一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3152℃ 0评论1喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 10年前 (2014-10-10) 163706℃ 11评论384喜欢
里氏替换法则(Liskov Substitution Principle LSP)是面向对象设计的六大基本原则之一(单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则)。这里说说里氏替换法则:父类的一个方法返回值是一个类型T,子类相同方法(重载或重写)返回值为S,那么里氏替换法则就要求S必须小于等于T,也就是说要么 w397090770 11年前 (2013-09-12) 4272℃ 3评论0喜欢
本 hosts 文件更新时间为 2018年07月22日。原作者为 Google Hosts 组织本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、 w397090770 7年前 (2018-01-09) 16235℃ 1评论43喜欢
Akismet(Automattic Kismet)是应用广泛的一个垃圾留言过滤系统,其作者是大名鼎鼎的WordPress创始人Matt Mullenweg,Akismet也是WordPress默认安装的插件,其使用非常广泛,设计目标便是帮助博客网站来过滤留言spam。有了akismet之后,基本上不用担心垃圾留言的烦恼了。绝大多数wordpress blogger都在使用的Akismet可用于多种blog平台,而不仅WordPress w397090770 12年前 (2013-04-01) 6528℃ 0评论3喜欢
在这篇文章中,我将介绍如何在Spark中使用Akka-http并结合Cassandra实现REST服务,在这个系统中Cassandra用于数据的存储。 我们已经见识到Spark的威力,如果和Cassandra正确地结合可以实现更强大的系统。我们先创建一个build.sbt文件,内容如下:[code lang="scala"]name := "cassandra-spark-akka-http-starter-kit"version := "1.0" w397090770 8年前 (2016-10-17) 3876℃ 1评论5喜欢
从上周开始,我博客就经常出现了Bad Request (Invalid Hostname)错误,询问网站服务器商只得知网站的并发过高,从而被服务器商限制网站访问。可是我天天都会去看网站的流量统计,没有一点异常,怎么可能会并发过高?后来我查看了一下网站的搜索引擎抓取网站的日志,发现每分钟都有大量的页面被搜索引擎抓取!难怪网站的并 w397090770 10年前 (2014-11-14) 3211℃ 0评论6喜欢
将于2016年6月5日星期天下午1:30在杭州市西湖区教工路88号立元大厦3楼沃创空间沃创咖啡进行,本次场地由挖财公司提供。分享主题1. 陈超, 七牛:《Spark 2.0介绍》(13:30 ~ 14:10)2. 雷宗雄, 花名念钧:《spark mllib大数据实践和优化》(14:10 ~ 14:50)3. 陈亮,华为:《Spark+CarbonData(New File Format For Faster Data Analysis)》(15:10 ~ 15:50)4 w397090770 9年前 (2016-06-06) 2295℃ 0评论2喜欢
我在《使用Hive读取ElasticSearch中的数据》文章中介绍了如何使用Hive读取ElasticSearch中的数据,本文将接着上文继续介绍如何使用Hive将数据写入到ElasticSearch中。在使用前同样需要加入 elasticsearch-hadoop-2.3.4.jar 依赖,具体请参见前文介绍。我们先在Hive里面建个名为iteblog的表,如下:[code lang="sql"]CREATE EXTERNAL TABLE iteblog ( id b w397090770 8年前 (2016-11-07) 19999℃ 1评论24喜欢
我们都知道,使用Kafka Producer往Kafka的Broker发送消息的时候,Kafka会根据消息的key计算出这条消息应该发送到哪个分区。默认的分区计算类是HashPartitioner,其实现如下:[code lang="scala"]class HashPartitioner(props: VerifiableProperties = null) extends Partitioner { def partition(data: Any, numPartitions: Int): Int = { (data.hashCode % numPartitions) }}[/code] w397090770 9年前 (2016-03-29) 9222℃ 0评论9喜欢
Elasticsearch最少需要Java 7版本,在本文写作时,推荐使用Oracle JDK 1.8.0_73版本。Java的安装和平台有关,所以本文并不打算介绍如何在各个平台上安装Java。在你安装ElasticSearch之前,先运行以下的命令检查你Java的版本:[code lang="java"]java -versionecho $JAVA_HOME[/code] 一旦我们将 Java 安装完成, 我们就可以下载并安装 Elasticsearch w397090770 8年前 (2016-08-29) 1533℃ 0评论1喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-05-15) 4818℃ 0评论3喜欢
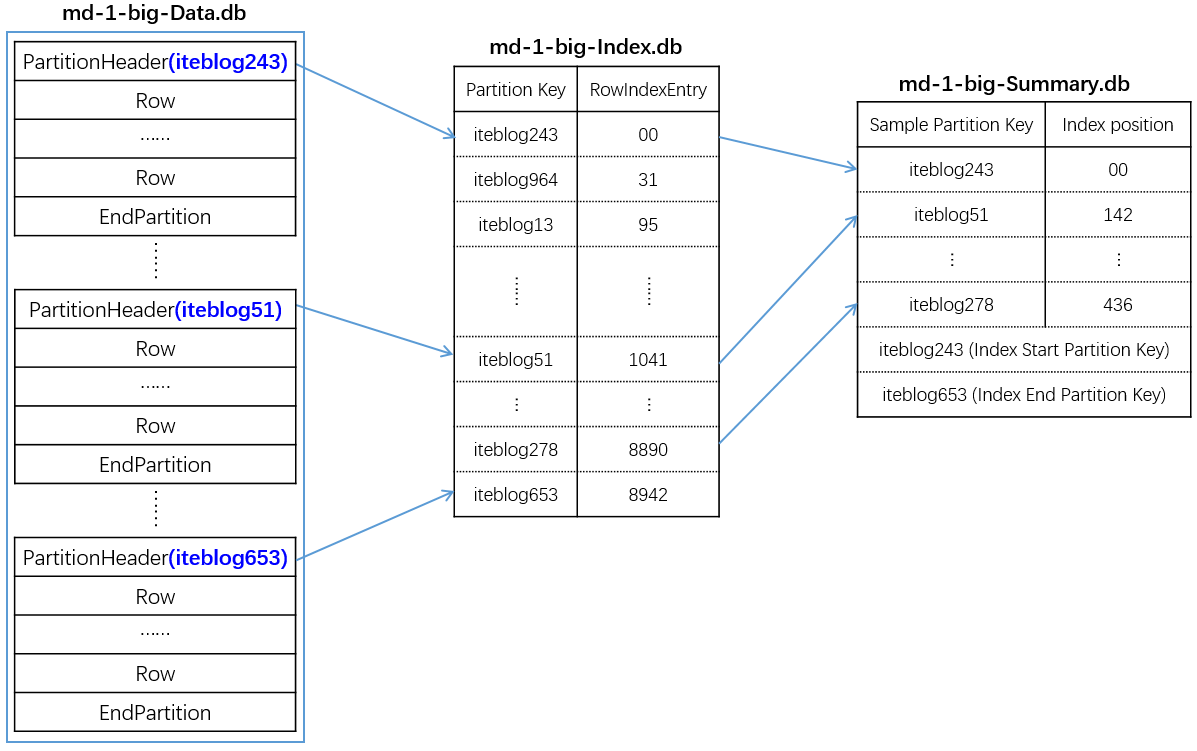
我们都知道,HDFS设计是用来存储海量数据的,特别适合存储TB、PB量级别的数据。但是随着时间的推移,HDFS上可能会存在大量的小文件,这里说的小文件指的是文件大小远远小于一个HDFS块(128MB)的大小;HDFS上存在大量的小文件至少会产生以下影响:消耗NameNode大量的内存延长MapReduce作业的总运行时间如果想及时了解Spar w397090770 8年前 (2017-04-25) 6839℃ 1评论18喜欢
课程讲师:Cloudy 课程分类:Java 适合人群:初级 课时数量:8课时 用到技术:Zookeeper、Web界面监控 涉及项目:案例实战 此视频百度网盘免费下载。本站所有下载资源收集于网络,只做学习和交流使用,版权归原作者所有,若为付费视频,请在下载后24小时之内自觉删除,若作商业用途,请购 w397090770 10年前 (2015-04-18) 34802℃ 2评论57喜欢
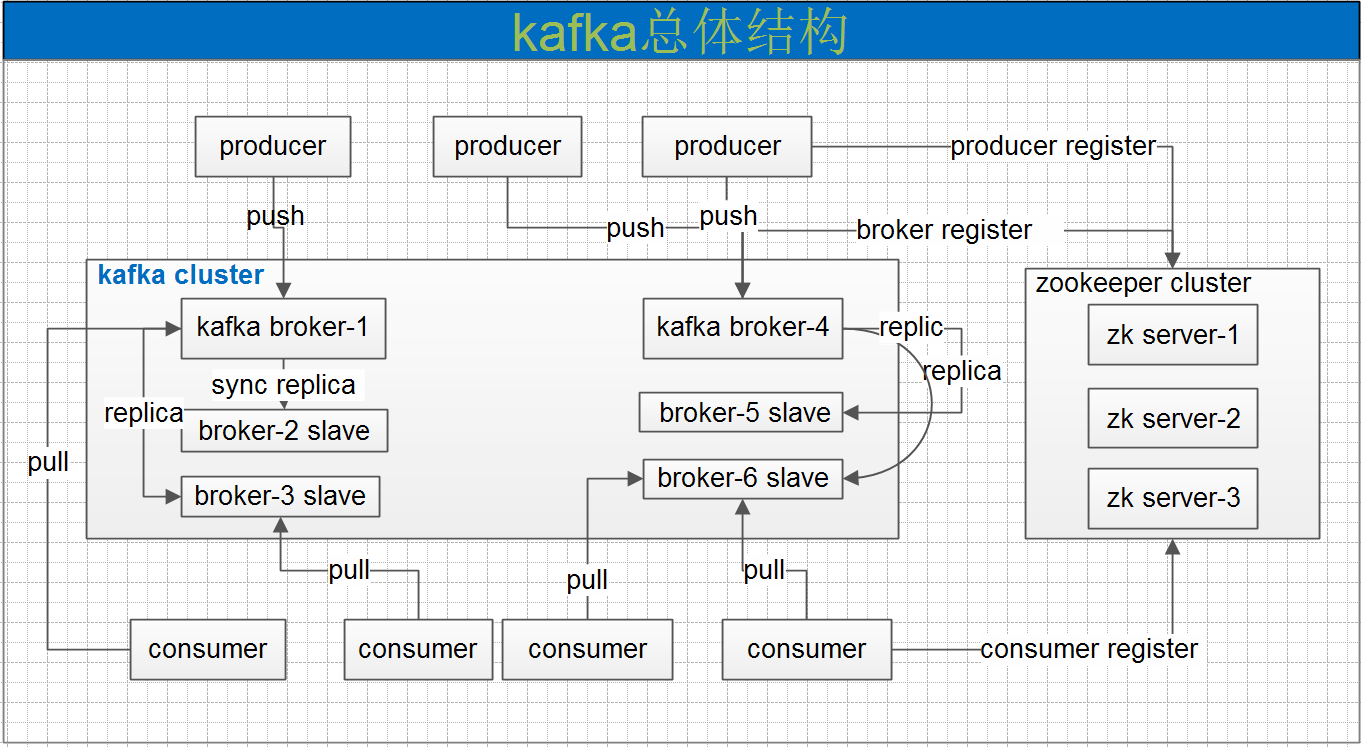
Kafka的基本介绍Kafka最初由Linkedin公司开发,是一个分布式、分区、多副本、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常用于web/nginx日志、访问日志,消息服务等等场景。Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。主要应用场景是:日志收集系统和消息系统。Kafka主要设计目标如下: w397090770 7年前 (2017-08-03) 5407℃ 0评论14喜欢
在 Cassandra 中,当达到一定条件触发 flush 的时候,表对应的 Memtable 中的数据会被写入到这张表对应的数据目录(通过 data_file_directories 参数配置)中,并生成一个新的 SSTable(Sorted Strings Table,这个概念是从 Google 的 BigTable 借用的)。每个 SSTable 是由一系列的不可修改的文件组成,这些文件在 Cassandra 中被称为 Component。本文是基于 Cas w397090770 6年前 (2019-05-05) 2204℃ 1评论4喜欢
有时候我们在发送HTTP请求的时候会使用到POST方式,如果是传送普通的表单数据那将很方便,直接将参数到一个Key-value形式的Map中即可。但是如果我们需要传送的参数是Json格式的,会稍微有点麻烦,我们可以使用HttpClient类库提供的功能来实现这个需求。假设我们需要发送的数据是:[code lang="java"]{ "blog": "", w397090770 10年前 (2015-06-01) 84792℃ 0评论72喜欢
Elasticsearch 6.3 于前天正式发布,其中带来了很多新特性,详情请参见:https://www.elastic.co/blog/elasticsearch-6-3-0-released。这个版本最大的亮点莫过于内置支持 SQL 模块!我在早些时间就说过 Elasticsearch 将会内置支持 SQL,参见:ElasticSearch内置也将支持SQL特性。我们可以像操作 MySQL一样使用 Elasticsearch,这样我们就可以减少 DSL 的学习成本, w397090770 7年前 (2018-06-15) 8963℃ 3评论14喜欢
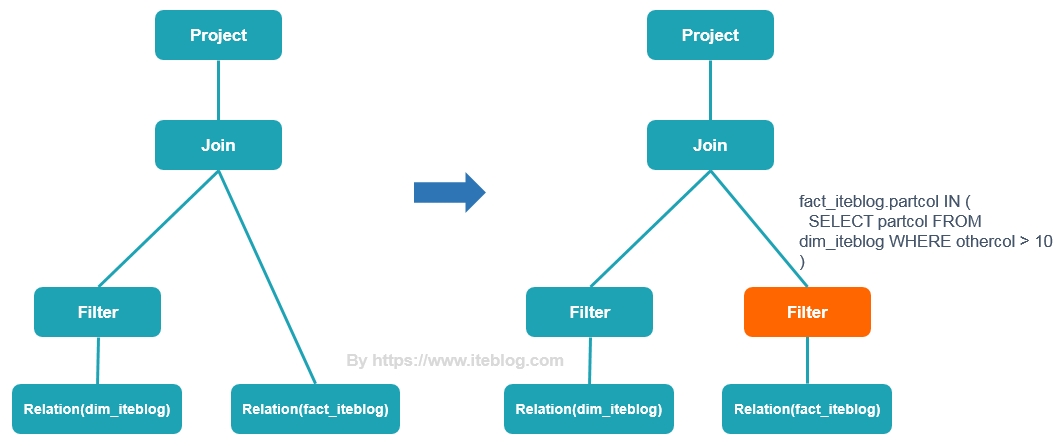
早在2005年,Oracle 数据库就支持比较丰富的 dynamic filtering 功能,而 Spark 和 Presto 在最近版本才开始支持这个功能。本文将介绍 Presto 动态过滤的原理以及具体使用。Apache Spark 的动态分区裁减Apache Spark 3.0 给我们带来了许多的新特性用于加速查询性能,其中一个就是动态分区裁减(Dynamic Partition Pruning,DPP),所谓的动态分区裁剪就 w397090770 3年前 (2021-06-01) 1407℃ 0评论2喜欢
PrestoDB 官方并没有提供 Docker 镜像,但是其为我们提供了制作 Docker 镜像的方法,步骤很简单。本文主要是用于学习交流,并为大家展示如何制作并运行简单的的 Docker 镜像,Dockerfile 的编写大量参考了 PrestoDB 的文档。因为这里仅仅是测试,所以仅留了 tpch connecter,大家可以根据自己需求去修改。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-11-19) 614℃ 0评论1喜欢
CarbonData是一种高性能大数据存储方案,支持快速过滤查找和即席OLAP分析,已在20+企业生产环境上部署应用,其中最大的单一集群数据规模达到几万亿。针对当前大数据领域分析场景需求各异而导致的存储冗余问题,业务驱动下的数据分析灵活性要求越来越高,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持多种应 w397090770 7年前 (2018-02-09) 1830℃ 0评论13喜欢
Apache Kafka 0.10.2.0正式发布,此版本供修复超过200个bugs,合并超过500个 PR。本版本添加了一下的新功能: 1、支持session windows,参见KAFKA-3452 2、提供ProcessorContext中低层次Metrics的访问,参见KAFKA-3537 3、不用配置文件的情况下支持为 Kafka clients JAAS配置,参见KAFKA-4259 4、为Kafka Streams提供全局Table支持,参见KAFKA-4490 w397090770 8年前 (2017-02-23) 2596℃ 0评论1喜欢
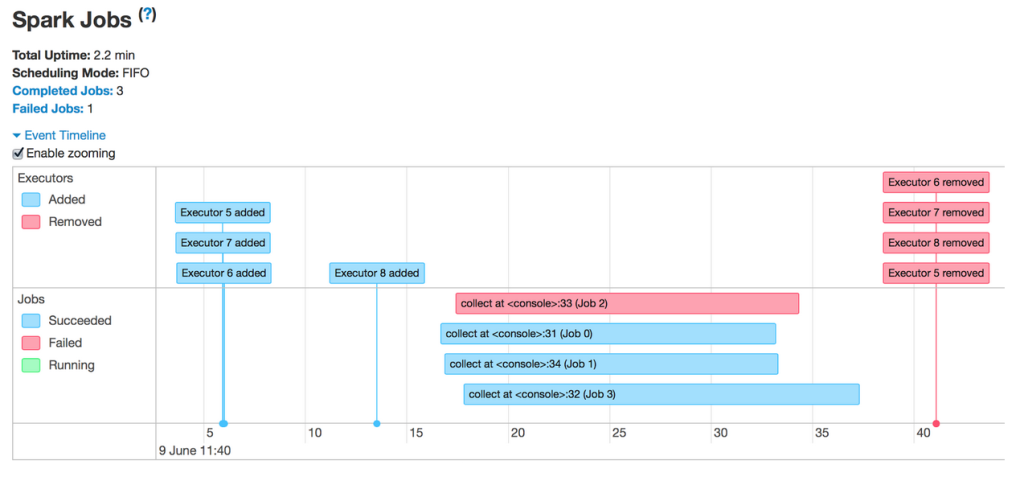
在过去,Spark UI一直是用户应用程序调试的帮手。而在最新版本的Spark 1.4中,我们很高兴地宣布,一个新的因素被注入到Spark UI——数据可视化。在此版本中,可视化带来的提升主要包括三个部分:Spark events时间轴视图Execution DAGSpark Streaming统计数字可视化我们会通过一个系列的两篇博文来介绍上述特性,本次则主要分享前 w397090770 9年前 (2015-07-08) 5976℃ 1评论13喜欢
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略(这两种分区的代码解析可以参见:《Spark分区器HashPartitioner和RangePartitioner代码详解》),这两种分区策略在很多情况下都适合我们的场景。但是有些情况下,Spark内部不能符合咱们的需求,这时候我们就可以自定义分区策略。为此,Spark提供了相应的接口,我们只 w397090770 10年前 (2015-05-21) 18428℃ 0评论20喜欢
io.file.buffer.size hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置缓存的大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以 w397090770 11年前 (2014-04-01) 30351℃ 2评论14喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。https://www.iteblog.com/archives/tag/hive-technology/ Hive最初是应Facebook每天 w397090770 11年前 (2013-12-18) 16853℃ 2评论31喜欢
本文来自 Data + AI Summit 2021 会议中 Facebook 的Rongrong Zhong(Facebook Presto 团队的 TL) 和 Tejas Patil(Facebook Spark 团队的 TL) 工程师带来的名为 《Portable UDFs : Write Once, Run Anywhere》的分享。 虽然大多数查询引擎都提供了丰富的内置函数,但它并不能满足用户的所有需求。在这种情况下,用户定义函数(UDF)允许用户表达他们的业 w397090770 3年前 (2021-12-17) 516℃ 0评论2喜欢
Raptor 是一个 Presto connector (presto-raptor),用于支持 Meta(以前的 Facebook)中的一些关键的交互式查询工作负载。尽管在 ICDE 2019 年的论文《Presto: SQL on Everything》中提到了这个特性,但对于许多 Presto 用户来说,它仍然有些神秘,因为没有关于这个特性的可用文档。本文将介绍 Raptor 的历史,以及为什么 Meta 最终取代了它,转而支持一种 w397090770 3年前 (2022-03-06) 404℃ 0评论1喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 9年前 (2015-08-31) 5482℃ 0评论6喜欢
作者:李闯 郭理想 背景 随着有赞实时计算业务场景全部以Flink SQL的方式接入,对有赞现有的引擎版本—Flink 1.10的SQL能力提出了越来越多无法满足的需求以及可以优化的功能点。目前有赞的Flink SQL是在Yarn上运行,但是在公司应用容器化的背景下,可以统一使用公司K8S资源池,同时考虑到任务之间的隔离性以及任务的弹性 w397090770 3年前 (2021-12-30) 1073℃ 0评论6喜欢
![Hadoop新手入门视频百度网盘下载[全十集]](https://www.iteblog.com/pic/iteblog.png)