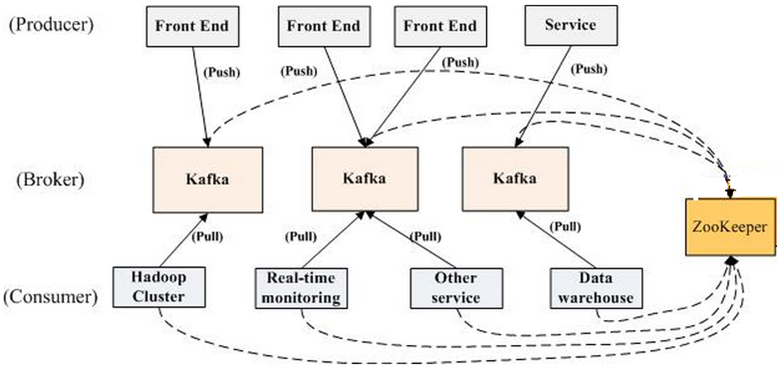
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 6年前 (2019-06-11) 12858℃ 2评论42喜欢
为什么要升级在2017年底, Hadoop3.0 发布了,到目前为止, Hadoop 发布的最新版本为3.2.1。在 Hadoop3 中有很多有用的新特性出现,如支持 ErasureCoding、多 NameNode、Standby NameNode read、DataNode Disk Balance、HDFS RBF 等等。除此之外,还有很多性能优化以及 BUG 修复。其中最吸引我们的就是 ErasureCoding 特性,数据可靠性保持不变的情况下可以降 w397090770 5年前 (2020-01-05) 2596℃ 0评论11喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase w397090770 5年前 (2020-02-23) 3001℃ 0评论6喜欢
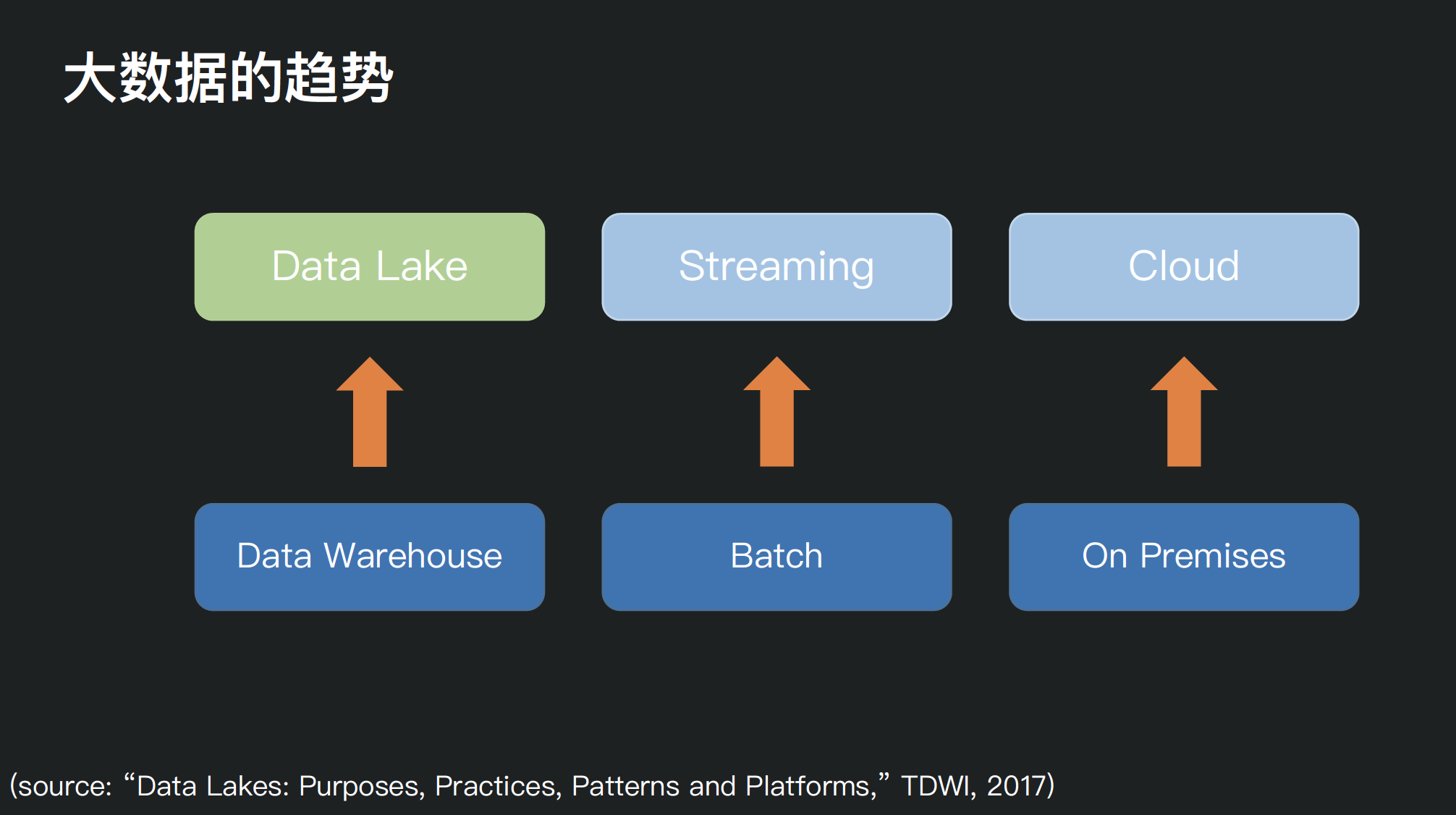
本文资料来自2020年9月5日由快手技术团队主办的快手大数据平台架构技术交流会,分享者邵赛赛,腾讯数据平台部数据湖内核技术负责人,资深大数据工程师,Apache Spark PMC member & committer, Apache Livy PMC member,曾就职于 Hortonworks,Intel 。随着大数据存储和处理需求的多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式 w397090770 4年前 (2020-09-07) 4534℃ 3评论8喜欢
在Debian平台,请输入以下的命令[code lang="JAVA"]$ sudo vi /etc/apt/sources.list[/code]在里面加入下面的一行[code lang="JAVA"]deb http://ftp.us.debian.org/debian/ squeeze main non-free[/code]然后保存退出(:wq)之后,执行下面的命令[code lang="JAVA"]$ sudo apt-get update[/code]安装Java执行环境运行下面命令[code lang="JAVA"]$ sudo apt-get install sun-java6-jre[/ w397090770 11年前 (2013-10-21) 6171℃ 2评论3喜欢
Flink China社区线下 Meetup·北京站会议于 2018年8月11日 在朝阳区酒仙桥北路恒通国际创新园进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程13:40-13:50 莫问 出品人开场发言13:50-14:30 Flink Committer星罡《Flink状态管理和恢复技术介绍》,详细请见这里14:30-15:10 滴滴 余海琳《Flink在 zz~~ 6年前 (2018-08-14) 2960℃ 0评论4喜欢
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过下面的命令来启动Hadoop历史服务器[code lang="JAVA"]$ sbin/mr-jobhistory-daemon.sh start historyserver w397090770 11年前 (2014-02-17) 29863℃ 8评论30喜欢
我们在《Apache Cassandra 简介》文章中介绍了 Cassandra 的数据模型类似于 Google 的 Bigtable,对应的开源实现为 Apache HBase,而且我们在 《HBase基本知识介绍及典型案例分析》 文章中简单介绍了 Apache HBase 的数据模型。按照这个思路,Apache Cassandra 的数据模型应该和 Apache HBase 的数据模型很类似,那么这两者的数据存储模型是不是一样的呢? w397090770 6年前 (2019-04-28) 1768℃ 0评论4喜欢
我们知道,电脑里面的10000的数阶乘结果肯定是不能用int类型存储的,也就是说,平常的方法是不能来求得这个结果的。下面,我介绍一些用向量来模拟这个算法,其中向量里面的每一位都是代表一个数。[code lang="CPP"]#include <iostream>#include <vector>using namespace std;//就是n的阶乘void calculate(int n){ vector<int> v w397090770 12年前 (2013-03-31) 3886℃ 0评论5喜欢
在提交作业的时候出现了以下的异常信息:[code lang="scala"]2015-05-05 11:09:28,071 INFO [Driver] - Attempting to load checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-14307949860002015-05-05 11:09:28,076 WARN [Driver] - Error reading checkpoint from file hdfs://iteblogcluster/user/iteblog/checkpoint2/checkpoint-1430794986000java.io.InvalidClassException: org.apache.spark.streaming w397090770 10年前 (2015-05-10) 18786℃ 0评论7喜欢
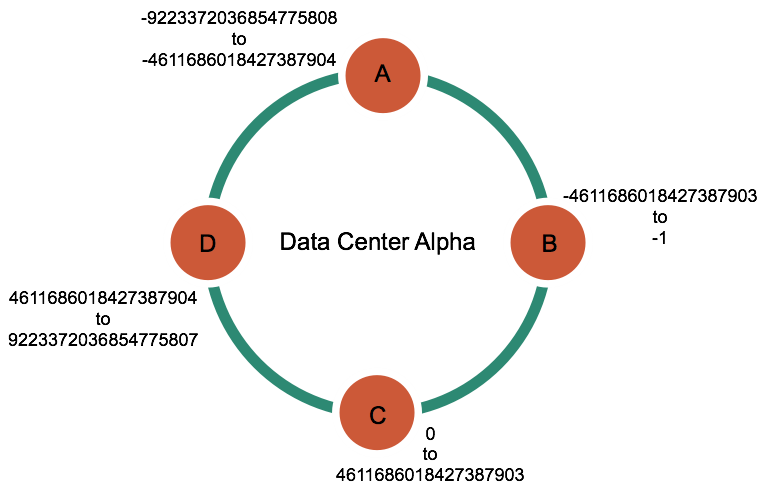
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源 w397090770 10年前 (2015-04-08) 7931℃ 2评论16喜欢
背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 7年前 (2018-05-28) 27164℃ 409评论62喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-06) 5319℃ 0评论7喜欢
Apache Spark 2.4 是在11月08日正式发布的,其带来了很多新的特性具体可以参见这里,本文主要介绍这次为复杂数据类型新引入的内置函数和高阶函数。本次 Spark 发布共引入了29个新的内置函数来处理复杂类型(例如,数组类型),包括高阶函数。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop w397090770 6年前 (2018-11-21) 2483℃ 0评论2喜欢
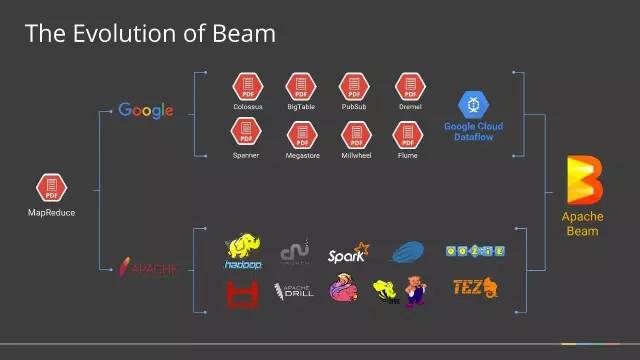
1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源。 2003年,谷歌发布了著名的大数据三篇论文,史称三驾马车:Google FS、MapReduce、BigTable。虽然谷歌没有公布这三个产品的源码,但是她这三个产品的详细设计论文开启了全球的大数据时代!从Doug Cutting大神根据 w397090770 8年前 (2017-02-10) 1807℃ 0评论4喜欢
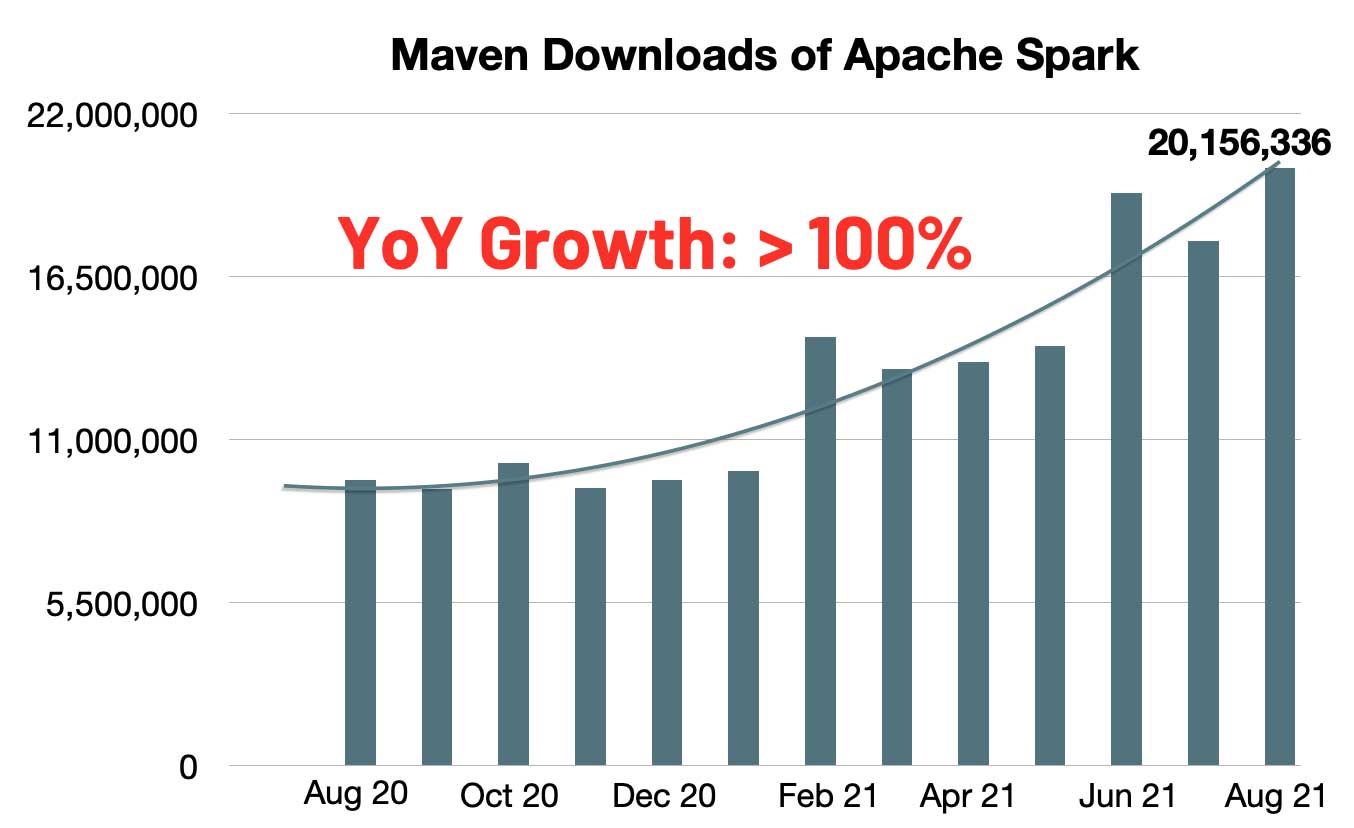
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 w397090770 3年前 (2021-10-20) 1347℃ 0评论3喜欢
Apache Spark社区刚刚发布了1.5版本,大家一定想知道这个版本的主要变化,这篇文章告诉你答案。DataFrame执行后端优化(Tungsten第一阶段) DataFrame可以说是整个Spark项目最核心的部分,在1.5这个开发周期内最大的变化就是Tungsten项目的第一阶段已经完成。主要的变化是由Spark自己来管理内存而不是使用JVM,这样可以避免JVM w397090770 9年前 (2015-09-09) 4796℃ 0评论14喜欢
Spark 0.9.2于昨天(2014年07月23日)发布。对,你没看错,是Spark 0.9.2。Spark 0.9.2是基于0.9的分枝,修复了一些bug,推荐所有使用0.9.x的用户升级到这个稳定版本。有28位开发者参与了这次版本的开发。虽然Spark已经发布了Spark 1.0.x,但是里面有不少的bug,这次的Spark是稳定版。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关 w397090770 10年前 (2014-07-24) 4638℃ 0评论3喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3458℃ 0评论8喜欢
在TCP/IP状态图中,有很多种的状态,它们之间有的是可以互相转换的,也就是说,从一种状态转到另一种状态,但是这种转换不是随便发送的,是要满足一定的条件。TCP/IP状态图看起来更像是自动机。下图即为TCP/IP状态。由上图可以看出,一共有11种不同的状态。这11种状态描述如下: CLOSED:关闭状态,没有连接活动或正在进 w397090770 12年前 (2013-04-03) 11291℃ 0评论15喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《Learning Spark》O'Reilly,2015-01 电子书下载:进入下载《Advanced Analytics with Spark》 O'Reilly,2015-04 电子书下载:进入下载如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《High Performance Spark》O'Reilly 2016-03 出 w397090770 8年前 (2017-02-12) 6741℃ 0评论18喜欢
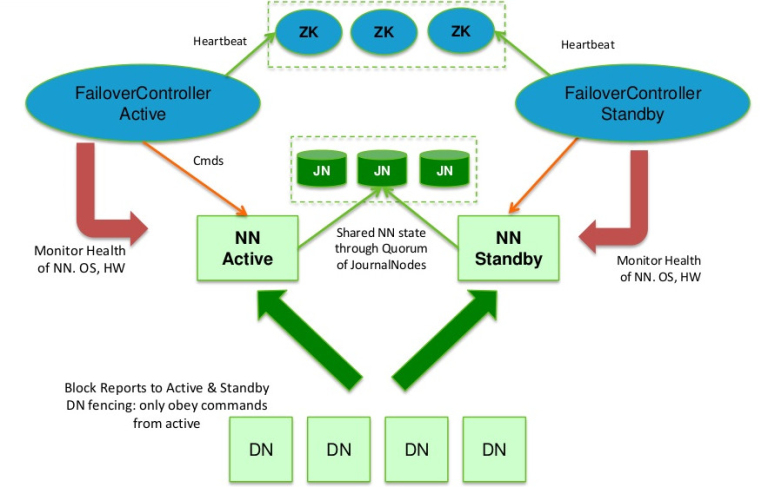
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 11年前 (2013-11-14) 10658℃ 3评论22喜欢
《Spark RDD API扩展开发(1)》、《Spark RDD API扩展开发(2):自定义RDD》 我们都知道,Apache Spark内置了很多操作数据的API。但是很多时候,当我们在现实中开发应用程序的时候,我们需要解决现实中遇到的问题,而这些问题可能在Spark中没有相应的API提供,这时候,我们就需要通过扩展Spark API来实现我们自己的方法。我们可 w397090770 10年前 (2015-03-30) 7217℃ 2评论15喜欢
在本博客的《Spark将计算结果写入到Mysql中》文章介绍了如果将Spark计算后的RDD最终 写入到Mysql等关系型数据库中,但是这些写操作都是自己实现的,弄起来有点麻烦。不过值得高兴的是,前几天发布的Spark 1.3.0已经内置了读写关系型数据库的方法,我们可以直接在代码里面调用。 Spark 1.3.0中对数据库写操作是通过DataFrame类 w397090770 10年前 (2015-03-17) 13553℃ 6评论16喜欢
今天我有一个网站空间到期了,如果去续费空间是可以的,但是那空间是国内的,一般国内的空间都是比较贵,所以我突然想到为什么不一个网站空间配置两个独立的网站呢?虽然网站空间是一样的,但是结果配置可以使得两个不同域名访问的网站不一样,也就是说互不干扰。当然这个前提是你空间所在的服务器支持我们把一 w397090770 12年前 (2013-04-26) 4773℃ 1评论5喜欢
WordPress作为一个很优秀的博客程序,已然被很多人使用,但盛名必然引来注意,更少不了那些不怀好意黑客。因此,加固WP成为个人博客安全防御的工作之一。 升级自己的WP到最新版。 一般来说,新的WP会修复老版本的一些漏洞,这样升级会使得网站安全。比如很多版本的WP可以使用 pingback 的远程端口扫描问题,该问题可能导致 w397090770 12年前 (2013-04-04) 3311℃ 0评论2喜欢
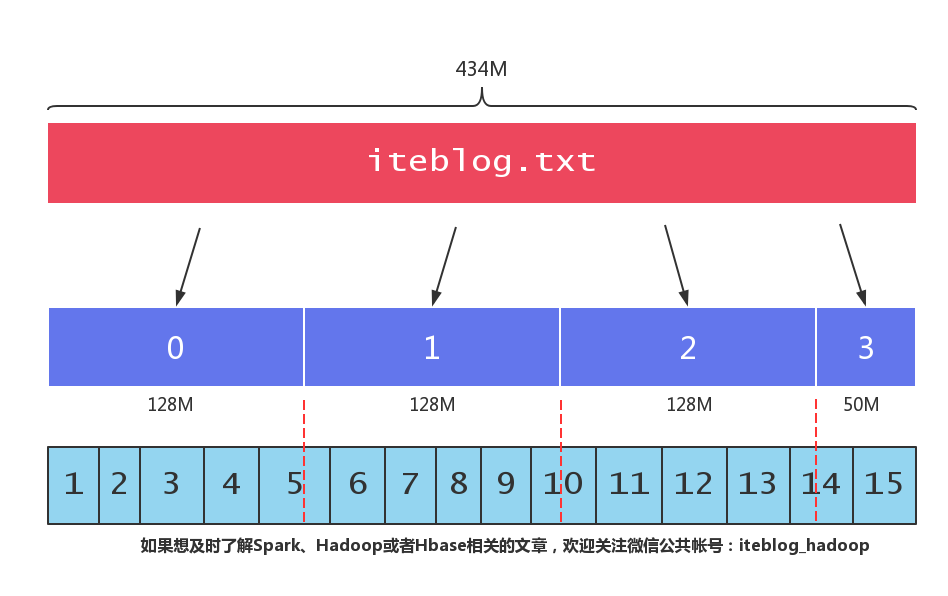
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2682℃ 4评论28喜欢
导语:此套面试题来自于各大厂的真实面试题及常问的知识点。如果能理解吃透这些问题,你的大数据能力将会大大提升,进入大厂指日可待。如果公司急招人,你回答出来面试官70%,甚至50%的问题他都会要你,如果这个公司不是真正缺人,或者只是作人才储备,那么你回答很好,他也可能不要你,只是因为没有眼缘;所以面 zz~~ 3年前 (2021-09-24) 2315℃ 0评论9喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1386℃ 0评论1喜欢
最近由Reynold Xin给Spark开发者发布的一封邮件透露,Spark社区很有可能会跳过Spark 1.7版本的发布,而直接转向Spark 2.x。 如果Spark 2.x发布,那么它将: (1)、Spark编译将默认使用Scala 2.11,但是还是会支持Scala 2.10。 (2)、移除对Hadoop 1.x的支持。不过也有可能移除对Hadoop 2.2以下版本的支持,因为Hadoop 2.0和2.1版本分 w397090770 9年前 (2015-11-13) 6988℃ 0评论16喜欢