Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-20) 1343℃ 0评论1喜欢
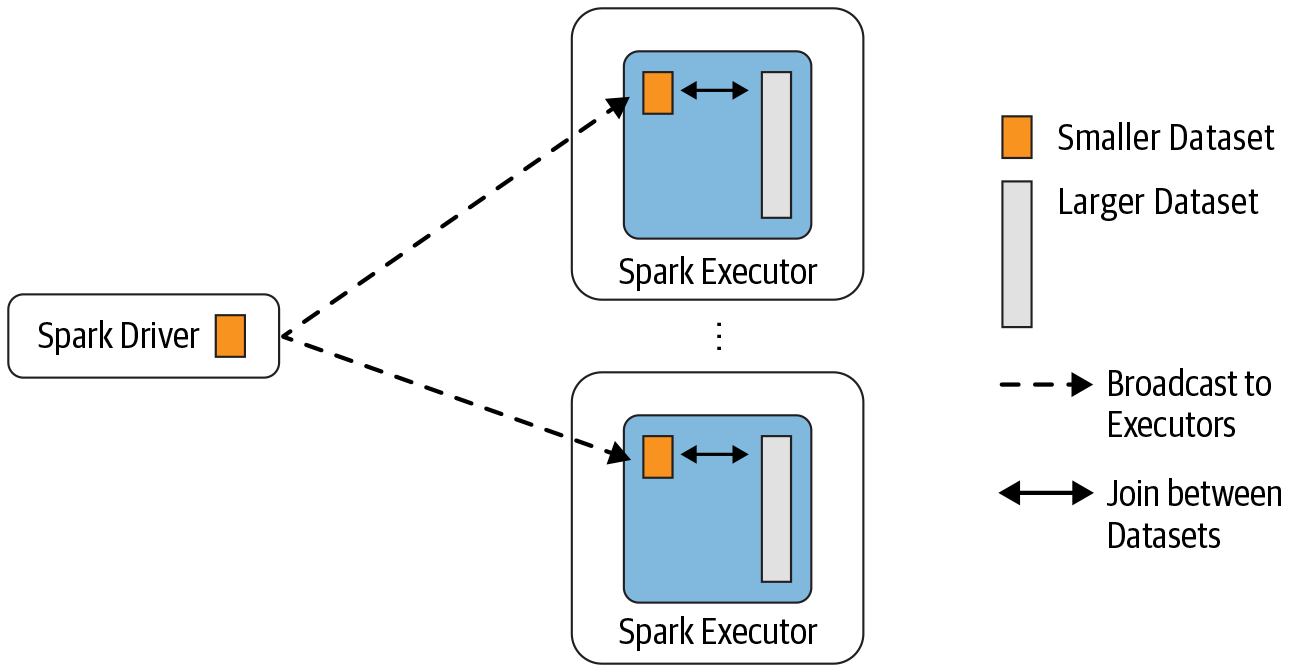
数据分析中将两个数据集进行 Join 操作是很常见的场景。在 Spark 的物理计划(physical plan)阶段,Spark 的 JoinSelection 类会根据 Join hints 策略、Join 表的大小、 Join 是等值 Join(equi-join) 还是不等值(non-equi-joins)以及参与 Join 的 key 是否可以排序等条件来选择最终的 Join 策略(join strategies),最后 Spark 会利用选择好的 Join 策略执行最 w397090770 4年前 (2020-09-13) 5157℃ 0评论13喜欢
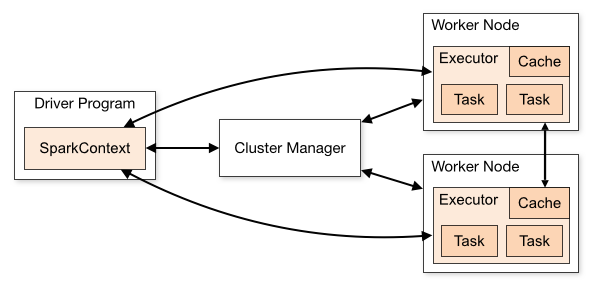
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时 w397090770 10年前 (2015-05-30) 37437℃ 2评论76喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num w397090770 4年前 (2021-02-20) 1165℃ 0评论4喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 8年前 (2017-03-02) 10336℃ 0评论6喜欢
在本博客的《Spark将计算结果写入到Mysql中》文章介绍了如果将Spark计算后的RDD最终 写入到Mysql等关系型数据库中,但是这些写操作都是自己实现的,弄起来有点麻烦。不过值得高兴的是,前几天发布的Spark 1.3.0已经内置了读写关系型数据库的方法,我们可以直接在代码里面调用。 Spark 1.3.0中对数据库写操作是通过DataFrame类 w397090770 10年前 (2015-03-17) 13553℃ 6评论16喜欢
在《从Hadoop1.x集群升级到Hadoop2.x步骤》文章中简单地介绍了如何从Hadoop1.x集群升级到Hadoop2.x,那里面只讨论了成功升级,那么如果集群升级失败了,我们该如何从失败中回滚呢?这正是本文所有讨论的。本文将以hadoop-0.20.2-cdh3u4升级到Hadoop-2.2.0升级失败后,如何回滚。 1、如果你将Hadoop1.x升级到Hadoop2.x的过程中失败了,当你 w397090770 11年前 (2013-12-05) 5853℃ 1评论7喜欢
来自于requests的灵感,因为它很简单;并且由lxml驱动,因为它速度很快。 Newspaper是一个惊人的新闻、全文以及文章元数据抽取开源的Python类库,这个类库支持10多种语言,所有的东西都是用unicode编码的。我们可以使用下面命令查看:[code lang="python"]/** * User: 过往记忆 * Date: 2015-05-20 * Time: 下午23:14 * bolg: * 本文地 w397090770 10年前 (2015-05-20) 2770℃ 0评论0喜欢
为什么禁止推酷网站收录本博客文章 近一段时间观察发现,推酷网站 在我发出文章不到几分钟内就收录了,由于我网站权重很低,导致从搜索引擎里面搜索到的文章很多直接链接到推酷网站,而不能显示到我博客,这严重影响我网站! 这就是为什么每次我发文章开始都会要求回复可见。已通知推酷网处理 本 w397090770 10年前 (2014-10-17) 14188℃ 15评论65喜欢
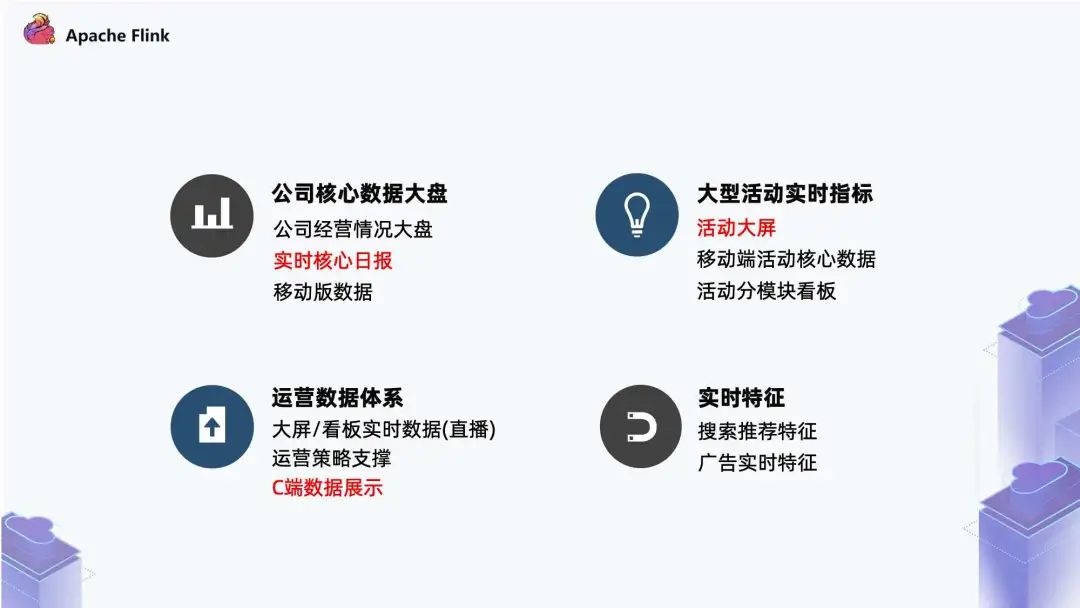
一、快手实时计算场景快手业务中的实时计算场景主要分为四块: 公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板; 大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚 zz~~ 3年前 (2021-09-24) 786℃ 0评论5喜欢
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16853℃ 3评论45喜欢
我们已经在 这篇文章详细介绍了 Apache Spark Delta Lake 的事务日志是什么、主要用途以及如何工作的。那篇文章已经可以很好地给大家介绍 Delta Lake 的内部工作原理,原子性保证,本文为了学习的目的,带领大家从源码级别来看看 Delta Lake 事务日志的实现。在看本文时,强烈建议先看一下《深入理解 Apache Spark Delta Lake 的事务日志》文 w397090770 5年前 (2019-09-02) 1752℃ 0评论4喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19999℃ 1评论24喜欢
1、自动向 WordPress 编辑器插入文本 编辑当前主题目录的 functions.php 文件,并粘贴以下代码: [code lang="php"]< ?php add_filter( 'default_content', 'my_editor_content' ); function my_editor_content( $content ) { $content = "过往记忆,专注于Hadoop、Spark等"; return $content; } ?> [/code]2、获取 WordPress 注册用户数量 通过简单的 SQL 语句, w397090770 10年前 (2014-10-12) 2644℃ 0评论3喜欢
在《Hadoop 1.x中fsimage和edits合并实现》文章中提到,Hadoop的NameNode在重启的时候,将会进入到安全模式。而在安全模式,HDFS只支持访问元数据的操作才会返回成功,其他的操作诸如创建、删除文件等操作都会导致失败。 NameNode在重启的时候,DataNode需要向NameNode发送块的信息,NameNode只有获取到整个文件系统中有99.9%(可以配 w397090770 11年前 (2014-03-13) 17376℃ 3评论16喜欢
目前的Spark RDD只提供了一个基于迭代器(iterator-based)、批量更新(bulk-updatable)的接口。但是在很多场景下,我们需要扫描部分RDD便可以查找到我们要的数据,而当前的RDD设计必须扫描全部的分区(partition )。如果你需要更新某个数据,你需要复制整个RDD!那么为了解决这方面的问题,Spark开发团队正在设计一种新的RDD:IndexedRDD。它是 w397090770 10年前 (2015-02-02) 6815℃ 0评论7喜欢
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 w397090770 3年前 (2021-07-02) 1330℃ 0评论4喜欢
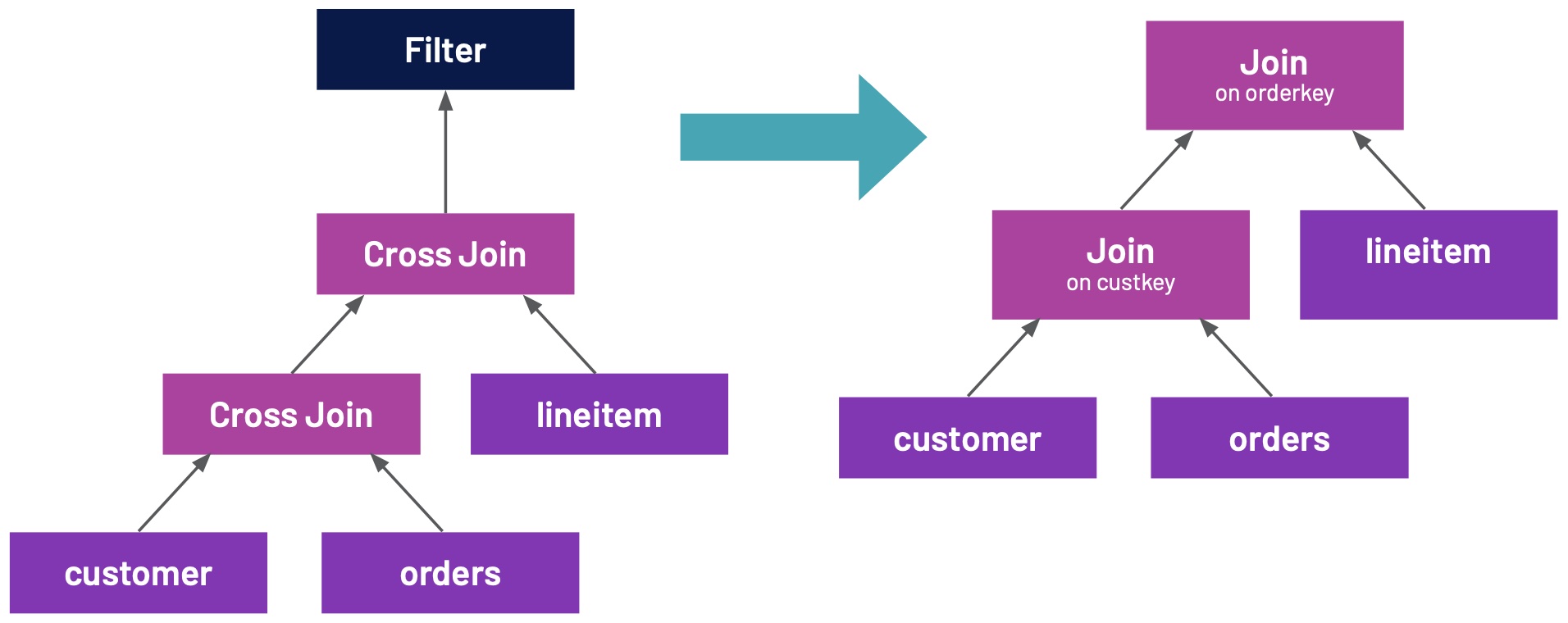
Depending on the complexity of your SQL query there are many, often exponential, query plans that return the same result. However, the performance of each plan can vary drastically; taking only seconds to finish or days given the chosen plan.That places a significant burden on analysts who will then have to know how to write performant SQL. This problem gets worse as the complexity of questions and SQL queries increases. In the abse w397090770 3年前 (2022-04-20) 642℃ 0评论1喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 3年前 (2022-01-01) 1233℃ 0评论4喜欢
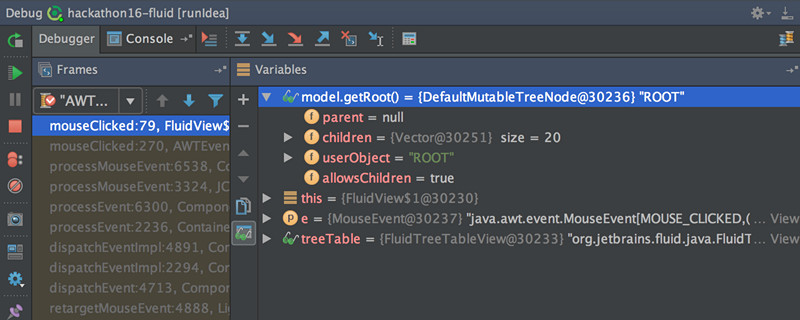
近日,被誉为最好的Java开发工具IntelliJ IDEA发布了IntelliJ IDEA 2016.2版本,这是本年度第二个发行版本。此版本带来了许多新功能,本文将列举部分比较好的功能。调试器Debugger新版本的Idea将Watches和Variables面板合在一起。此外多行表达式(multiline expressions)功能现在在断点设置中支持Condition、Evaluate和log fields,并且在Data Type w397090770 8年前 (2016-07-16) 6198℃ 0评论17喜欢
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-17) 9628℃ 6评论6喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第一篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-15) 12515℃ 2评论10喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8193℃ 0评论12喜欢
FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,采用 LGPL 或 GPL 许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库 libavcodec,为了保证高可移植性和编解码质量,libavcodec 里很多 code 都是从头开发的。如果想及时了解Spark、Hadoop或者HBase相 w397090770 4年前 (2021-04-30) 838℃ 0评论2喜欢
在我电脑里面:[code lang="JAVA"]Hadoop1.2.1中fs.default.name=hdfs://localhost:9000Hadoop2.2.0中fs.default.name=hdfs://localhost:8020[/code]所以Hive在Hadoop1.2.1中存放数据的绝对路径为:[code lang="JAVA"]hdfs://localhost:9000/home/wyp/cloud/hive/warehouse/cite[/code]其中、home/wyp/cloud/hive/warehouse/是配置文件设置的,如下:[code lang="JAVA"]<property> <name>hive w397090770 11年前 (2013-10-31) 20017℃ 1评论8喜欢
Apache CarbonData 1.4.0 于 2018年06月06日正式发布。更新内容请参见 Apache CarbonData 1.4.0 正式发布,多项新功能及性能提升。Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越 w397090770 7年前 (2018-06-12) 4292℃ 0评论18喜欢
在进程运行过程中,若其所要访问的页面不在内存而需把它们调入内存,但内存已无空闲空间时,为了保证该进程能正常运行,系统必须从内存中调出一页程序或数据送磁盘的对换区中。但应将哪个页面调出,须根据一定的算法来确定。通常,把选择换出页面的算法称为页面置换算法(Page-Replacement Algorithms)。置换算法的好坏,将直接 w397090770 12年前 (2013-04-11) 5387℃ 0评论2喜欢
Lists类主要提供了对List类的子类构造以及操作的静态方法。在Lists类中支持构造ArrayList、LinkedList以及newCopyOnWriteArrayList对象的方法。其中提供了以下构造ArrayList的函数:下面四个构造一个ArrayList对象,但是不显式的给出申请空间的大小:[code lang="JAVA"] newArrayList() newArrayList(E... elements) newArrayList(Iterable<? w397090770 11年前 (2013-09-10) 19719℃ 2评论8喜欢
背景 现状 HDFS 全称是 Hadoop Distributed File System,其本身是 Apache Hadoop 项目的一个模块,作为大数据存储的基石提供高吞吐的海量数据存储能力。自从 2006 年 4 月份发布以来,HDFS 目前依然有着非常广泛的应用,以字节跳动为例,随着公司业务的高速发展,目前 HDFS 服务的规模已经到达“双 10”的级别: 单集群节点 10 万台级别单 w397090770 3年前 (2021-07-29) 553℃ 0评论2喜欢
在Scala中存在case class,它其实就是一个普通的class。但是它又和普通的class略有区别,如下:1、初始化的时候可以不用new,当然你也可以加上,普通类一定需要加new;[code lang="scala"]scala> case class Iteblog(name:String)defined class Iteblogscala> val iteblog = Iteblog("iteblog_hadoop")iteblog: Iteblog = Iteblog(iteblog_hadoop)scala> val iteblog w397090770 9年前 (2015-09-18) 38561℃ 1评论71喜欢