目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 w397090770 5年前 (2020-03-05) 3976℃ 0评论2喜欢
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop背景HDFS是业界默认的 w397090770 5年前 (2020-05-26) 1930℃ 1评论1喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上述任务,而且还有更多的功能。与大多数下载管理器不同 w397090770 9年前 (2016-02-19) 1769℃ 0评论1喜欢
一、介绍 FairScheduler是一个资源分配方式,在整个时间线上,所有的applications平均的获取资源。Hadoop NextGen能够调度多种类型的资源。默认情况下,FairScheduler只是对内存资源做公平的调度(分配)。当集群中只有一个application运行时,那么此application占用这个集群资源。当其他的applications提交后,那些释放的资源将会被分配给新的 w397090770 9年前 (2015-12-03) 12102℃ 12评论15喜欢
经过这段时间的整理以及格式调整,以及纠正其中的一些错误修改,整理出PDF下载。下载地址:[dl href="http://download.csdn.net/detail/w397090770/8337439" rel="nofollow"]CSDN免积分下载[/dl] 完整版可以到这里下载Learning Spark完整版下载附录:Learning Spark目录Chapter 1 Introduction to Data Analysis with Spark What Is Apache Spark? A Unified Stack Who Us w397090770 10年前 (2015-01-07) 32562℃ 6评论83喜欢
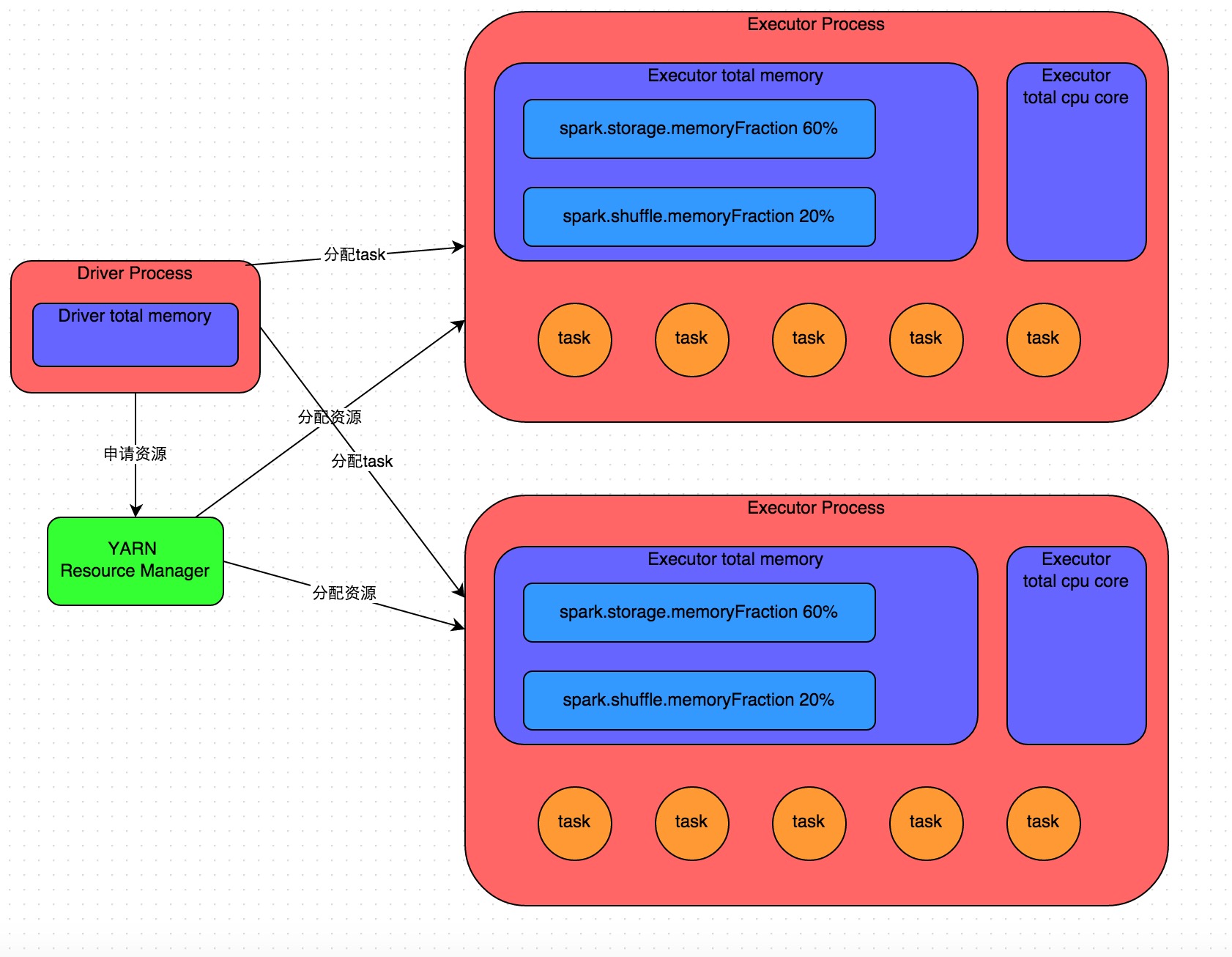
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参 w397090770 9年前 (2016-05-04) 30922℃ 8评论38喜欢
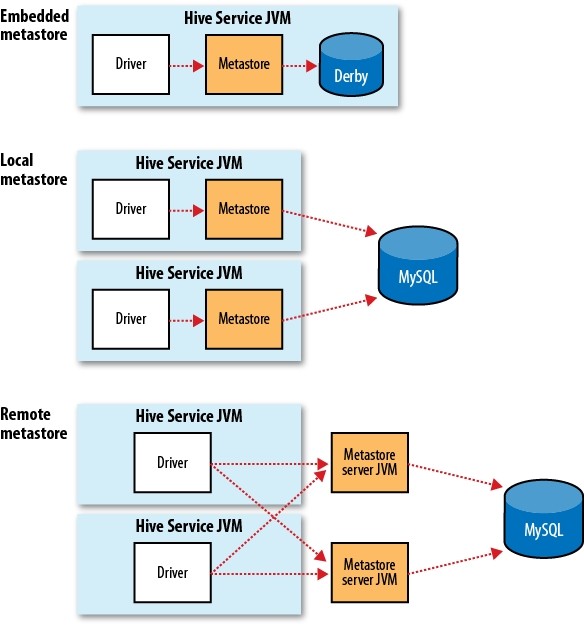
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事 Hive内部自带了许多的服务,我们可以 w397090770 11年前 (2014-02-24) 19089℃ 1评论10喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。分享主题1、中国电信在大数据领域上的创新与探索2、函数式编程与RDD3、社交网络中的信息传播4、大数据分析和机器学习5、分布式流式数据处理框架:功能对比以及性能评估详细主 zz~~ 8年前 (2016-09-20) 1794℃ 0评论2喜欢
在Wordpress后台里面有个选项是 多媒体->媒体库 里面显示的是所有文章的附件,包括了图片、视频、文件等。我们在开发Wordpress的时候,有时候需要列出文章中相应的附件,可以通过下面的方式来解决:[code lang="php"]$args = array( 'caller_get_posts' => 1, 'paged' => $paged);query_posts($args);if ( have_posts() ) : while ( have_posts w397090770 10年前 (2014-11-10) 6651℃ 1评论6喜欢
为什么选择Spark SequoiaDB是NoSQL数据库,它可以将数据复制到不同的物理节点上,而且用户可以在应用程序中指定使用哪个备份块。它能够在同一个集群中使用最少的I/O或者CPU来分析或者操作一些工作。 Apache Spark和SequoiaDB的整合允许用户创建单个平台来在同一个物理集群上同时运行多种不同的workloads 。Spark-SequoiaDB Conne w397090770 9年前 (2015-08-05) 4604℃ 0评论2喜欢
当前 velox 支持了 HDFS、S3 以及本地文件系统,其中 HDFS 和 S3 模块是需要在编译的时候显示指定的,比如我们要测试 HDFS 功能,编译 prestissimo 的时候需要显示指定 PRESTO_ENABLE_HDFS=ON,如下:[code lang="bash"]PRESTO_ENABLE_HDFS=ON make release[/code]Velox 解析 HDFS NN endpoint 逻辑核心代码如下:[code lang="CPP"]HdfsServiceEndpoint HdfsFileSystem::getServic w397090770 1年前 (2023-06-29) 692℃ 0评论3喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin w397090770 8年前 (2016-08-08) 2294℃ 0评论2喜欢
TreeMultimap类是Multimap接口的实现子类,其中的key和value都是根据默认的自然排序或者用户指定的排序规则排好序的。在任何情况下,如果你想判断TreeMultimap中两个元素是否相等,都不要使用equals方法去实现,而需要用compareTo或compare函数去判断。下面探讨一下TreeMultimap类的源码实现:[code lang="JAVA"] TreeMultimap里面一共有两 w397090770 11年前 (2013-10-09) 7405℃ 1评论2喜欢
我们在使用Hive的时候经常会使用到order by、Sort by、Distribute by和Cluster By,本文对其含义进行介绍。order by Hive中的order by和数据库中的order by 功能一致,按照某一项或者几项排序输出,可以指定是升序或者是降序排序。它保证全局有序,但是进行order by的时候是将所有的数据全部发送到一个Reduce中,所以在大数据量的情 w397090770 9年前 (2015-11-19) 14196℃ 0评论16喜欢
在Elasticsearch下,一个文档除了有数据之外,它还包含了元数据(Metadata)。每创建一条数据时,都会对元数据进行写入等操作,当然有些元数据是在创建mapping的时候就会设置,元数据在Elasticsearch下起到了非常大的作用。本文将对ElasticSearch中的元数据进行介绍,后续文章将分别对这些元数据进行解说。身份元数据(Identity meta-field w397090770 8年前 (2016-08-28) 4546℃ 0评论4喜欢
本书作者 Denny Lee, Tathagata Das, Vini Jaiswal,预计2022年4月出版,出版社 O'Reilly Media, Inc.,ISBN:9781098104528分析和机器学习模型的好坏取决于它们所依赖的数据。查询处理过的数据并从中获得见解需要一个健壮的数据管道——以及一个有效的存储解决方案,以确保数据质量、数据完整性和性能。本指南向您介绍 Delta Lake,这是一种开 w397090770 4年前 (2021-05-27) 578℃ 0评论2喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3458℃ 0评论8喜欢
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: Flink 与 Hive 集成的 w397090770 4年前 (2020-11-26) 2364℃ 0评论11喜欢
在《Zookeeper 3.4.5分布式安装手册》、《Hadoop2.2.0完全分布式集群平台安装与设置》文章中,我们已经详细地介绍了如何搭建分布式的Zookeeper、Hadoop等平台,今天,我们来说说如何在Hadoop、Zookeeper上搭建完全分布式的Hbase平台。这里同样选择目前最新版的Hbase用于配合最新版的Hadoop-2.2.0,所以我们选择了Hbase-0.96.0。 1、下载并解压HB w397090770 11年前 (2014-01-19) 11178℃ 6评论1喜欢
2022年01月10日,来自 Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 给 Ambari 社区发送了一封名为《[VOTE] Move Apache Ambari to Attic》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据邮件内容显示,在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员 w397090770 3年前 (2022-01-16) 411℃ 0评论2喜欢
这是Spark北京Meetup第四次活动,主要是SparkSQL专题。可以在这里报名,活动免费。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动时间 12月13日下午14:00活动地点 地址:淀区中关村软件园二期,西北旺东路10号院东区,亚信大厦 一层会议室 时间:13:20-13:40活动内容: w397090770 10年前 (2014-12-02) 5015℃ 0评论3喜欢
我们在用Maven编译项目的时候有时老是出现无法下载某些jar依赖从而导致整个工程编译失败,这时候我们可以修改jar下载的源(也就是repositorie)即可,下面是Maven的用法,你可以在你项目的pom文件里面加入这些代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="JAVA"]<!-- **** w397090770 10年前 (2014-07-25) 13006℃ 1评论14喜欢
Presto 是由 Facebook 开发并开源的分布式 SQL 交互式查询引擎,很多公司都是用它实现 OLAP 业务分析。本文列出了 Presto 常用的函数列表。数学函数数学函数作用于数学公式。下表给出了详细的数学函数列表。abs(x)返回 x 的绝对值。使用如下:[code lang="bash"]presto:default> select abs(1.23) as absolute; absolute ---------- 1.23[/code] w397090770 3年前 (2021-10-07) 5821℃ 0评论1喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3888℃ 0评论16喜欢
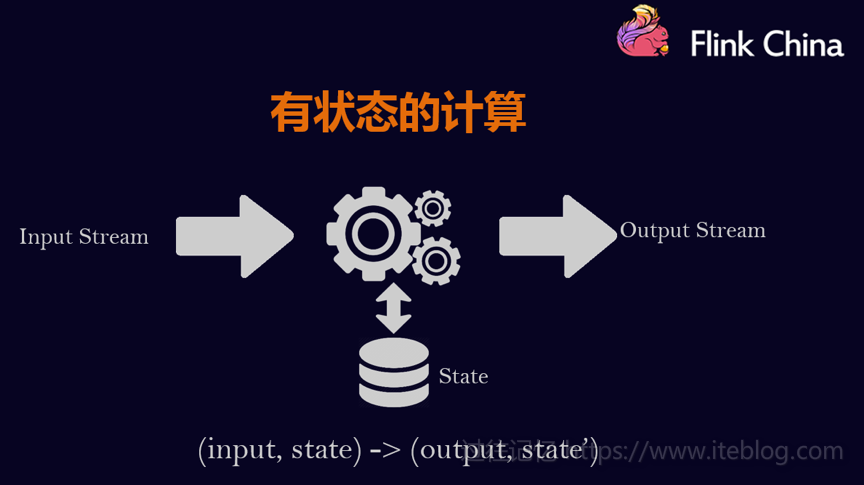
本文整理自8月11日在北京举行的 Flink Meetup 会议,分享嘉宾施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。本文由韩非(Flink China社区志愿者)整理一、有状态的流数据处理1、什么是有状态的计算计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大 w397090770 6年前 (2018-08-24) 9108℃ 0评论21喜欢
1. 集群多少台, 数据量多大, 吞吐量是多大, 每天处理多少G的数据?2. 我们的日志是不是除了apache的访问日志是不是还有其他的日志?3. 假设我们有其他的日志是不是可以对这个日志有其他的业务分析?这些业务分析都有什么?4. 你们的服务器有多少台?服务器的内存多大?5. 你们的服务器怎么分布的?(这里说地理位置 w397090770 8年前 (2016-08-26) 3443℃ 0评论4喜欢
一、活动时间 5月10日下午14:00-18:00二、活动地点北京市海淀区丹棱街5号 微软亚太研发集团总部大厦1号楼1层 地图: http://j.map.baidu.com/yVWh0三、活动内容: 1、鲁小亿 美国俄亥俄州立大学计算机科学与工程系 Senior Research Associate,演讲主题:<spark & RDMA> 2、董旭 滴滴打车 高级软件工程师,高性能计算负责 w397090770 10年前 (2015-05-05) 3049℃ 0评论6喜欢
本书作者:Rajdeep Dua、Manpreet Singh Ghotra、 Nick Pentreath,由Packt出版社于2017年04月出版,全书共532页。本书是2015年02月出版的Machine Learning with Spark的第二版。通过本书将学习到以下的知识:Get hands-on with the latest version of Spark MLCreate your first Spark program with Scala and PythonSet up and configure a development environment for Spark on your own computer, as well zz~~ 8年前 (2017-05-27) 4542℃ 0评论14喜欢
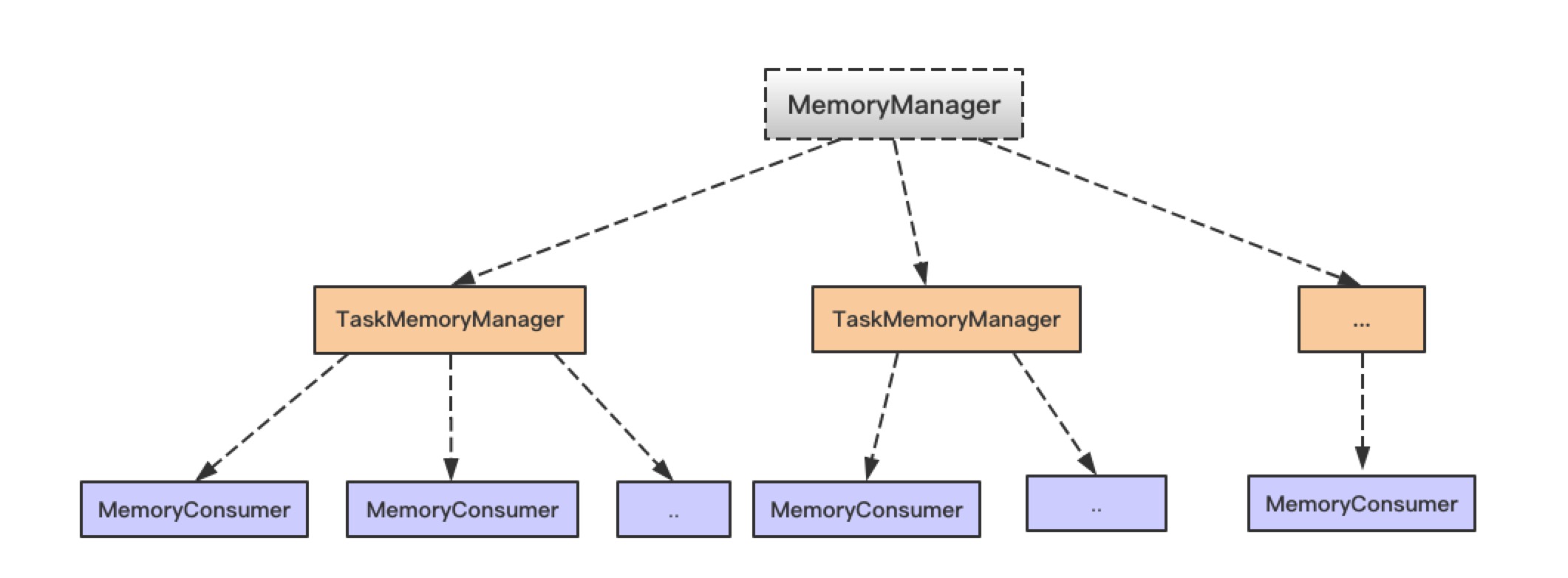
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5377℃ 0评论19喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1038℃ 0评论1喜欢

















![[电子书]Machine Learning with Spark Second Edition PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_with_Spark_Second_Edition_iteblog.jpg)
![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)