在即将发布的Apache Spark 2.0中将会提供机器学习模型持久化能力。机器学习模型持久化(机器学习模型的保存和加载)使得以下三类机器学习场景变得容易: 1、数据科学家开发ML模型并移交给工程师团队在生产环境中发布; 2、数据工程师把一个Python语言开发的机器学习模型训练工作流集成到一个Java语言开发的机器 w397090770 9年前 (2016-06-04) 3508℃ 3评论3喜欢
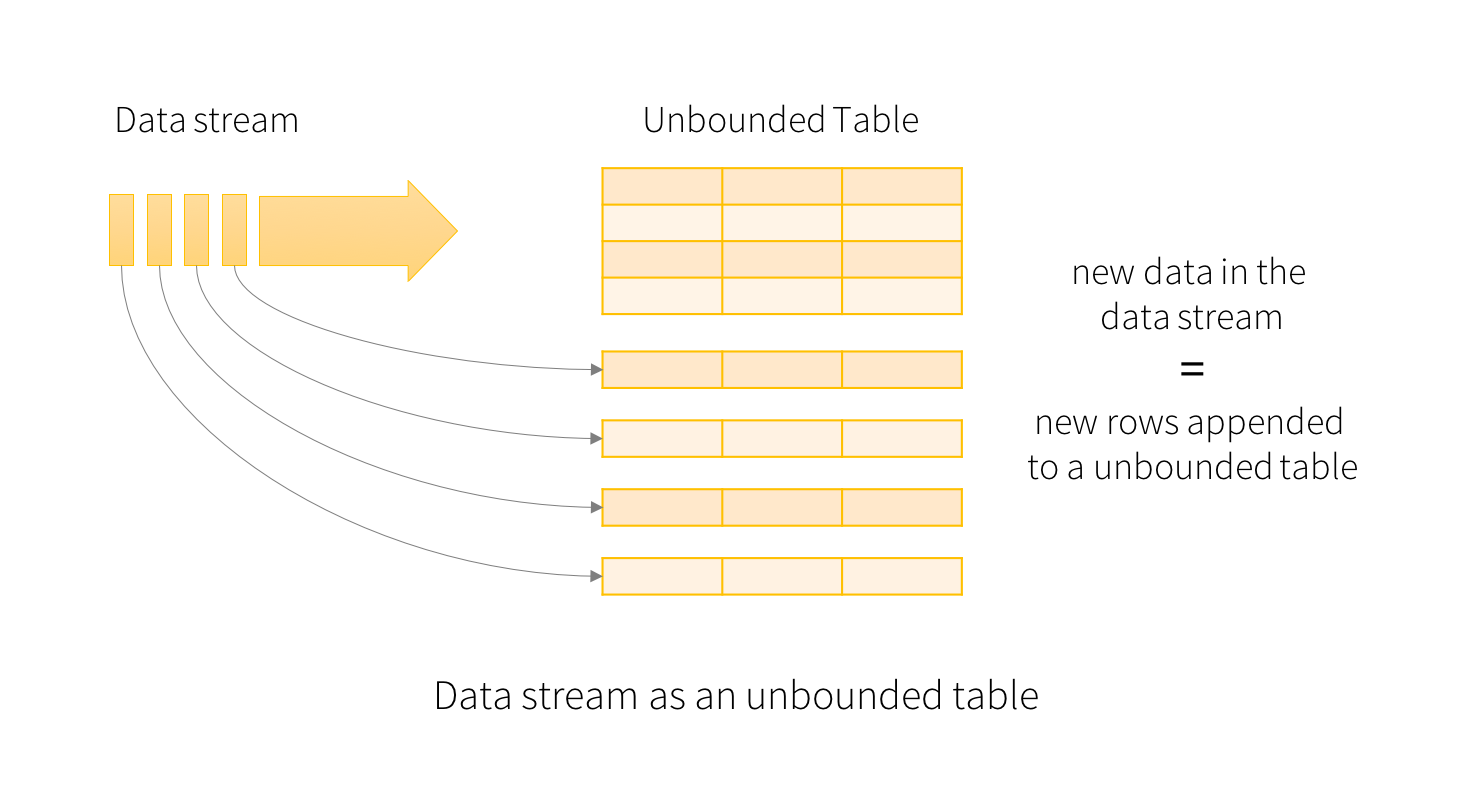
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10771℃ 2评论11喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 3年前 (2021-07-31) 475℃ 0评论4喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 7年前 (2018-05-13) 4786℃ 0评论0喜欢
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1302℃ 0评论4喜欢
Flink可以在单台机器上运行,甚至是单个Java虚拟机(Java Virtual Machine)。这种机制使得用户可以在本地测试或者调试Flink程序。本节主要概述Flink本地模式的运行机制。 本地环境和执行器(executors)运行你在本地的Java虚拟机上运行Flink程序,或者是在属于正在运行程序的如何Java虚拟机上。对于大部分示例程序而言,你只需简单 w397090770 9年前 (2016-04-27) 16450℃ 0评论19喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8847℃ 0评论14喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 10年前 (2015-06-09) 36601℃ 1评论50喜欢
本书是《Hadoop权威指南》第三版,新版新特色,内容更详细。本书是为程序员写的,可帮助他们分析任何大小的数据集。本书同时也是为管理员写的,帮助他们了解如何设置和运行Hadoop集群。 本书通过丰富的案例学习来解释Hadoop的幕后机理,阐述了Hadoop如何解决现实生活中的具体问题。第3版覆盖Hadoop的新动态,包括新增 zz~~ 8年前 (2016-12-16) 17291℃ 0评论43喜欢
在昨天我谈到了WSDL的一些概念,今天打算谈谈为什么理解WSDL非常重要。 许多用户可能会提到的一个问题是,既然WSDL文件可以在各种主要的平台上使用工具创建,为什么还要花时间学习WSDL呢?这是因为WSDL文档非常新,学习其内容和工作原理是明智的。由于Web服务正在变得无所不在,所以,理解和掌握WSDL文档的必要性越来 w397090770 12年前 (2013-04-25) 3119℃ 1评论2喜欢
本文转载自:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing。摘要 本文提出了分布式内存抽象的概念——弹性分布式数据集(RDD,Resilient Distributed Datasets),它具备像MapReduce等数据流模型的容错特性,并且允许开发人员 w397090770 10年前 (2014-10-30) 13690℃ 0评论7喜欢
我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀 w397090770 9年前 (2016-04-04) 18124℃ 0评论42喜欢
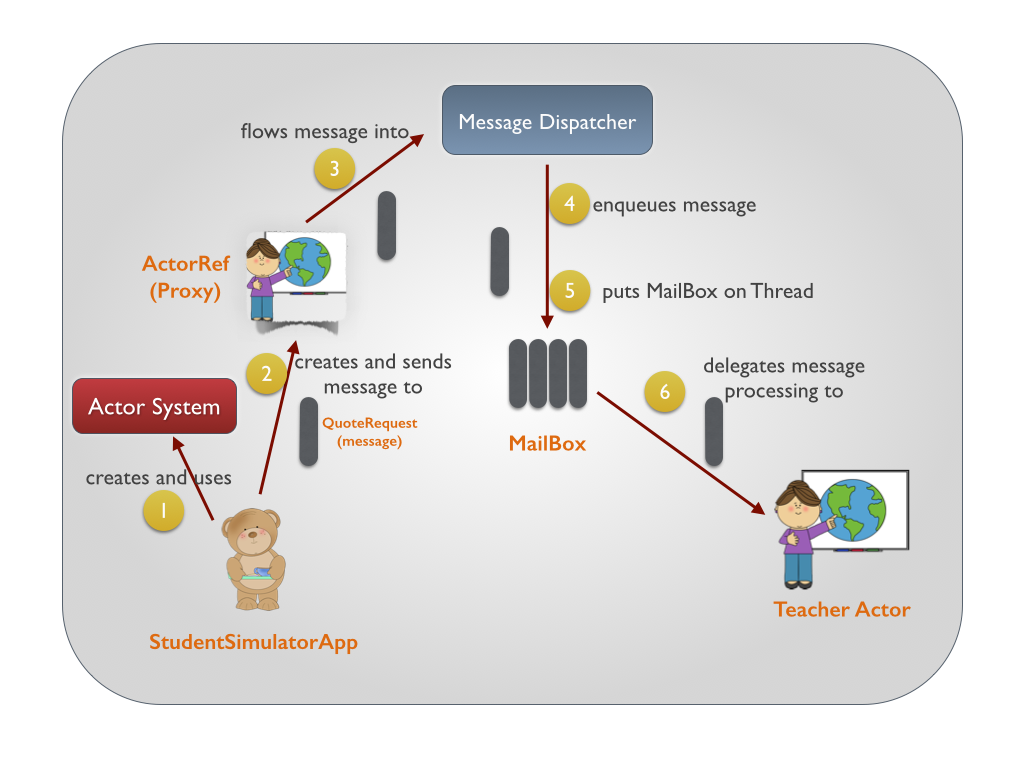
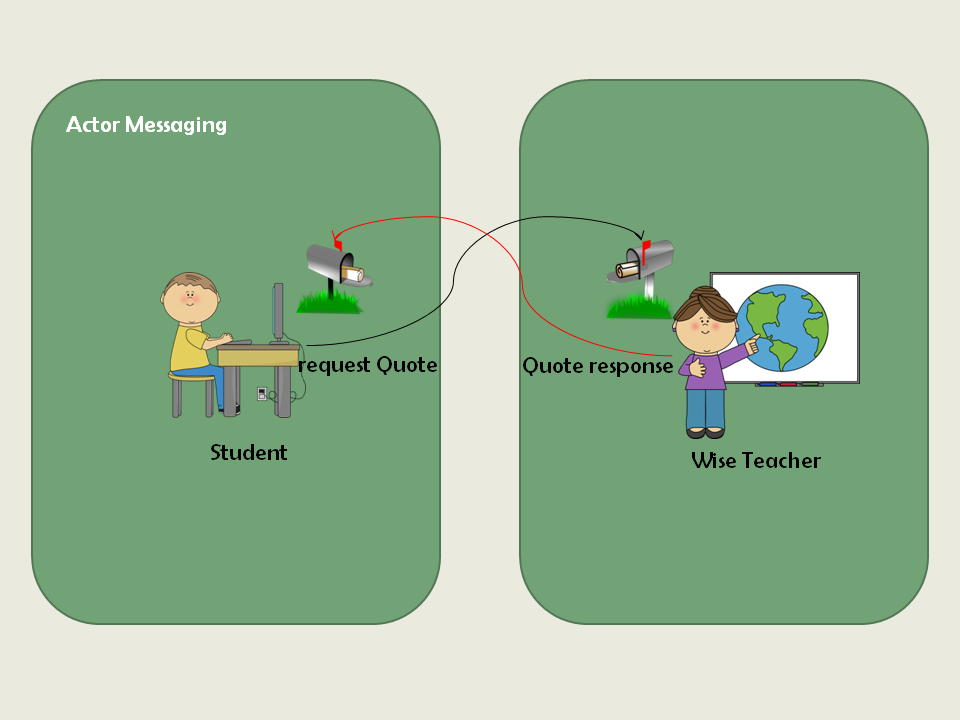
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 21980℃ 5评论40喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 3年前 (2021-08-03) 1097℃ 0评论1喜欢
本书于2017-03由Packt Publishing出版,作者Muhammad Asif Abbasi,全书356页。通过本书你将学到以下知识:Get an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark.Realize how to deploy Spark with YAR zz~~ 7年前 (2017-07-26) 14747℃ 0评论29喜欢
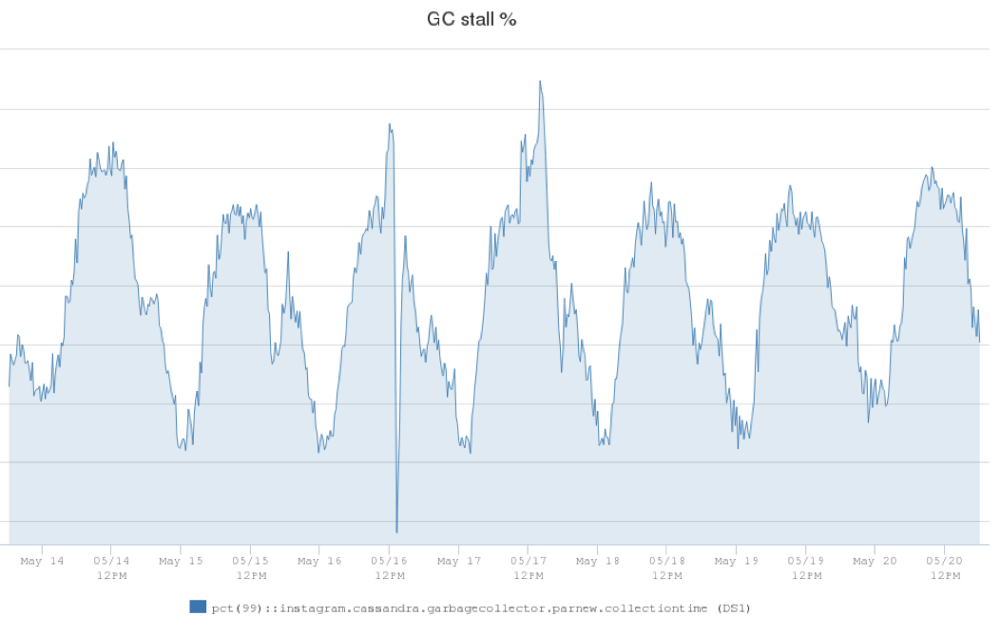
在 Instagram (Instagram 是 Facebook 公司旗下一款免费提供在线图片及视频分享的社交应用软件,于2010年10月发布。)上,我们拥有世界上最大的 Apache Cassandra 数据库部署。我们在 2012 年开始使用 Cassandra 取代 Redis ,在生产环境中支撑欺诈检测,Feed 和 Direct inbox 等产品。起初我们在 AWS 环境中运行了 Cassandra 集群,但是当 Instagram 架构发生 w397090770 6年前 (2019-05-08) 1148℃ 0评论0喜欢
With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while still a w397090770 4年前 (2021-04-27) 2350℃ 0评论2喜欢
Elasticsearch 5.0.0在2016年10月26日发布,该版本基于Lucene 6.2.0,这是最新的稳定版本,并且已经在Elastic Cloud上完成了部署。Elasticsearch 5.0.0是目前最快、最安全、最具弹性、最易用的版本,此版本带来了一系列的新功能和性能优化。ElasticSearch 5.0.0 release Note点击下载ElasticSearch 5.0.0阅读最新文档如果想及时了解Spark、Hadoop或者Hbase w397090770 8年前 (2016-11-02) 4959℃ 0评论10喜欢
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 但是Spark官方文档给出的属性只是简单的介绍了一下含义,许多细节并没有涉及到。本文及以后几篇文章将会对Spark官方的各个属性进行说明介绍。以下是根据Spark 1.1.0文档中的属性进行说明。Application相关属性绝大多数的属性控制应用程序的内部设置,并且默认值 w397090770 10年前 (2014-09-25) 18074℃ 1评论20喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-12) 28239℃ 4评论119喜欢
在Wordpress后台里面有个选项是 多媒体->媒体库 里面显示的是所有文章的附件,包括了图片、视频、文件等。我们在开发Wordpress的时候,有时候需要列出文章中相应的附件,可以通过下面的方式来解决:[code lang="php"]$args = array( 'caller_get_posts' => 1, 'paged' => $paged);query_posts($args);if ( have_posts() ) : while ( have_posts w397090770 10年前 (2014-11-10) 6651℃ 1评论6喜欢
本文仅仅是简单地介绍如何在Ubuntu/Debian系统上安装Node.js(任何版本)和npm(Node Package Manager的简写),其他类Linux系统安装步骤和这个类似。 一、更新你的系统[code lang="bash"]iteblog# sudo apt-get updateiteblog# sudo apt-get install git-core curl build-essential openssl libssl-dev[/code] 二、安装Node.js 首先我们先从github上将Node w397090770 10年前 (2015-04-11) 27768℃ 0评论22喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase w397090770 7年前 (2017-12-16) 1809℃ 0评论13喜欢
显示分区[code lang="sql"]show partitions iteblog;[/code]添加分区[code lang="sql"]ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)ALTER TABLE iteblog ADD PARTITION (dt='2008-08-08') location '/path/to/us/part080 w397090770 9年前 (2015-11-27) 9961℃ 0评论18喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所以在选择不同当时监控时,我们需要详细了解需要我们的需 w397090770 9年前 (2016-06-23) 21330℃ 0评论34喜欢
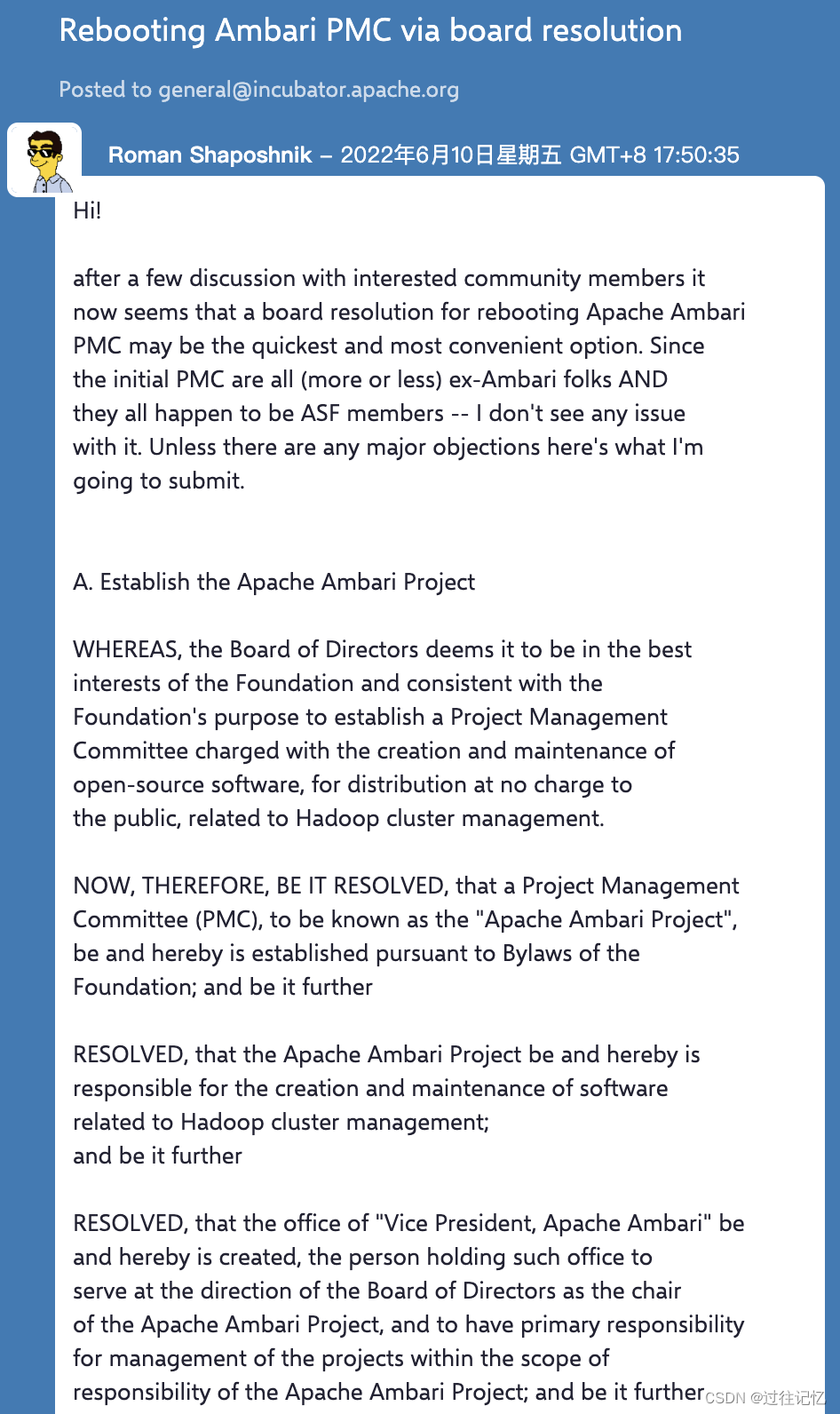
今年的1月份,Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 曾经给社区发了一份提议将 Apache Ambari 一定 Attic 的邮件。原因是在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员都没有积极参与到这个项目中来。按照 Apache 的项目生命周期(https://attic.apache.org/process.html),其应该是 reached its end of w397090770 2年前 (2022-06-12) 1079℃ 0评论0喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第三篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-17) 3702℃ 0评论3喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 w397090770 6年前 (2018-10-13) 3485℃ 1评论8喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2644℃ 0评论3喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4767℃ 0评论5喜欢





![[电子书]Hadoop权威指南第3版中文版PDF下载](https://www.iteblog.com/pic/Hadoop_the_definitive_guide_Third_Edition.jpg)



![[电子书]Learning Apache Spark 2 PDF下载](https://www.iteblog.com/pic/books/Learning-Apache-Spark-2_iteblog.png)





![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)