安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结 w397090770 9年前 (2016-04-05) 17709℃ 0评论23喜欢
为期两个月开发的 Apache Flink 1.6.0 于今天(2018-08-09)正式发布了。Flink 社区艰难地解决了 360 个 issues,到这里查看完整版的 changelog 。Flink 1.6.0 是 1.x.y 版本系列上的第七个版本,1.x.y 中所有使用 @Public 标注的 API 都是兼容的。此版本继续使 Flink 用户能够无缝地运行快速数据处理并轻松构建数据驱动和数据密集型应用程序。Apache Fli w397090770 6年前 (2018-08-09) 1944℃ 0评论10喜欢
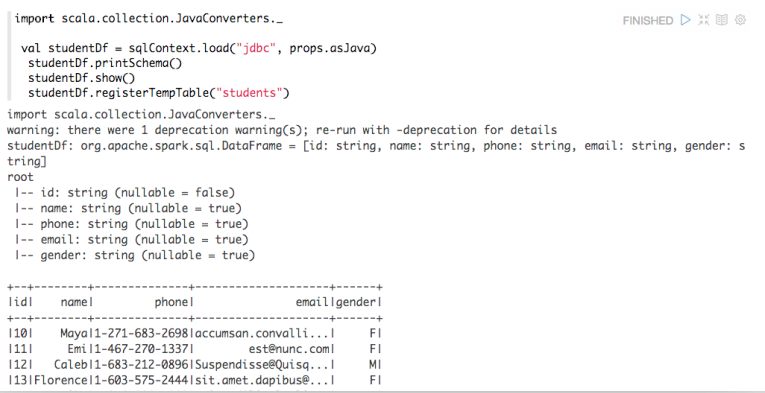
我们知道,编写Scala程序的时候可以使用下面两种方法之一:[code lang="scala"]object IteblogTest extends App { //ToDo}object IteblogTest{ def main(args: Array[String]): Unit = { //ToDo }}[/code] 上面的两种方法都可以运行程序,但是在Spark中,第一种方法有时可不会正确的运行(出现异常或者是数据不见了)。比如下面的代码运 w397090770 9年前 (2015-12-10) 5311℃ 0评论5喜欢
2014年7月11日,Spark 1.0.1已经发布了,原文如下:We are happy to announce the availability of Spark 1.0.1! This release includes contributions from 70 developers. Spark 1.0.0 includes fixes across several areas of Spark, including the core API, PySpark, and MLlib. It also includes new features in Spark’s (alpha) SQL library, including support for JSON data and performance and stability fixes.Visit the relea w397090770 10年前 (2014-07-13) 6885℃ 0评论4喜欢
2021年01月21日,Apache 官方博客宣布 Apache® Superset™ 成为顶级项目。Apache® Superset™ 是一个现代化的大数据探索和可视化平台,它允许用户使用简单的无代码可视化构建器和最先进的 SQL 编辑器轻松快速地构建仪表盘(dashboards)。该项目于2015年在 Airbnb 启动,并于2017年5月进入 Apache 孵化器。说白了,其实 Apache Superset 算是一个大数据 w397090770 4年前 (2021-01-22) 775℃ 0评论1喜欢
bsie是使得IE6可以支持Bootstrap的补丁,Bootstrap是 twitter.com 推出的非常棒web UI工具库。目前,bsie使得IE6能支持bootstrap大部分特性,可惜,还有一些实在无法支持...下面的这个表格就是当前已经被支持的bootstrap的组件和特性:[code lang="bash"]组件 特性-----------------------------------------------------------grid fixed, fluidnavbar w397090770 9年前 (2015-12-26) 2321℃ 7评论3喜欢
虽然在运行Hadoop的时候可以打印出大量的运行日志,但是很多时候只通过打印这些日志是不能很好地跟踪Hadoop各个模块的运行状况。这时候编译与调试Hadoop源码就得派上场了。这也就是今天本文需要讨论的。编译Hadoop源码 先说说怎么编译Hadoop源码,本文主要介绍在Linux环境下用Maven来编译Hadoop。在编译Hadoop之前,我们 w397090770 11年前 (2014-01-09) 19936℃ 0评论10喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 在前面的两篇文章中我们介绍了如何编译和部署Apache Zeppelin、如何使用Apache Zeppelin。这篇文章中将介绍如何将外部依赖库加入到Apache Zeppelin中。 在现实情况下,我们编写程序一般都是需要依赖外部的相关类库 w397090770 9年前 (2016-02-04) 8146℃ 0评论7喜欢
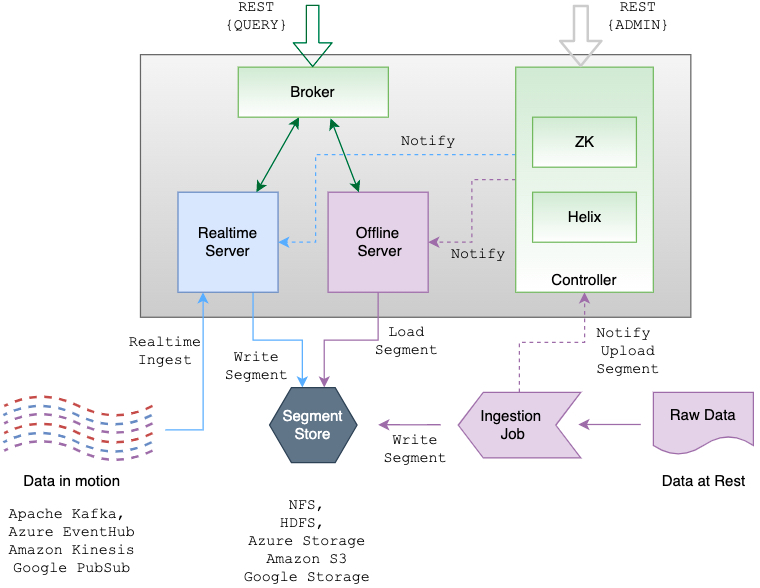
Apache Pinot 是一个分布式实时分布式 OLAP 数据存储,旨在以高吞吐量和低延迟提供可扩展的实时分析。该项目最初于 2013 年由 LinkedIn 创建,2015 年开源,于 2018 年 10 月进入 Apache 孵化器,2021年08月02日正式毕业成为 Apache 顶级项目。Apache Pinot 可以直接从流数据源(例如 Apache Kafka 和 Amazon Kinesis)中提取,并使事件可用于即时查询。 w397090770 3年前 (2022-01-01) 1015℃ 0评论1喜欢
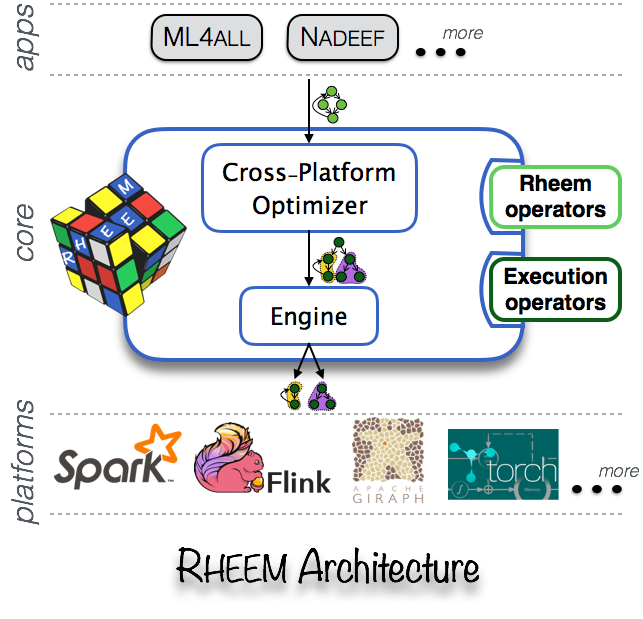
RHEEM是一个可扩展且易于使用的跨平台大数据分析系统,它在现有的数据处理平台之上提供了一个抽象。它允许用户使用易于使用的编程接口轻松地编写数据分析任务,为开发者提供了不同的方式进行性能优化,编写好的程序可以在任意数据处理平台上运行,这其中包括:PostgreSQL, Spark, Hadoop MapReduce或者Flink等;Rheem将选择经典 w397090770 8年前 (2017-03-23) 1038℃ 0评论3喜欢
Apache Hive 1.0.1 和 1.1.1两个版本同时发布,他们分别是基于Hive 1.0.0和Hive 1.1.0,这两个版本都同时修复可同一个Bug:LDAP授权provider的漏洞。如果用户在HiveServer2里面使用到LDAP授权模式(hive.server2.authentication=LDAP),并且LDAP使用简单地未认证模式,或者是匿名绑定(anonymous bind),在这种情况下未得到合理授权的用户将得到认证(authe w397090770 10年前 (2015-05-25) 4998℃ 0评论3喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 w397090770 8年前 (2016-12-15) 3250℃ 0评论8喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 7年前 (2018-05-13) 4786℃ 0评论0喜欢
我们在使用Hadoop、Spark或者是Hbase,最常遇到的问题就是进行相关系统的配置,比如集群的URL地址,MapReduce临时目录、最终输出路径等。这些属性需要有一个系统(类)进行管理。然而,Hadoop没有使用 Java.util.Properties 管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是单独开发了一个配置文件管理类,这个类就 w397090770 8年前 (2017-04-21) 7746℃ 0评论18喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala w397090770 3年前 (2021-10-13) 846℃ 0评论3喜欢
《Spark Streaming和Kafka整合开发指南(一)》 《Spark Streaming和Kafka整合开发指南(二)》 在本博客的《Spark Streaming和Kafka整合开发指南(一)》文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据。本文将介绍如何使用Spark 1.3.0引入的Direct API从Kafka中读数据。 和基于Receiver接收数据不一样,这种方式 w397090770 10年前 (2015-04-21) 28423℃ 1评论26喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在同年的12月成功毕业成为 Apache 基金会的顶级项目(《Apache Beam成为Apache顶级项目 w397090770 8年前 (2017-05-18) 1752℃ 0评论3喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4683℃ 0评论11喜欢
Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 618℃ 0评论3喜欢
一、百度(武汉地区)第一部分:1、描述数据库的简单操作。2、描述TCP\IP四层模型,并简述之。3、描述MVC的内容。第二部分:1、给出a-z0-9,在其中选择三个字符组成一个密码,输出全部的情况,程序实现。2、字符串的反转,比如abcde,输出edcba.3、许多程序会大量使用字符串。对于不同的字符串,我们希望能够 w397090770 12年前 (2013-04-15) 13411℃ 0评论9喜欢
Mahout项目发展到了今天已经实现了许多的算法。下面列出Mahout项目主要的算法名称,供大家参考。一、协同过滤 Collaborative Filtering 1、基于用户的协同过滤 User-Based Collaborative Filtering 2、基于项目的协同过滤统 Item-Based Collaborative Filtering 3、交替最小二乘张量分解 Matrix Factorization with Alternating Least Squares 4、基 w397090770 10年前 (2014-09-23) 9515℃ 0评论17喜欢
Trino Summit 2021 由 Starburst 于 2021年10月21日-22日通过线上的方式进行。主要分享嘉宾有 Trino 的几个创始人、Apache Iceberg 的创建者 Ryan Blue 以及来自 DoorDash 的 Akshat Nair 和 Satya Boora 等。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop主要分享议题State of TrinoFast results using Iceberg and TrinoThe Future of w397090770 3年前 (2022-04-12) 575℃ 0评论4喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 5年前 (2020-05-30) 949℃ 0评论1喜欢
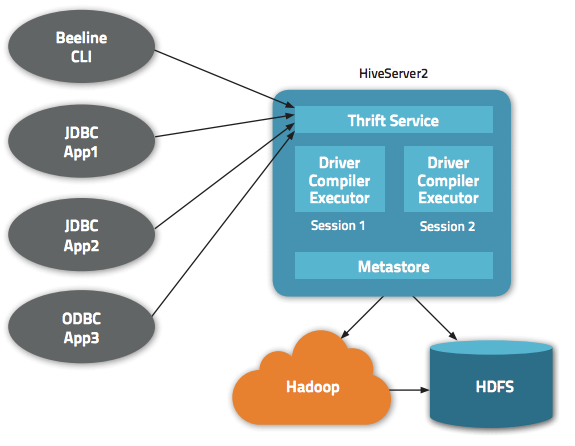
Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可 w397090770 7年前 (2018-01-11) 13381℃ 5评论18喜欢
在Scala中存在好几个Zip相关的函数,比如zip,zipAll,zipped 以及zipWithIndex等等。我们在代码中也经常看到这样的函数,这篇文章主要介绍一下这些函数的区别以及使用。1、zip函数将传进来的两个参数中相应位置上的元素组成一个pair数组。如果其中一个参数元素比较长,那么多余的参数会被删掉。看下英文介绍吧:Returns a list formed w397090770 10年前 (2014-12-17) 26333℃ 2评论21喜欢
我们往Kafka发送消息时一般都是将消息封装到KeyedMessage类中:[code lang="scala"]val message = new KeyedMessage[String, String](topic, key, content)producer.send(message)[/code]Kafka会根据传进来的key计算其分区ID。但是这个Key可以不传,根据Kafka的官方文档描述:如果key为null,那么Producer将会把这条消息发送给随机的一个Partition。If the key is null, the w397090770 9年前 (2016-03-30) 16350℃ 0评论10喜欢
Apache Spark 3.0.0 正式版是2020年6月18日发布的,其为我们带来大量新功能,很多功能加快了数据的计算速度。但是遗憾的是,这个版本并非稳定版。不过就在昨天,Apache Spark 3.0.1 版本悄悄发布了(好像没看到邮件通知)!值得大家高兴的是,这个版本是稳定版,官方推荐所有 3.0 的用户升级到这个版本。Apache Spark 3.0 增加了很多 w397090770 4年前 (2020-09-10) 1280℃ 0评论0喜欢
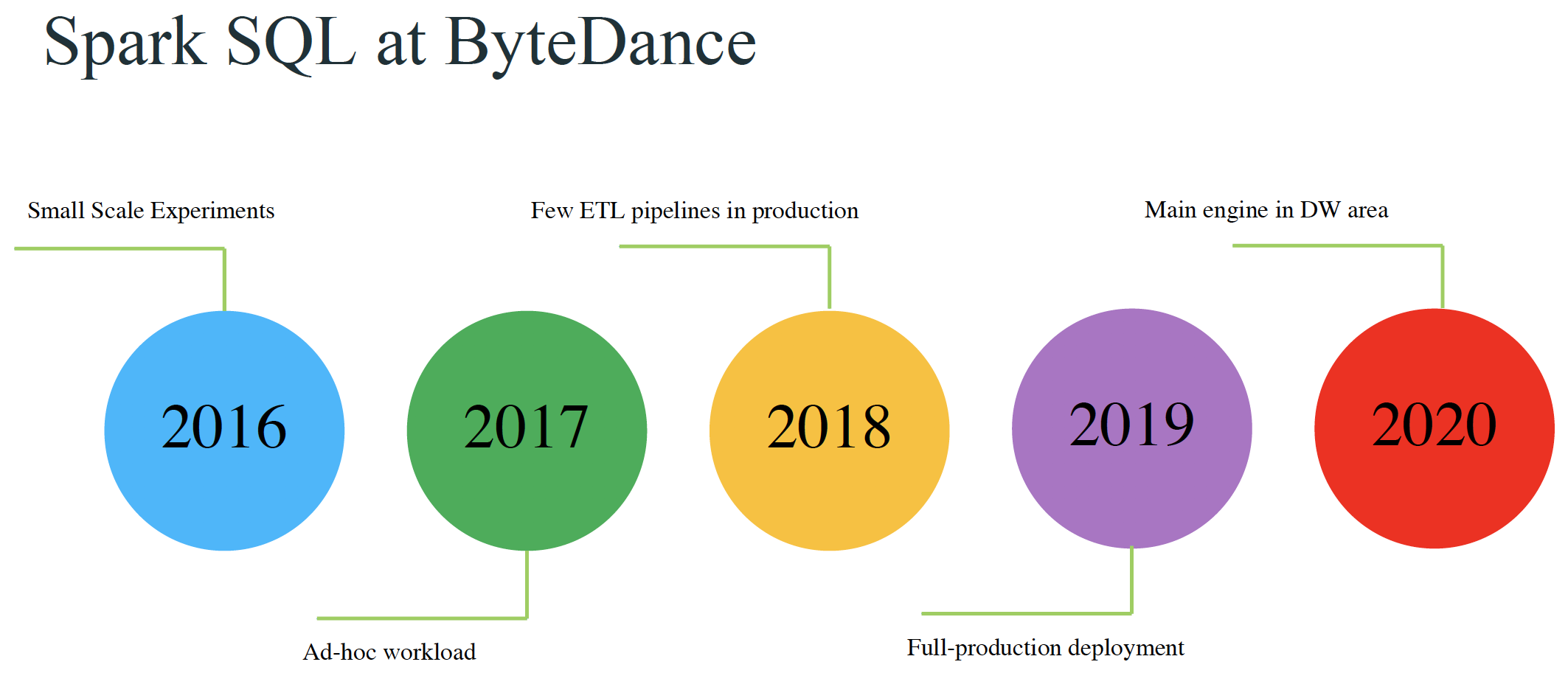
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2479℃ 2评论4喜欢
Java 14 计划将会在今年的3月17日发布,Java 14 包含的 JEP(Java Enhancement Proposals 的缩写,Java 增强建议)比 Java 12 和 13 两个版本加起来还要多。那么,对于每天编写和维护代码的 Java 开发人员来说,哪个特性值得我们关注呢?如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文我将介绍以下几个重 w397090770 5年前 (2020-03-07) 938℃ 0评论2喜欢
分享的内容主要包括三个内容:1)Kyuubi是什么?介绍Kyuubi的核心功能以及Kyuubi在各个使用场景中的解决方案;2)Kyuubi在网易内部的定位、角色和实际使用场景;3)通过案例分享Kyuubi在实际过程中如何起到作用。Kyuubi是什么开源Kyuubi是网易秉持开源理念的作品。Kyuubi是网易第一款贡献给Apache并进入孵化的开源项目。Kyuubi主要 zz~~ 3年前 (2021-12-23) 2355℃ 0评论4喜欢