本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作的 附录 二、操作DataFrame w397090770 9年前 (2016-01-17) 22981℃ 0评论23喜欢
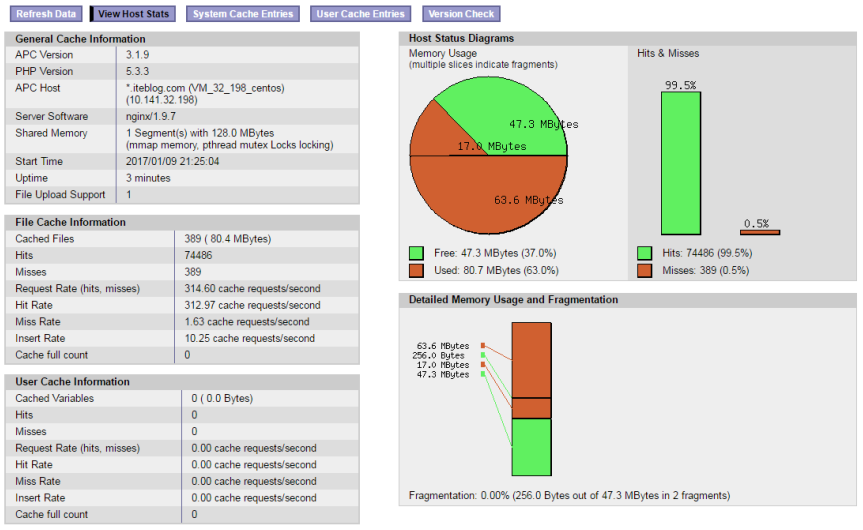
最近发现服务器php-fpm日志里面大量的Unable To Allocate Memory For Pool警告,如下:[code lang="bash"][09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 220[09-Jan-2017 01:18:08] PHP Warning: require(): Unable to allocate memory for pool. in /data/web/iteblogbooks/wp-settings.php on line 221[09-Jan-2017 01:18:08] PHP Warning: re w397090770 8年前 (2017-01-09) 2177℃ 0评论4喜欢
在《Flink本地模式安装(Local Setup)》的文章中,我简单地介绍了如何本地模式安装(Local Setup)Flink,本文将介绍如何Flink集群模式安装,主要是Standalone方式。要求(Requirements)Flink可以在Linux, Mac OS X 以及Windows(通过Cygwin)等平台上运行。集群模式主要是由一个master节点和一个或者多个worker节点组成。在你启动集群的各个组件之前 w397090770 9年前 (2016-04-20) 11888℃ 0评论9喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 8年前 (2016-12-29) 4224℃ 1评论11喜欢
到目前为止,Scala 环境下至少存在6种 Json 解析的类库,这里面不包括 Java 语言实现的 Json 类库。所有这些库都有一个非常相似的抽象语法树(AST)。而 json4s 项目旨在提供一个单一的 AST 树供其他 Scala 类库来使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopjson4s 的使用非常的简单,它可以将 w397090770 6年前 (2018-11-15) 1116℃ 0评论4喜欢
本书于2017-05由Packt Publishing出版,作者Rishi Yadav,全书294页。从书名就可以看出这是一本讲解技巧的书。本书副标题:Over 70 recipes to help you use Apache Spark as your single big data computing platform and master its libraries。本书适合数据工程师,数据科学家以及那些想使用Spark的读者。阅读本书之前最好有Scala的编程基础。通过本书你将学到以下知识 zz~~ 7年前 (2017-07-07) 4849℃ 0评论16喜欢
和Java一样,我们也可以使用Scala来创建Web工程,这里使用的是Scalatra,它是一款轻量级的Scala web框架,和Ruby Sinatra功能类似。比较推荐的创建Scalatra工程是使用Giter8,他是一款很不错的用于创建SBT工程的工具。所以我们需要在电脑上面安装好Giter8。这里以Centos系统为例进行介绍。安装giter8 在安装giter8之前需要安装Conscrip w397090770 9年前 (2015-12-18) 5798℃ 0评论10喜欢
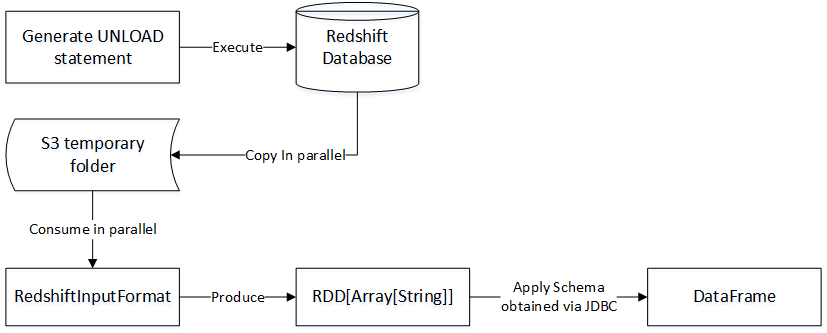
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 9年前 (2015-10-21) 3894℃ 0评论4喜欢
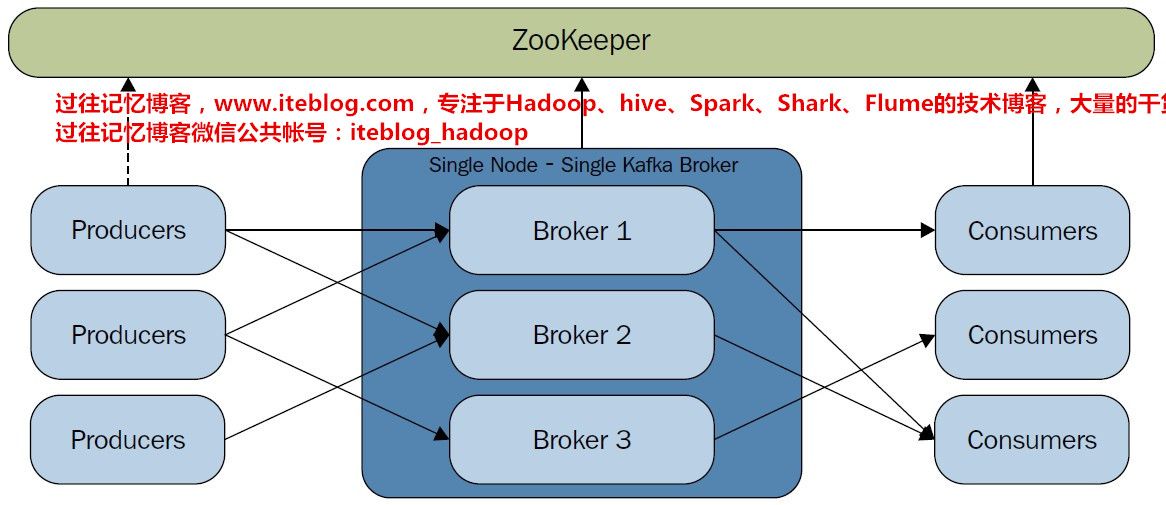
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 w397090770 7年前 (2017-11-05) 24997℃ 0评论17喜欢
前言 OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。OPPO大数据离线计算发展历史大数据行业发展阶段 一家公司的技术发展,离不开整个行业的发展背景。我们简短回归 w397090770 3年前 (2021-10-29) 755℃ 0评论2喜欢
前言本文讨论了京东搜索在实时流量数据分析方面,利用Apache Flink和Apache Doris进行的探索和实践。流式计算在近些年的热度与日俱增,从Google Dataflow论文的发表,到Apache Flink计算引擎逐渐站到舞台中央,再到Apache Druid等实时分析型数据库的广泛应用,流式计算引擎百花齐放。但不同的业务场景,面临着不同的问题,没有哪一种引 w397090770 4年前 (2020-12-25) 1303℃ 0评论4喜欢
我们在使用Spark的时候有时候需要将一些数据分发到计算节点中。一种方法是将这些文件上传到HDFS上,然后计算节点从HDFS上获取这些数据。当然我们也可以使用addFile函数来分发这些文件。addFile addFile方法可以接收本地文件(或者HDFS上的文件),甚至是文件夹(如果是文件夹,必须是HDFS路径),然后Spark的Driver和Exector w397090770 8年前 (2016-07-11) 12640℃ 0评论13喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 在前面的例子(《Apache Kafka编程入门指南:Producer篇》)中,我们学习了如何编写简单的Kafka Producer程序。在那个例子中,在如果需要发送的topic不存在,Producer将会创建它。我们都知 w397090770 9年前 (2016-02-06) 7593℃ 0评论6喜欢
Hive 内置为我们提供了大量的常用函数用于日常的分析,但是总有些情况这些函数还是无法满足我们的需求;值得高兴的是,Hive 允许用户自定义一些函数,用于扩展 HiveQL 的功能,这类函数叫做 UDF(用户自定义函数)。使用 Java 编写 UDF 是最常见的方法,但是本文介绍的是如何使用 Python 来编写 Hive 的 UDF 函数。如果想及时了解S w397090770 7年前 (2018-01-24) 14529℃ 0评论27喜欢
[caption id="attachment_751" align="aligncenter" width="536"] Guava学习之SetMultimap[/caption] SetMultimap及其子类的继承图如上所示。 SetMultimap是一个接口,继承自Multimap接口,同昨天说的ListMultimap接口类似,它也定义了所有继实现自SetMultimap的子类定义了一些共有的方法签名。SetMultimap接口并没有定义自己特有的方法签名,里面所 w397090770 11年前 (2013-09-25) 9259℃ 1评论4喜欢
我们通过分析从2015年1月至5月下载次数最多的R包,列出了前20名流行的机器学习R包。 大多数R包都深受Kagglers大神的最爱,也被资深的笔者所赞美,而这些包的使用率或评价高低不仅仅取决于其它的包对于这个 这个包的依赖程度。还也取决于Crantastic.org并使用其众包能解决方案的用户。但是,用户评价太低以至于不 w397090770 8年前 (2016-07-17) 3874℃ 0评论5喜欢
我们在编写Spark Application或者是阅读源码的时候,我们很想知道代码的运行情况,比如参数设置的是否正确等等。用Logging方式来调试是一个可以选择的方式,但是,logging方式调试代码有很多的局限和不便。今天我就来介绍如何通过IDE来远程调试Spark的Application或者是Spark的源码。本文以调试Spark Application为例进行说明,本文用到的I w397090770 10年前 (2014-11-05) 23994℃ 16评论21喜欢
最近,Delta Lake 发布了一项新功能,也就是支持直接使用 Scala、Java 或者 Python 来查询 Delta Lake 里面的数据,这个是不需要通过 Spark 引擎来实现的。Scala 和 Java 读取 Delta Lake 里面的数据是通过 Delta Standalone Reader 实现的;而 Python 则是通过 Delta Rust API 实现的。Delta Lake 是一个开源存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务 w397090770 4年前 (2021-01-05) 1152℃ 0评论0喜欢
近日,Intel开源了基于Apache Spark的分布式深度学习框架BigDL。有了BigDL之后,用户可以像编写标准的Spark程序一样来编写深度学习(deep learning)应用程序,编写完的程序还可以直接运行在现有的Spark或者Hadoop集群之上。BigDL主要有以下三大特点:[gt href="https://github.com/intel-analytics/BigDL " rel="nofollow"]BigDL GitHub地址[/gt]丰富的深度学习算法支 w397090770 8年前 (2017-01-19) 4450℃ 0评论14喜欢
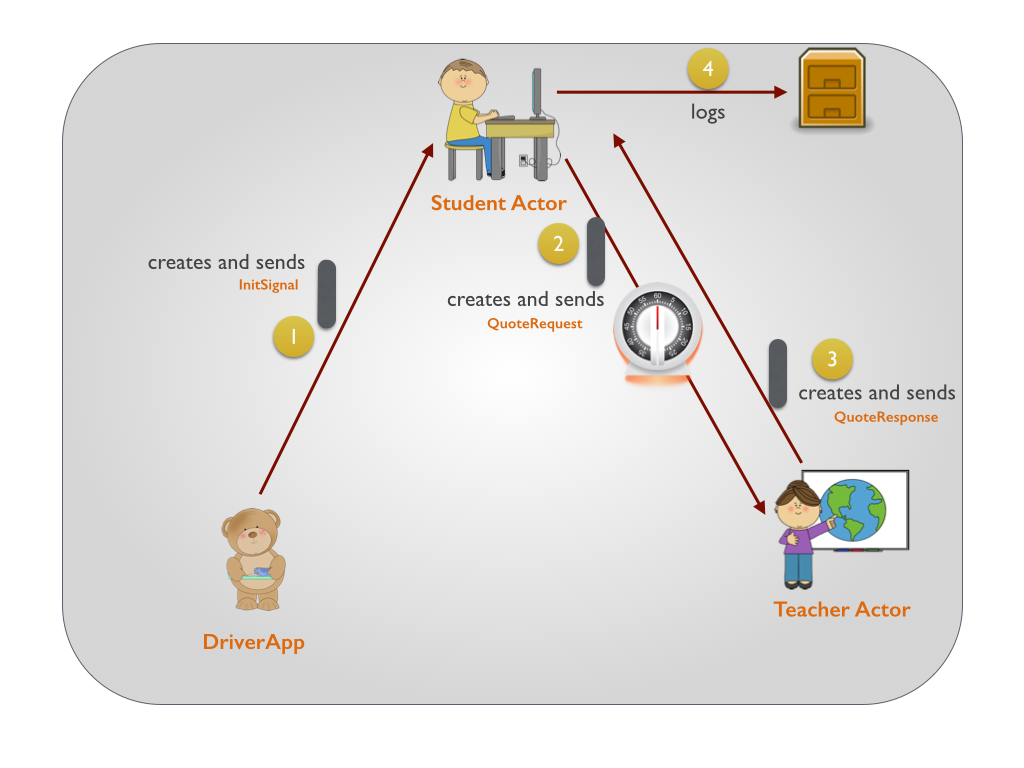
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-22) 19229℃ 3评论14喜欢
Kafka Cluster模式最大的优点:可扩展性和容错性,下图是关于Kafka集群的结构图:Kafka Broker个数决定因素 磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10 TB数据,单个broker能存储 2 TB,那么我们需要的最小Kafka集群大小 5 个broker。此外,如果启用副 w397090770 8年前 (2016-11-18) 13695℃ 0评论28喜欢
今天我有一个网站空间到期了,如果去续费空间是可以的,但是那空间是国内的,一般国内的空间都是比较贵,所以我突然想到为什么不一个网站空间配置两个独立的网站呢?虽然网站空间是一样的,但是结果配置可以使得两个不同域名访问的网站不一样,也就是说互不干扰。当然这个前提是你空间所在的服务器支持我们把一 w397090770 12年前 (2013-04-26) 4773℃ 1评论5喜欢
2010年,几个大胡子年轻人在旧金山成立了一家名为 dotCloud 的 PaaS 平台的公司。dotCloud 主要是基于 PaaS 平台为开发者或开发商提供技术服务。PaaS 的全称是 Platform as a Service,也就是平台即服务。dotCloud 把需要花费大量时间的手工工作和重复劳动抽象成组件和服务,并放到了云端,另外,它还提供了各种监控、告警和控制功能,方便开 w397090770 5年前 (2020-01-15) 862℃ 0评论8喜欢
今天谈谈Guava类库中的Multisets数据结构,虽然它不怎么经常用,但是还是有必要对它进行探讨。我们知道Java类库中的Set不能存放相同的元素,且里面的元素是无顺序的;而List是能存放相同的元素,而且是有顺序的。而今天要谈的Multisets是能存放相同的元素,但是元素之间的顺序是无序的。从这里也可以看出,Multisets肯定不是实 w397090770 12年前 (2013-07-11) 4683℃ 0评论1喜欢
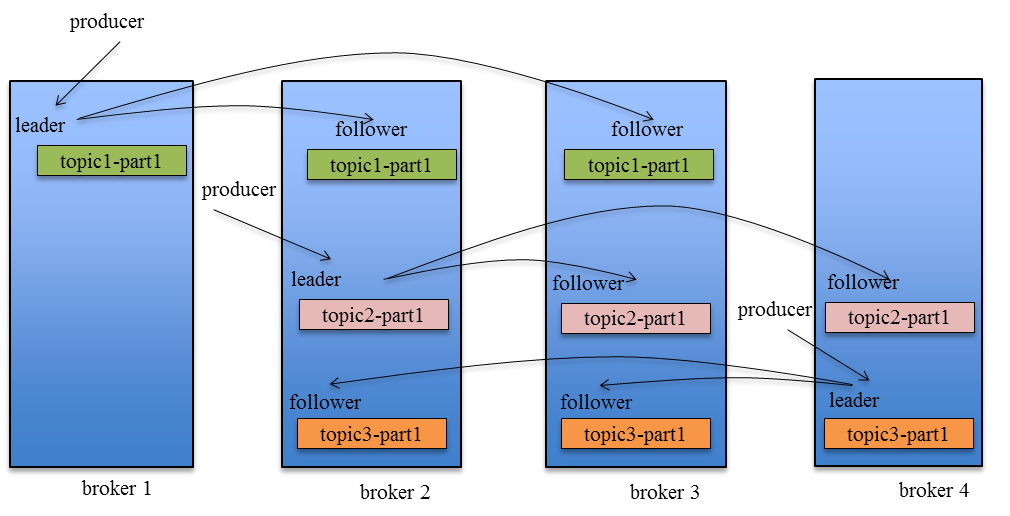
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服 w397090770 10年前 (2015-05-19) 5431℃ 0评论3喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2479℃ 2评论4喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23948℃ 1评论23喜欢
临时文件是一个暂时用来存储数据的文件。如果使用建立普通文件的方法来创建文件,则可能遇到文件是否存在,是否有文件读写权限的问题。Linux系统下提供的建立唯一的临时文件的方法如下:[code lang="CPP"]#include<stdio.h>char *tmpnam(char *s);FILE *tmpfile();[/code]函数tmpnam()产生一个唯一i的文件名。如果参量为NULL,则在一个内 w397090770 12年前 (2013-04-03) 5459℃ 0评论0喜欢
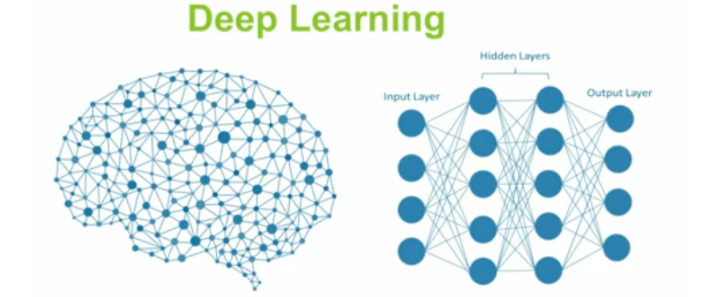
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar w397090770 7年前 (2017-11-02) 3546℃ 0评论13喜欢
Programming Hive: Data Warehouse and Query Language for Hadoop 1st Edition 于2012年09月出版,全书共350页,是学习Hive经典的一本书。图书信息如下:Publisher : O'Reilly Media; 1st edition (October 16, 2012)Language : EnglishPaperback : 350 pagesISBN-10 : 1449319335ISBN-13 : 978-1449319335这本指南将向您介绍 Apache Hive, 它是 Hadoop 的数据仓库基础设施。通过这本书将快速 w397090770 9年前 (2015-08-25) 38870℃ 3评论21喜欢



![[电子书]Apache Spark 2.x Cookbook, 2nd Edition PDF下载](https://www.iteblog.com/pic/books/apache-spark-2x-cookbook_iteblog.png)













![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)
