在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 554℃ 0评论4喜欢
Fedora安装完毕之后最头疼的问题就是软件更新,因为Fedora默认的更新源服务器是在国外,所以每次更新的速度奇慢!那么,我们是否可以修改Fedora的默认下载源呢?答案是可以的。目前国内有很多大学都提供了Fedora的更新包下载服务器,下载速度相对国外的快。下面以华中科技大学的源(http://mirrors.ustc.edu.cn/)为例(只能用在Fedora15、1 w397090770 12年前 (2013-04-02) 8827℃ 0评论0喜欢
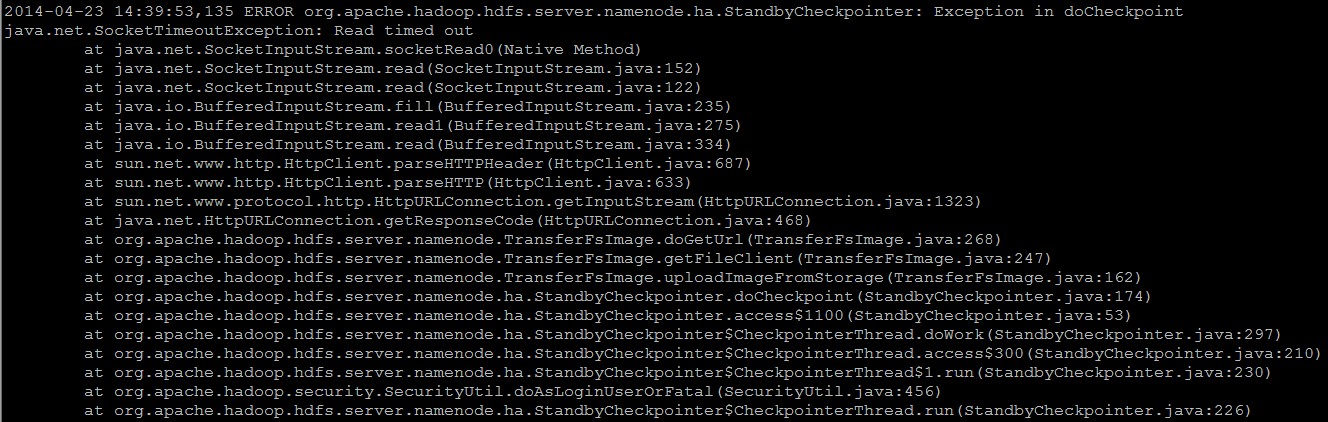
这几天观察了一下Standby NN上面的日志,发现每次Fsimage合并完之后,Standby NN通知Active NN来下载合并好的Fsimage的过程中会出现以下的异常信息:[code lang="JAVA"]2014-04-23 14:42:54,964 ERROR org.apache.hadoop.hdfs.server.namenode.ha. StandbyCheckpointer: Exception in doCheckpointjava.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0( w397090770 11年前 (2014-04-23) 7751℃ 2评论8喜欢
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2399℃ 0评论4喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 4年前 (2020-06-28) 1030℃ 0评论1喜欢
AWS 于近期发布了自家版本的开源 ElasticSearch :Open Distro for Elasticsearch。我们都知道,Elasticsearch 是一个分布式面向文档的搜索和分析引擎。 它支持结构化和非结构化查询,并且不需要提前定义模式。 Elasticsearch 可用作搜索引擎,通常用于 Web 级日志分析,实时应用程序监控和点击流分析,在国内外有很多用户使用。AWS 通过 AWS Elasticse w397090770 6年前 (2019-03-13) 4165℃ 0评论10喜欢
Apache Kafka 0.10.0.0于美国时间2016年5月24日正式发布。Apache Kafka 0.10.0.0是Apache Kafka的主要版本,此版本带来了一系列的新特性和功能加强。本文将对此版本的重要点进行说明。Kafka StreamsKafka Streams在几个月前由Confluent Platform首先在其平台的技术预览中行提出,目前已经在Apache Kafka 0.10.0.0上可用了。Kafka Streams其实是一套类库,它使 w397090770 9年前 (2016-05-25) 12389℃ 0评论25喜欢
在使用Maven打包工程运行的时候,有时会出现以下的异常:[code lang="bash"]-bash-4.1# java -cp iteblog-1.0-SNAPSHOT.jar com.iteblog.ClientException in thread "main" java.lang.SecurityException: Invalid signature file digest for Manifest main attributes at sun.security.util.SignatureFileVerifier.processImpl(SignatureFileVerifier.java:287) at sun.security.util.SignatureFileVerifier.process(Signatu w397090770 9年前 (2016-01-20) 13289℃ 0评论9喜欢
youtube-dl是一个精悍的命令程序,它可以从YouTube.com以及其他网站上下载视频。它是使用Python开发的,依赖于Python 2.6, 2.7, 或者3.2+解释器,而且这个视频下载命令是跨平台的,作者为我们带来了Windows执行文件(https://yt-dl.org/latest/youtube-dl.exe),其中就包含了Python。youtube-dl可以在Unix box,Windows或者是 Mac OS X平台上运行,支持众多视频网 w397090770 9年前 (2016-04-09) 6691℃ 0评论6喜欢
本博客收集的手机号段截止时间为2020年03月的,共计450000+条。包含以下字段:电信:133 153 173(新) 177 (新) 180 181 189 199 (新)移动:134 135 136 137 138 139 150 151 152 157 158 159 172(新) 178(新) 182 183 184 187 188 198(新) 联通:130 131 132 155 156 166(新) 175(新) 176(新) 185 186数据卡:145 147 149其他:170(新) 171 (新)API地址/api/mobile.php使用本AP w397090770 8年前 (2016-08-02) 5081℃ 0评论15喜欢
Spark SQL 是 Spark 最新且技术最复杂的组件之一。它同时支持 SQL 查询和新的 DataFrame API。Spark SQL 的核心是 Catalyst 优化器,它以一种全新的方式利用高级语言的特性(例如:Scala 的模式匹配和 Quasiquotes ①)构建一个可扩展的查询优化器。最近我们在 SIGMOD 2015 发表了一篇论文(合作者:Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan w397090770 5年前 (2019-07-21) 3275℃ 0评论5喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2644℃ 0评论3喜欢
本文将介绍如何通过Hive来读取ElasticSearch中的数据,然后我们可以像操作其他正常Hive表一样,使用Hive来直接操作ElasticSearch中的数据,将极大的方便开发人员。本文使用的各组件版本分别为 Hive0.12、Hadoop-2.2.0、ElasticSearch 2.3.4。 我们先来看看ElasticSearch中相关表的mapping:[code lang="bash"]{ "user": { "propert w397090770 8年前 (2016-10-26) 17176℃ 0评论30喜欢
在C++中一共有四种强制类型转换:dynamic_cast、const_cast 、static_cast、reinterpret_cast。除了dynamic_cast是在运行的时候进行类型转换的,其它三种都是在编译期间实现转换的。四种类型的转换介绍如下: dynamic_cast:只能在继承类对象的指针之间或引用之间进行类型转换,进行转换时,会根据对象的运行时类型信息,判断类型对象之间的 w397090770 12年前 (2013-04-04) 3241℃ 0评论2喜欢
理论上,在Hadoop 1.x上开发的Mapreduce程序可以在Hadoop 2.x上面运行,Hadoop2.x类库对Hadoop1.x程序的兼容性主要体现在以下几点: 二进制兼容:利用mapred API开发以及编译程序可以直接在Hadoop 2.x运行,不需要重新编译; 源码兼容:利用mapreduce API开发的程序, 需要在Hadoop 2.x上重新编译才能运行; 不兼容部分:mradmin w397090770 11年前 (2013-12-10) 6515℃ 1评论4喜欢
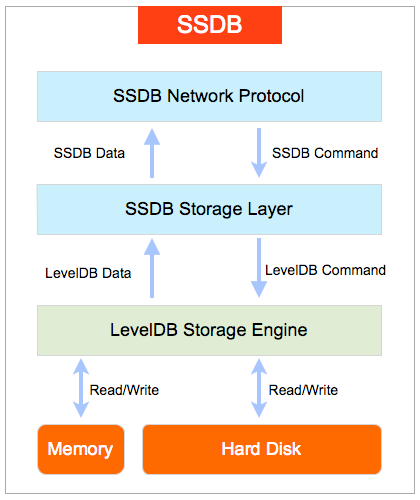
SSDB 是一个使用 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据。实现上其使用了 Google 的 LevelDB作为存储引擎,SSDB 不会像 Redis 一样狂吃内存,而是将大部分数据存储到磁盘上。最重要的是,SSDB采用了New BSD License 开源协议进行了开源,目前已经 w397090770 8年前 (2017-05-27) 3018℃ 0评论7喜欢
在/archives/227主要介绍了memcpy函数的实现,并说明了memcpy函数的局限性。今天来介绍一下和memcpy函数功能类似的函数memmove。memmove函数和memcpy函数的原型为[code lang="CPP"]#include <string.h>void *memcpy(void *dest, const void *src, size_t n);void *memmove(void *dest, const void *src, size_t n);[/code]memmove英文介绍,里面很详细的介绍了memmove函数的 w397090770 12年前 (2013-04-08) 4688℃ 0评论0喜欢
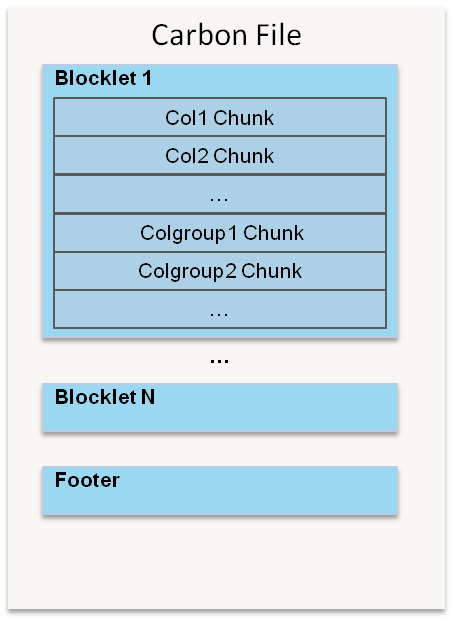
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 9年前 (2016-06-13) 5491℃ 0评论7喜欢
在今年的5月22号,Flume-ng 1.5.0版本正式发布,关于Flume-ng 1.5.0版本的新特性可以参见本博客的《Apache Flume-ng 1.5.0正式发布》进行了解。关于Apache flume-ng 1.4.0版本的编译可以参见本博客《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》。本文将讲述如何用Maven编译Apache flume-ng 1.5.0源码。一、到官方网站下载相应版本的flume-ng源码[code lan w397090770 11年前 (2014-06-16) 20815℃ 23评论14喜欢
Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 3年前 (2022-03-29) 1819℃ 0评论1喜欢
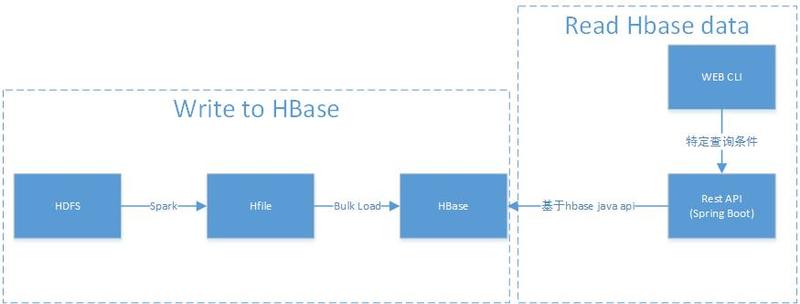
背景介绍本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。 w397090770 7年前 (2017-10-28) 2709℃ 0评论7喜欢
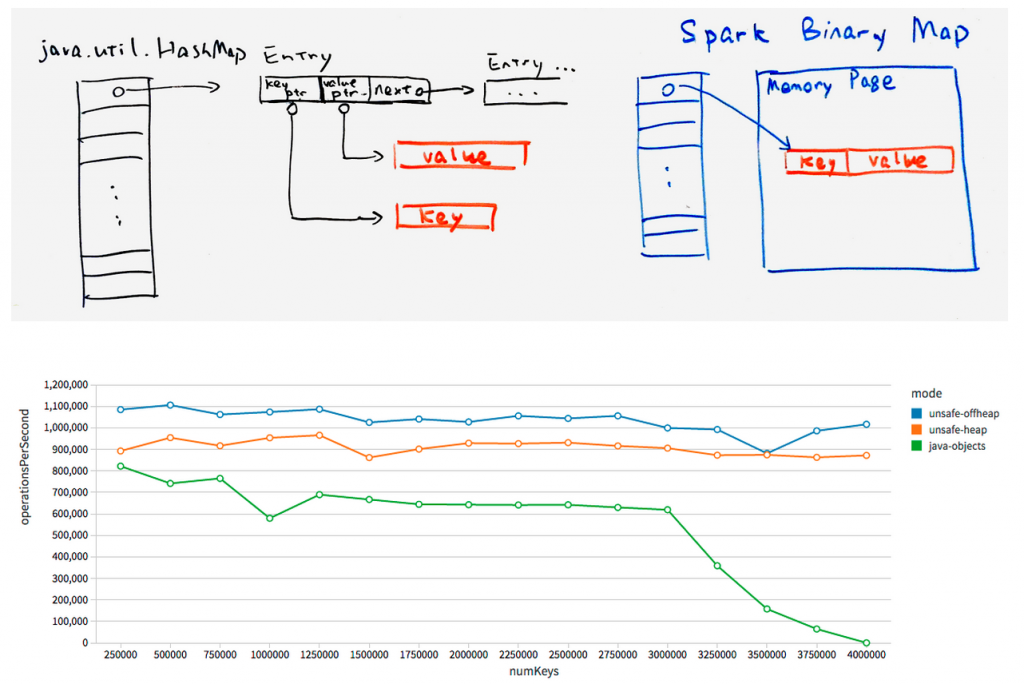
在之前的博文中,我们回顾和总结了2014年Spark在性能提升上所做的努力。本篇博文中,我们将为你介绍性能提升的下一阶段——Tungsten。在2014年,我们目睹了Spark缔造大规模排序的新世界纪录,同时也看到了Spark整个引擎的大幅度提升——从Python到SQL再到机器学习。 Tungsten项目将是Spark自诞生以来内核级别的最大改动,以 w397090770 10年前 (2015-05-04) 4880℃ 1评论4喜欢
这个问题可能很多面试的人都遇到过,很多人可能想利用循环来判断,代码可能如下所示:[code lang="JAVA"] public static boolean isPowOfTwo(int n) { int temp = 0; for (int i = 1; ; i++) { temp = (int) Math.pow(2, i); if (temp >= n) break; } if (temp == n) return true; else return false; }[/code] w397090770 11年前 (2013-09-17) 11577℃ 6评论14喜欢
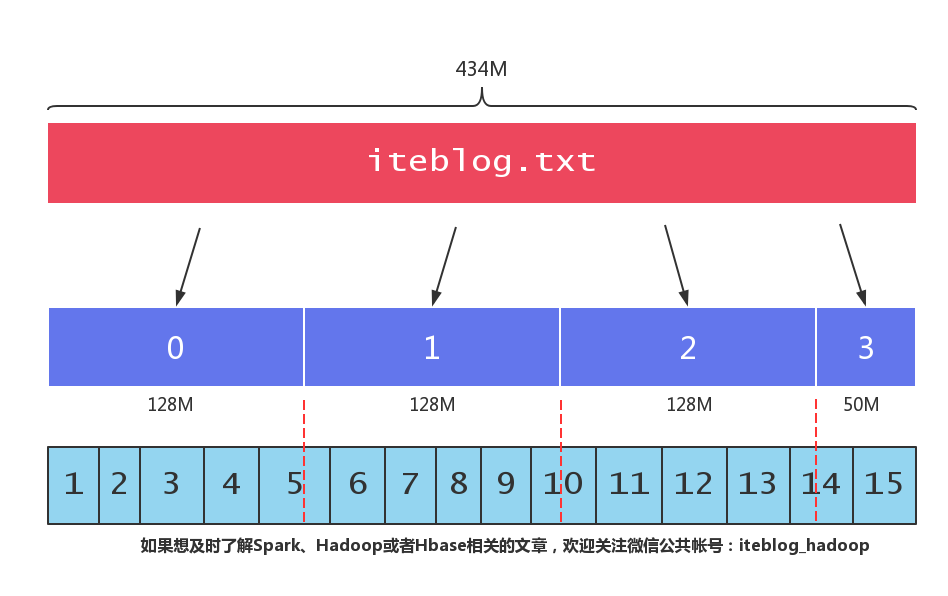
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2682℃ 4评论28喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1223℃ 0评论4喜欢
近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL " rel="nofollow"]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4450℃ 0评论14喜欢
本文资料来自2021年12月09日举办的 PrestoCon 2021,议题为《Updates from the New PrestoDB C++ Execution Engine》,分享者为来自 Ahana 的 Deepak Majeti 以及来自 Intel 的 Dave Cohen, Intel。 本次分享的 PPT 请关注 过往记忆大数据 公众号,并回复 10108 获取。 这篇分享将给大家概述代号为 Prestissimo 项目的相关最新进展。Presti w397090770 3年前 (2021-12-27) 1583℃ 0评论1喜欢
杭州第一次Flink Meetup会议将于2016年11月05日在杭州市滨江区江虹路410号进行,本次活动由华为杭研院承办。 Flink Meetup目前由德国柏林和英国伦敦这两个,这次活动是国内第一次Flink Meetup线下活动,开启第三个Flink Meeup活动大本营。 当下流计算系统可选的较多,Flink的性能和特性比较突出,其他流系统也各有特点。这 w397090770 8年前 (2016-10-18) 1679℃ 0评论1喜欢
本书于2017-07由Packt Publishing出版,作者Giuseppe Bonaccorso,全书580页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Acquaint yourself with important elements of Machine LearningUnderstand the feature selection and feature engineering processAssess performance and error trade-offs for Linear RegressionBuild a data model zz~~ 7年前 (2017-08-27) 4639℃ 0评论14喜欢
在使用 Presto 时,我们经常会听说 Query、Stage、Task 等概念,很多人会搞不清楚这些概念,所以会导致一些误解,本文将简单地介绍一下这些基本的概念是指StatementStatement语句。其实就是指我们输入的SQL语句。Presto支持需要ANSI标准的SQL语句。这种语句由子句(Clause)、表达式(Expression)和断言(Predicate)组成。Presto为什么将语句(S w397090770 3年前 (2021-11-01) 1922℃ 0评论4喜欢













![[电子书]Machine Learning Algorithms PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_Algorithms_iteblog.png)
