本文英文原文:https://hudi.apache.org/releases.html下载信息源码:Apache Hudi 0.6.0 Source Release (asc, sha512)二进制Jar包:nexus如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2. 迁移指南如果您从0.5.3以前的版本迁移至0.6.0,请仔细核对每个版本的迁移指南;0.6.0版本从基于list的rollback策略变更为 w397090770 4年前 (2020-09-02) 898℃ 0评论0喜欢
本文转载自:http://blog.cloudera.com/blog/2014/04/how-to-run-a-simple-apache-spark-app-in-cdh-5/(Editor’s note – this post has been updated to reflect CDH 5.1/Spark 1.0)Apache Spark is a general-purpose, cluster computing framework that, like MapReduce in Apache Hadoop, offers powerful abstractions for processing large datasets. For various reasons pertaining to performance, functionality, and APIs, Spark is already be w397090770 10年前 (2014-07-18) 20170℃ 3评论9喜欢
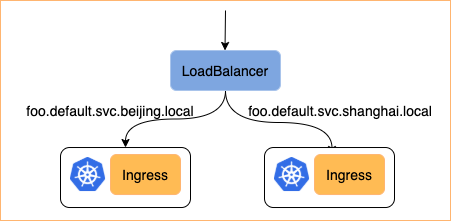
基于Kubefed的多集群管理实践多集群场景主要分以下几个方面:1)高可用低延时:应用部署到不同的集群去做高可用2)容灾备份:特别是针对于数据库这类的应用 在a集群对外提供服务的同时给b集群做一次备份 这样在发生故障的时候 可以无缝的迁移到另一个集群去3)业务隔离:尽管kubernetes提供了ns级别的隔离, zz~~ 3年前 (2021-09-24) 260℃ 0评论0喜欢
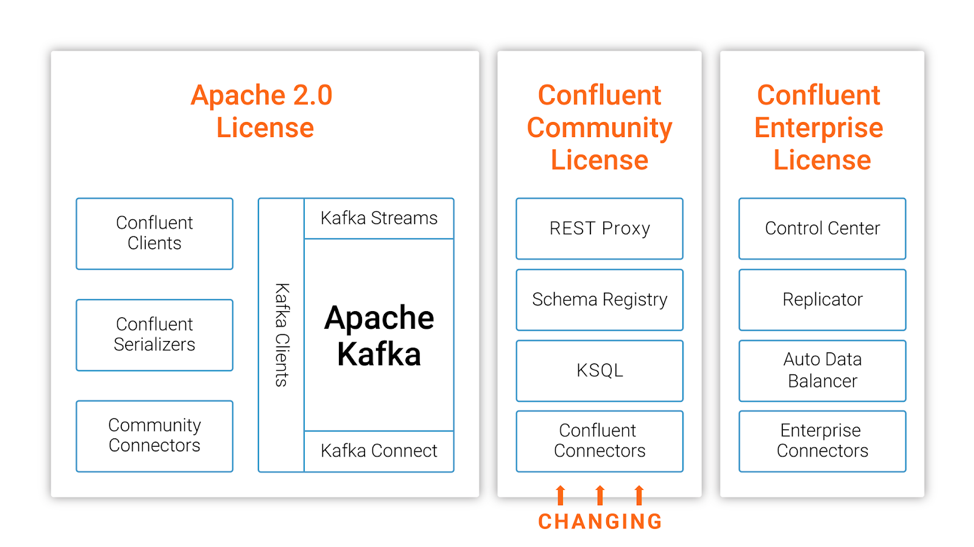
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 6年前 (2018-12-15) 2009℃ 0评论3喜欢
Apache Spark于北京时间2015年07月16日05点正式发布。Spark 1.4.1主要是维护版本,包含了大量的稳定性修复。该版本是基于branch-1.4分支。社区推荐所有1.4.0使用升级到这个稳定版本。此版本有85位开发者参与。 Spark 1.4.1包含了大量的Bug修复,这些Bug出现在Spark的DataFrame、外部数据源支持以及其他组建的一些bug修复。一些比较重要 w397090770 9年前 (2015-07-16) 4370℃ 0评论10喜欢
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个广泛应用于统计计算和统计制图的优秀编程语言,但是其交互式使用通常局限于一台机器。为了能够使用R语言分析大规模分布式的数据,UC Berkeley给我们带来了SparkR,SparkR就是用R语言编写Spark程序,它允许数据科学家分析 w397090770 10年前 (2015-04-14) 12953℃ 0评论17喜欢
为了方便集群的部署,一般我们都会构建出一个 dokcer 镜像,然后部署到 k8s 里面。Presto、Prestissimo 以及 Velox 也不例外,本文将介绍如果构建 presto 以及 Prestissimo 的镜像。构建 Presto 镜像Presto 官方代码里面其实已经包含了构建 Presto 镜像的相关文件,具体参见 $PRESTO_HOME/docker 目录:[code lang="bash"]➜ target git:(velox_docker) ✗ ll ~/ w397090770 1年前 (2023-06-21) 477℃ 0评论8喜欢
导言本文主要介绍如何快速的通过Spark访问 Iceberg table。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark通过DataSource和DataFrame API访问Iceberg table,或者进行Catalog相关的操作。由于Spark Data Source V2 API还在持续的演进和修改中,所以Iceberg在不同的Spark版本中的使用方式有所不同。版本对比 w397090770 4年前 (2020-06-10) 10073℃ 0评论4喜欢
Apache Spark 3.0.0 正式版是2020年6月18日发布的,其为我们带来大量新功能,很多功能加快了数据的计算速度。但是遗憾的是,这个版本并非稳定版。不过就在昨天,Apache Spark 3.0.1 版本悄悄发布了(好像没看到邮件通知)!值得大家高兴的是,这个版本是稳定版,官方推荐所有 3.0 的用户升级到这个版本。Apache Spark 3.0 增加了很多 w397090770 4年前 (2020-09-10) 1280℃ 0评论0喜欢
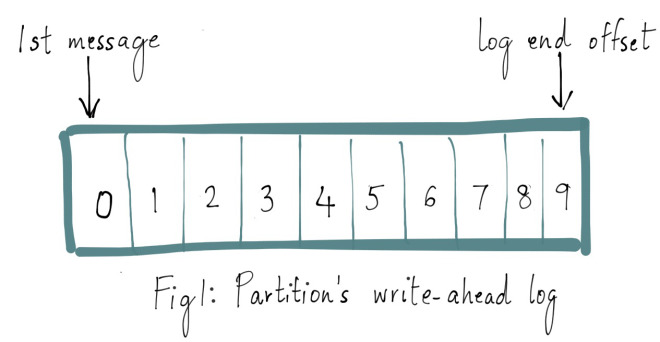
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 w397090770 6年前 (2019-05-26) 5136℃ 1评论14喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第四篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-09-04) 7464℃ 0评论8喜欢
引言 在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询、BI 可视化分析、近实时查询分析等场景,日查询量接近 100 万条。 功能性方面 完全兼容 SparkSQL 语法,可以实现用户从 SparkSQL 到 Presto 的无感迁移; 性能方面 实现 Join Reorder,Runtime Filter 等优化,在 TPCDS1T 数据集上性能相对社区版本提升 80.5%; 稳定性方面 首先,实 w397090770 3年前 (2021-12-30) 702℃ 0评论1喜欢
NVMe是Non-Volatile Memory express(非易失性内存主机控制器接口规范)的简称,它是一种协议,能够使固态硬盘(SSD)运行得更快,如今在企业用户中已越来越流行。理解什么是NVMe的最简单的方法就是打个比方——假设你刚买了一辆跑车,速度能达到400公里每小时,是你以前那辆老汽车的3到4倍。唯一的问题是,普通的道路是无法允许以这 w397090770 3年前 (2021-09-07) 862℃ 0评论1喜欢
数据处理现状:当前基于Hive的离线数据仓库已经非常成熟,数据中台体系也基本上是围绕离线数仓进行建设。但是随着实时计算引擎的不断发展以及业务对于实时报表的产出需求不断膨胀,业界最近几年就一直聚焦并探索于两个相关的热点问题:实时数仓建设和大数据架构的批流一体建设。实时数仓建设:实时数仓1.0 传统 w397090770 3年前 (2022-02-18) 773℃ 0评论2喜欢
Flink 是一种非常复杂的框架,它提供了多种调整其执行的方法。本文将介绍四种不同的方法来提升你的 Flink 应用程序的性能。使用 Flink Tuples当你使用类似于 groupBy, join, 或者 keyBy 算子时,Flink 提供了多种用于在你的数据集上选择 key 的方法。你可以使用 key 选择函数,如下:[code lang="java"]// Join movies and ratings datasetsmovies.join w397090770 7年前 (2017-12-10) 5343℃ 0评论16喜欢
XML(可扩展标记语言,英语:eXtensible Markup Language,简称: XML)是一种标记语言,也是行业标准数据交换交换格式,它很适合在系统之间进行数据存储和交换(话说Hadoop、Hive等的配置文件就是XML格式的)。本文将介绍如何使用MapReduce来读取XML文件。但是Hadoop内部是无法直接解析XML文件;而且XML格式中没有同步标记,所以并行地处 w397090770 9年前 (2016-03-07) 5845℃ 1评论7喜欢
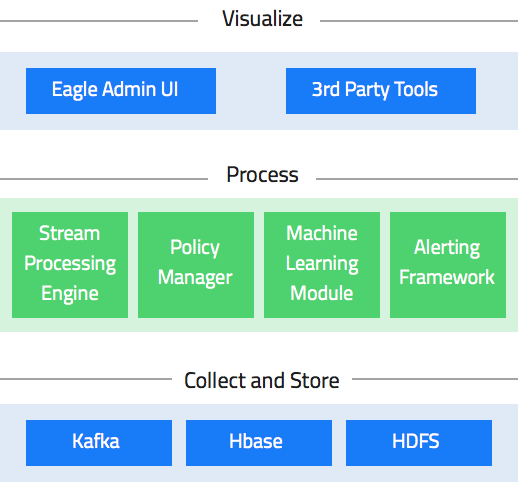
Apache Eagle 是由 eBay 公司开源的一个识别大数据平台上的安全和性能问题的开源解决方案。该项目于2017年1月10日正式成为 Apache 顶级项目。 Apache Eagle 提供一套高效分布式的流式策略引擎,具有高实时、可伸缩、易扩展、交互友好等特点,同时集成机器学习对用户行为建立Profile以实现实时智能实时地保护 Hadoop 生态系统中大数据的安 w397090770 7年前 (2018-01-07) 3182℃ 0评论8喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 3年前 (2022-01-01) 1233℃ 0评论4喜欢
在本博客的《Spark 0.9.1 Standalone模式分布式部署》详细的介绍了如何部署Spark Standalone的分布式,在那篇文章中并没有介绍如何来如何来测试,今天我就来介绍如何用Java来编写简单的程序,并在Standalone模式下运行。 程序的名称为SimpleApp.java,通过调用Spark提供的API进行的,在程序编写前现在pom引入相应的jar依赖:[code lang="JA w397090770 11年前 (2014-04-24) 7639℃ 0评论2喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 4年前 (2020-06-16) 1332℃ 0评论8喜欢
Apache Spark 发布了 Delta Lake 0.4.0,主要支持 DML 的 Python API、将 Parquet 表转换成 Delta Lake 表 以及部分 SQL 功能。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面详细地介绍这些功能部分功能的 SQL 支持SQL 的支持能够为用户提供极大的便利,如果大家去看数砖的 Delta Lake 产品,你肯定已 w397090770 5年前 (2019-10-01) 1299℃ 0评论4喜欢
Efficient processing of big data, especially with Spark, is really all about how much memory one can afford, or how efficient use one can make of the limited amount of available memory. Efficient memory utilization, however, is not what one can take for granted with default configuration shipped with Spark and Yarn. Rather, it takes very careful provisioning and tuning to get as much as possible from the bare metal. In this post I’ll w397090770 4年前 (2020-09-09) 973℃ 0评论0喜欢
分享的内容主要包括三个内容:1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;2)Kyuubi在网易内部的定位、角色和实际使用场景;3)通过案例分享Kyuubi在实际过程中如何起到作用。Kyuubi是什么开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要 zz~~ 3年前 (2021-12-23) 2355℃ 0评论4喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); w397090770 6年前 (2018-11-10) 4530℃ 0评论6喜欢
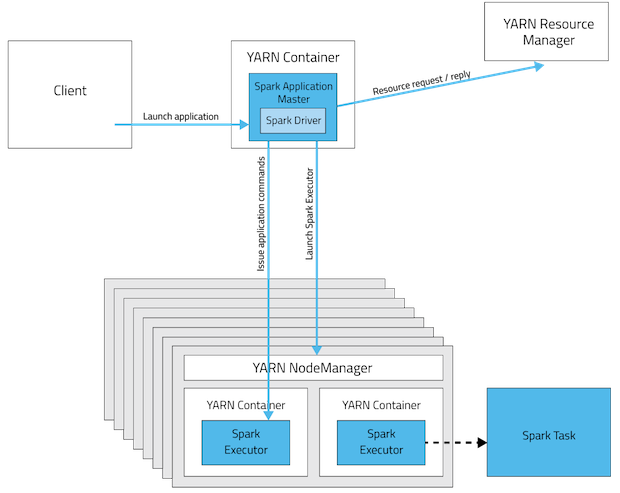
《Spark on YARN集群模式作业运行全过程分析》 《Spark on YARN客户端模式作业运行全过程分析》 《Spark:Yarn-cluster和Yarn-client区别与联系》 《Spark和Hadoop作业之间的区别》 《Spark Standalone模式作业运行全过程分析》(未发布) 我们都知道Spark支持在yarn上运行,但是Spark on yarn有分为两种模式yarn-cluster和yarn-cl w397090770 10年前 (2014-12-15) 58297℃ 4评论94喜欢
上海Spark Meetup第四次聚会将于2015年5月16日在小沃科技有限公司(原中国联通应用商店运营中心)举办。本次聚会特别添加了抽奖环节,凡是参加了问卷调查并在当天到场的同学们都有机会中奖。奖品由英特尔亚太研发有限公司赞助。大会主题 Opening Keynote 沈洲 小沃科技有限公司副总经理,上海交通大学计算机专 w397090770 10年前 (2015-05-05) 3464℃ 0评论2喜欢
本书于2015年04月出版,共168页,这里提供的是本书的完整版. w397090770 9年前 (2015-08-24) 3181℃ 0评论5喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,Ververica(Apache Flink 商业母公司)、腾讯、Google、Airbnb以及 Uber 等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生 w397090770 10年前 (2014-07-21) 44798℃ 55评论28喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 zz~~ 3年前 (2021-11-16) 573℃ 0评论0喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 9年前 (2015-07-11) 5533℃ 0评论14喜欢