各个业务线对接全网的各大媒体及APP,从而产生大量数据,实时分析这些数据不仅仅用于监控业务的发展,还会影响产品的服务质量,直接创造价值。比如优化师要时刻关注活动的投放质量,竞价算法会根据投放数据实时调整策略,网站主会进行流量分析和快速事故反馈等等。这些分析需求的特点: 1 w397090770 8年前 (2017-01-03) 4622℃ 0评论6喜欢
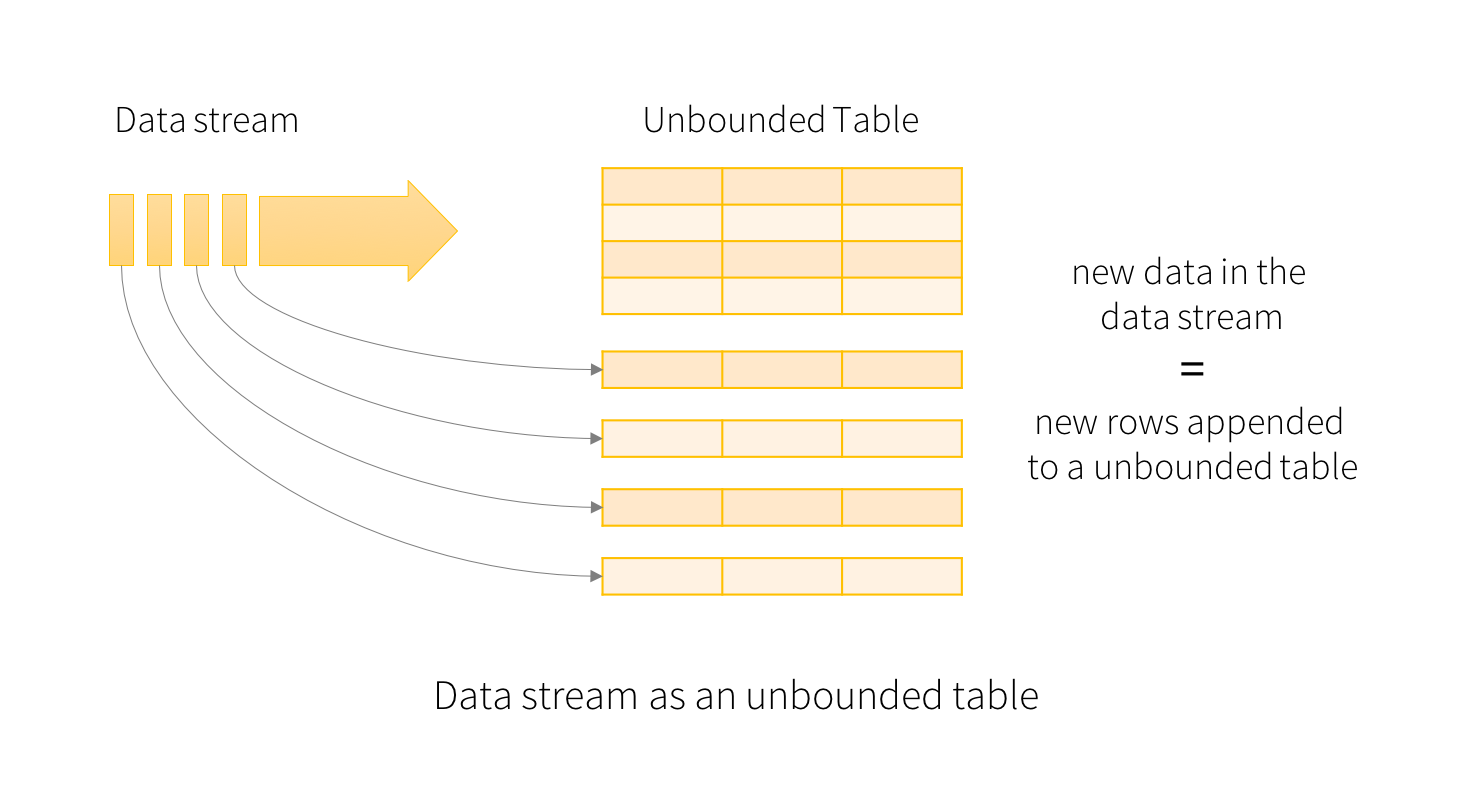
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10754℃ 2评论11喜欢
活动时间 1月24日下午14:00活动地点 地址:海淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 地图:http://j.map.baidu.com/L_1hq 为了保证大家乘车方便,特提供活动大巴时间:13:20-13:40位置:http://j.map.baidu.com/SJOLy分享内容: 邵赛赛 Intel Spark Streaming driver high availability w397090770 10年前 (2015-01-22) 15586℃ 0评论2喜欢
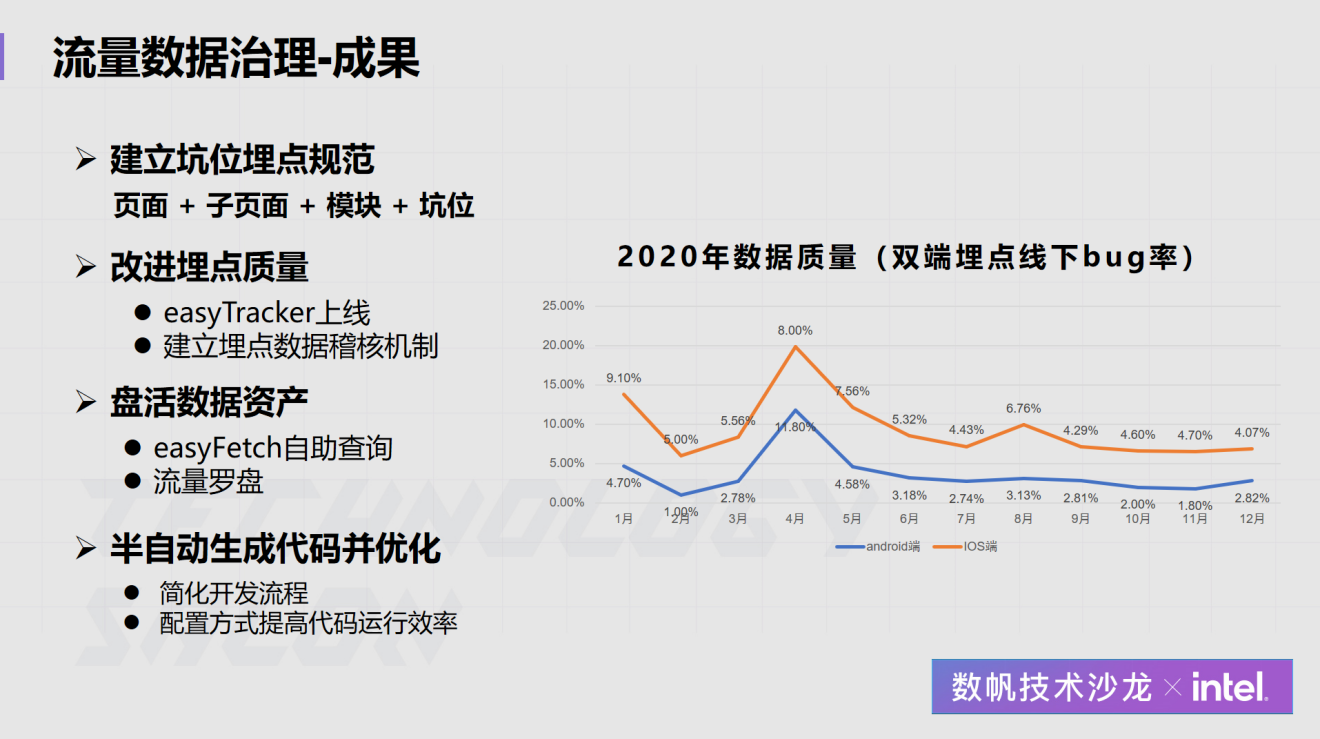
网易云音乐作为一个MAU已经超过亿级的业务,在数据仓库、数据体系、数据应用建设是怎么做的?在近日举办的“网易数帆技术沙龙”上,网易云音乐数据专家雷剑波就此话题做了全面的分享,介绍了数仓建设的目标,为此建立的一系列规范和机制,如何通过系统保证这些规范和机制的落地,以及取得的效果。数仓建设痛点与目 w397090770 3年前 (2021-06-30) 975℃ 0评论1喜欢
《Spark on YARN集群模式作业运行全过程分析》《Spark on YARN客户端模式作业运行全过程分析》《Spark:Yarn-cluster和Yarn-client区别与联系》《Spark和Hadoop作业之间的区别》《Spark Standalone模式作业运行全过程分析》(未发布) 在前篇文章中我介绍了Spark on YARN集群模式(yarn-cluster)作业从提交到运行整个过程的情况(详情见《Spar w397090770 10年前 (2014-11-04) 19556℃ 5评论12喜欢