北京第九次Spark Meetup活动于2015年08月22日下午14:00-18:00在北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼进行。活动内容如下: 1、《Keynote》 ,分享人:Sejun Ra ,CEO of NFLabs.com 2、《An introduction to Zeppelin with a demo》,分享人: Anthony Corbacho, Engineer from NFLabs and Apache Zeppelin committer 3、《Apache Kylin introductio w397090770 9年前 (2015-09-04) 2683℃ 0评论4喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 9年前 (2015-07-11) 5533℃ 0评论14喜欢
本文将介绍如何通过Hive来读取ElasticSearch中的数据,然后我们可以像操作其他正常Hive表一样,使用Hive来直接操作ElasticSearch中的数据,将极大的方便开发人员。本文使用的各组件版本分别为 Hive0.12、Hadoop-2.2.0、ElasticSearch 2.3.4。 我们先来看看ElasticSearch中相关表的mapping:[code lang="bash"]{ "user": { "propert w397090770 8年前 (2016-10-26) 17176℃ 0评论30喜欢
Apache Kafka 3.0 于2021年9月21日正式发布。本文将介绍这个版本的新功能。以下文章翻译自 《What's New in Apache Kafka 3.0.0》。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据我很高兴地代表 Apache Kafka® 社区宣布 Apache Kafka 3.0 的发布。 Apache Kafka 3.0 是一个大版本,其引入了各种新功能、API 发生重 w397090770 3年前 (2021-09-24) 601℃ 0评论2喜欢
Splitter:在Guava官方的解释为:Extracts non-overlapping substrings from an input string, typically by recognizing appearances of a separator sequence. This separator can be specified as a single character, fixed string, regular expression or CharMatcher instance. Or, instead of using a separator at all, a splitter can extract adjacent substrings of a given fixed length. w397090770 11年前 (2013-09-09) 7107℃ 1评论0喜欢
这本书是市面上第一本系统介绍Apache Flink的图书,书中介绍了为什么选择Apache Flink、流系统架构设计、Flink能做些什么、Flink中是怎么处理时间的、Flink的状态计算等。全书共6章,一共110页。由O'Reilly出版社于2016年10月出版。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop本书的章节[c w397090770 8年前 (2016-11-03) 7963℃ 0评论4喜欢
这个问题可能很多面试的人都遇到过,很多人可能想利用循环来判断,代码可能如下所示:[code lang="JAVA"] public static boolean isPowOfTwo(int n) { int temp = 0; for (int i = 1; ; i++) { temp = (int) Math.pow(2, i); if (temp >= n) break; } if (temp == n) return true; else return false; }[/code] w397090770 11年前 (2013-09-17) 11577℃ 6评论14喜欢
在本文中,我将介绍八个基本的 Docker 容器命令,这些命令对于在 Docker 容器上执行基本操作很有用,比如运行,列表,停止,查看日志,删除等等。如果你对 Docker 的概念不熟悉,推荐你推荐你到网上查看相关的入门介绍,这篇文章就不详细介绍了。 现在我们赶快进入要了解的命令中:如果想及时了解Spark、Hadoop或者HBase相关的 w397090770 6年前 (2018-06-27) 1875℃ 0评论6喜欢
Wordpress的功能很强大,可以根据自己的需求来修改自己的网站。在Wordpress 3.5.1的中提供了默认的主题Twenty Twelve,很不错,但是首页显示的是全文信息,这不仅使得页面太长,也使得加载速度变的很慢,只有在搜索的时候才会显示摘要,那么怎么去让首页显示文章的摘要呢?到wordpress后台,依次选择 外观-->编辑-->选择右边的 w397090770 12年前 (2013-03-31) 27243℃ 9评论26喜欢
在Wordpress后台的设置->阅读->博客页面至多显示里面可以设置每页最多显示的文章数目,但是那个设置只能将所有的类别(首页、分类目录页、标签页、作者页)显示的文章数都设置成一个值。 但是在开发Wordpress主题的时候,有些需求需要修改不同类别的每页显示的文章数。比如首页显示10篇;分类页显示20篇;标签页显示3 w397090770 10年前 (2014-11-30) 6293℃ 0评论7喜欢
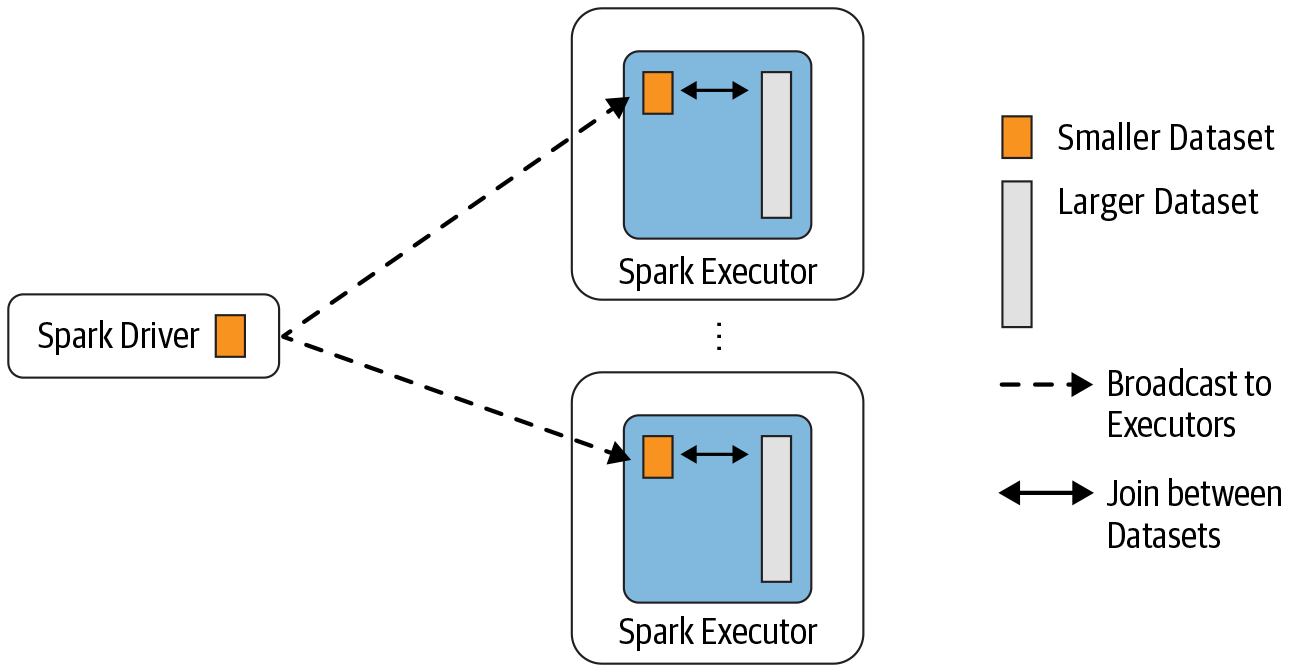
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 4年前 (2020-09-13) 5157℃ 0评论13喜欢
在Sortable公司,很多数据处理的工作都是使用Spark完成的。在使用Spark的过程中他们发现了一个能够提高Spark job性能的一个技巧,也就是修改数据的分区数,本文将举个例子并详细地介绍如何做到的。查找质数比如我们需要从2到2000000之间寻找所有的质数。我们很自然地会想到先找到所有的非质数,剩下的所有数字就是我们要找 w397090770 9年前 (2016-06-24) 23523℃ 2评论45喜欢
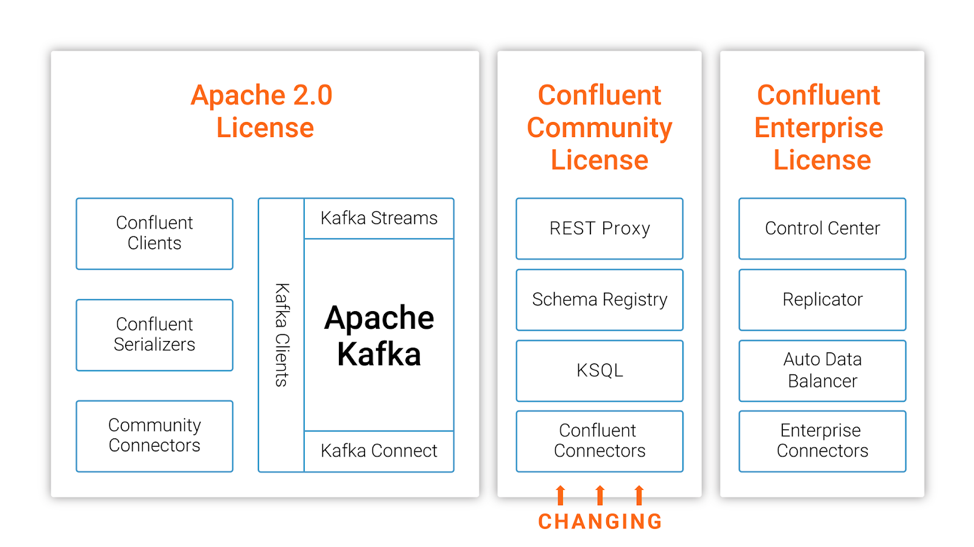
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 6年前 (2018-12-15) 2009℃ 0评论3喜欢
在实际开发过程中,我们可能会每开发一些代码就会把这些代码进行提交,以防止一些意外;但是随着提交的 commits 数越来越多,一方面维护起来不便,另一方面可能会造成版本控制的混乱,为了解决这个问题,我们可以把多个 commit 合并成一个。比如下面这个 MR 一共提交了两次:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 3年前 (2021-07-31) 1158℃ 0评论3喜欢
我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 7年前 (2018-01-14) 10165℃ 2评论23喜欢
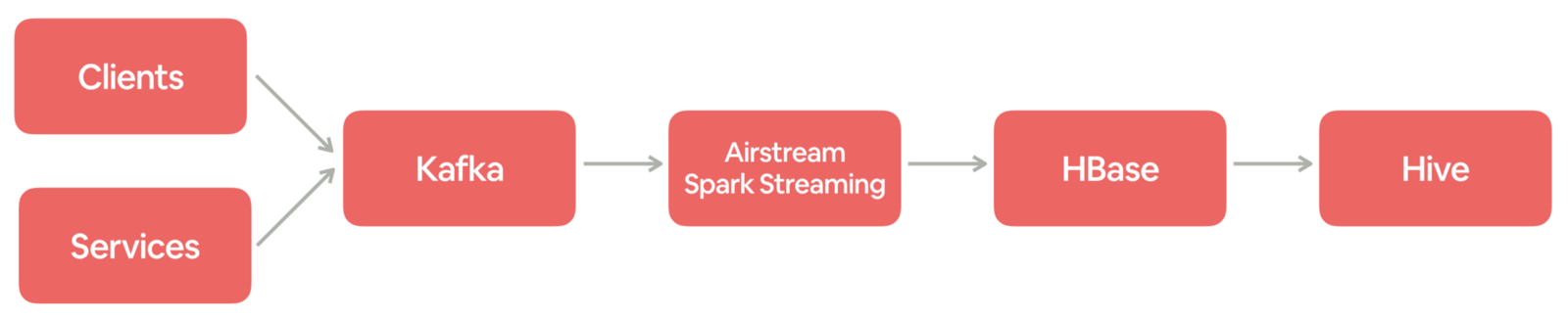
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 6年前 (2019-05-19) 2868℃ 0评论8喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简要的介绍,本文将对Spark RDD的checkpint相关的代码进行相关的 w397090770 9年前 (2015-11-25) 8917℃ 5评论14喜欢
hljs.initHighlightingOnLoad(); 我们往已经部署好的Kafka集群里面添加机器是最正常不过的需求,而且添加起来非常地方便,我们需要做的事是从已经部署好的Kafka节点中复制相应的配置文件,然后把里面的broker id修改成全局唯一的,最后启动这个节点即可将它加入到现有Kafka集群中。 但是问题来了,新添加的Kafka节点并不会 w397090770 9年前 (2016-03-24) 12776℃ 2评论23喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 324℃ 0评论0喜欢
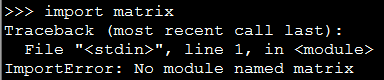
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 57128℃ 0评论14喜欢
为什么选择Spark SequoiaDB是NoSQL数据库,它可以将数据复制到不同的物理节点上,而且用户可以在应用程序中指定使用哪个备份块。它能够在同一个集群中使用最少的I/O或者CPU来分析或者操作一些工作。 Apache Spark和SequoiaDB的整合允许用户创建单个平台来在同一个物理集群上同时运行多种不同的workloads 。Spark-SequoiaDB Conne w397090770 9年前 (2015-08-05) 4604℃ 0评论2喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive最初是应Facebook每天 w397090770 11年前 (2013-12-18) 16853℃ 2评论31喜欢
默认情况下,Apache Zeppelin启动Spark是以本地模式起的,master的值是local[*],我们可以通过修改conf/zeppelin-env.sh文件里面的MASTER的值如下:[code lang="bash"]export MASTER= yarn-clientexport HADOOP_HOME=/home/q/hadoop/hadoop-2.2.0export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/[/code]然后启动Zeppelin,但是我们有时会发现日志出现了以下的异常信息:ERRO w397090770 9年前 (2016-01-22) 12091℃ 16评论12喜欢
在Hive0.8开始支持Insert into语句,它的作用是在一个表格里面追加数据。标准语法语法如下:[code lang="sql"]用法一:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;用法二:INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;[/code w397090770 11年前 (2013-10-30) 102220℃ 2评论70喜欢
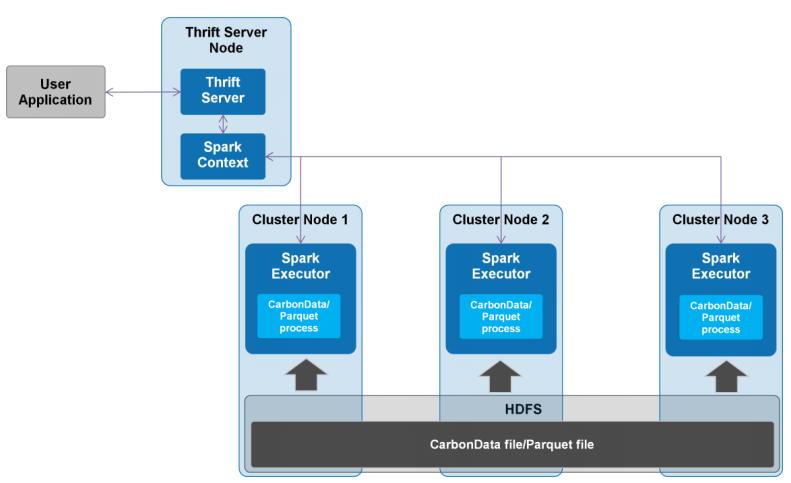
本文相关测试数据由华为陈亮大神提供,特别感谢。 Apache CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化过程中。详细介绍可以参见(《CarbonData:华为开发并支持Hadoop的 w397090770 8年前 (2016-09-11) 8273℃ 1评论7喜欢
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。业务通常已不再满足滞后的分析结果,希望看到更实时的数据,从而在第一时间做出判断和决策。典型的场景如电商大促和金融风控等,基于延迟数 w397090770 4年前 (2020-06-08) 3934℃ 0评论3喜欢
美国当地时间2020年05月11日,Apache Hudi 项目的共同创始人、PMC Vinoth Chandar 给社区发了一封标题为 [DISCUSS] Graduate Apache Hudi (Incubating) as a TLP 的邮件,来投票讨论 Apache Hudi 毕业成为 Apache TLP 项目。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop2020年05月19日共40人投票赞成 。不久社区给 Apache 董事 w397090770 5年前 (2020-05-22) 1192℃ 0评论1喜欢
虽然在运行Hadoop的时候可以打印出大量的运行日志,但是很多时候只通过打印这些日志是不能很好地跟踪Hadoop各个模块的运行状况。这时候编译与调试Hadoop源码就得派上场了。这也就是今天本文需要讨论的。编译Hadoop源码 先说说怎么编译Hadoop源码,本文主要介绍在Linux环境下用Maven来编译Hadoop。在编译Hadoop之前,我们 w397090770 11年前 (2014-01-09) 19936℃ 0评论10喜欢
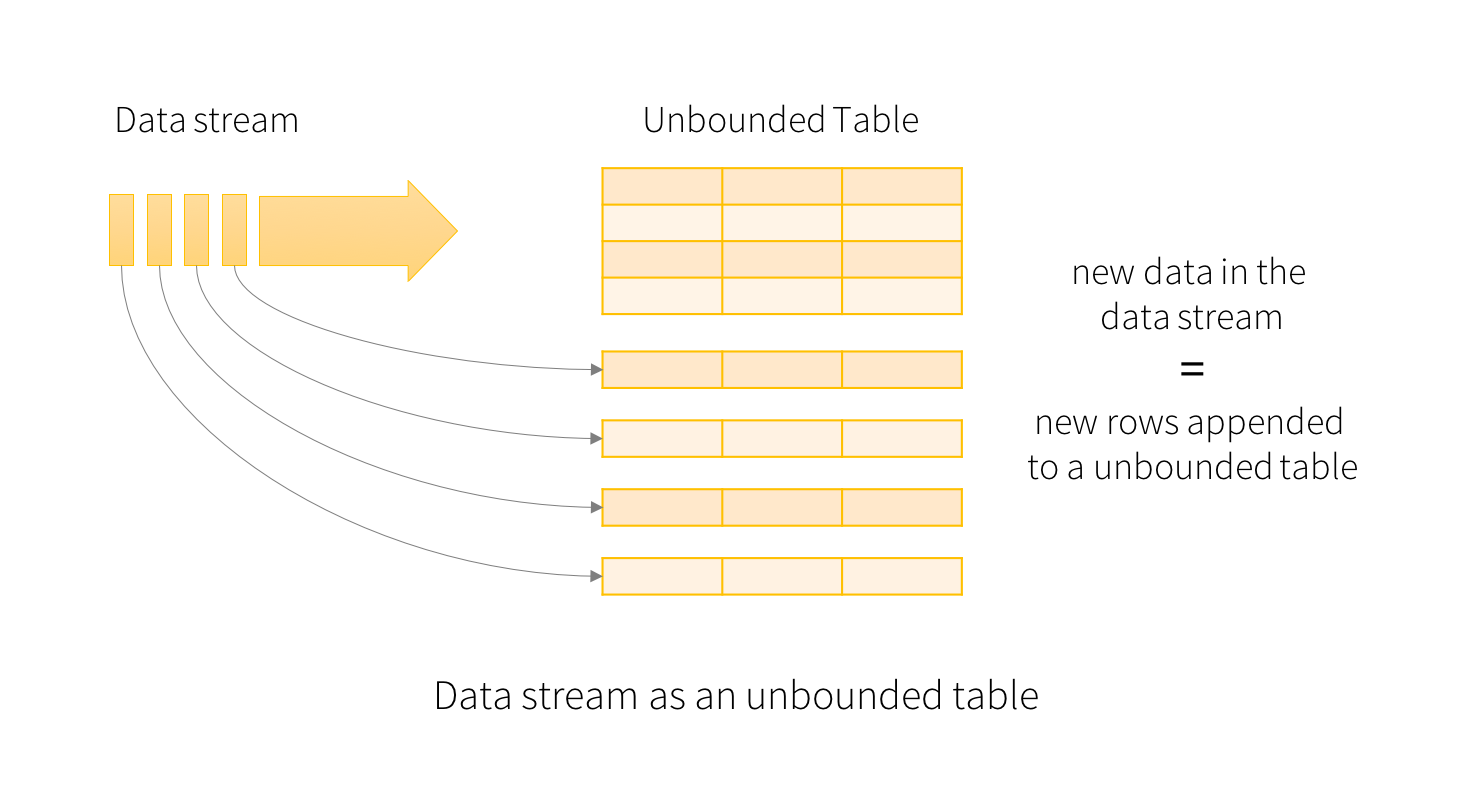
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10771℃ 2评论11喜欢
最近几年关于Apache Spark框架的声音是越来越多,而且慢慢地成为大数据领域的主流系统。最近几年Apache Spark和Apache Hadoop的Google趋势可以证明这一点:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop上图已经明显展示出最近五年,Apache Spark越来越受开发者们的欢迎,大家通过Google搜索更多关 w397090770 8年前 (2017-04-12) 6682℃ 0评论46喜欢



![[电子书]Introduction to Apache Flink PDF下载](https://www.iteblog.com/pic/books/Introduction_to_Apache_Flink_iteblog.jpg)