今天在项目中用到了Scala正则表达式,网上找了好久也没找到很全的资料,这里收集了Scala中很多常用的正则表达式使用方法。关于Scala正则表达式替换请参见:《Scala正则表达式替换》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> val regex="""([0-9]+) ([a-z]+)& w397090770 10年前 (2015-01-04) 24904℃ 0评论27喜欢
程序的问题:已知数组a[n],求数组b[n].要求:b[i]=a[0]*a[1]*……*a[n-1]/a[i],不能用除法。a.时间复杂度O(n),空间复杂度O(1)。 b.除了迭代器i,不允许使用任何其它变量(包括栈临时变量等)大家有什么解法?先不要看我下面的解法。希望大家讨论讨论一下,留个言,一起交流一下。下面给出我的解法一:[code lang="CPP"]#include <stdio. w397090770 12年前 (2013-04-03) 4262℃ 0评论3喜欢
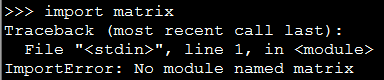
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& w397090770 7年前 (2017-06-25) 57128℃ 0评论14喜欢
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。 Apache Arrow主要有以下几点的优势: 1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流和允许SIMD(Single input multiple data) 优化的现代处理器上非常 w397090770 9年前 (2016-02-22) 6276℃ 0评论6喜欢
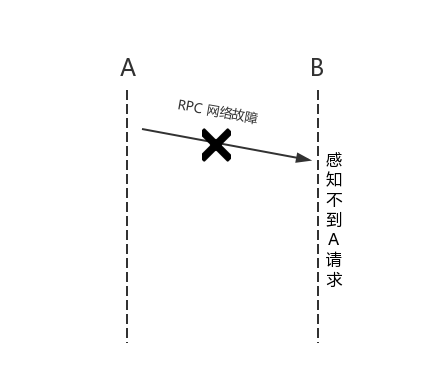
在传统的单机系统中,我们调用一个函数,这个函数要么返回成功,要么返回失败,其结果是确定的。可以概括为传统的单机系统调用只存在两态(2-state system):成功和失败。然而在分布式系统中,由于系统是分布在不同的机器上,系统之间的请求就相对于单机模式来说复杂度较高了。具体的,节点 A 上的系统通过 RPC (Remote Proc w397090770 7年前 (2018-04-20) 2526℃ 0评论9喜欢
面试题目:输入n个整数,输出其中最小的前k个数。 例如输入1,2,3,4,5,6,7和8这8个数字,则最小的3个数字为1,2,3。 分析:这道题最简单的思路莫过于把输入的n个整数排好序,然后输出前面k个数,这就是最小的前k个数。但是按照这种思路最好的时间复杂度为O(nlogn),是否还有比这个更快的算法呢? w397090770 12年前 (2013-05-21) 5645℃ 0评论2喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 5年前 (2019-06-14) 945℃ 0评论1喜欢
在数据量日益增长的当下,传统数据库的查询性能已满足不了我们的业务需求。而Clickhouse在OLAP领域的快速崛起引起了我们的注意,于是我们引入Clickhouse并不断优化系统性能,提供高可用集群环境。本文主要讲述如何通过Clickhouse结合大数据生态来定制一套完善的数据分析方案、如何打造完备的运维管理平台以降低维护成本,并结合具 w397090770 4年前 (2021-01-22) 1851℃ 0评论2喜欢
前提条件: 1、安装好jdk1.6或以上版本 2、部署好Hadoop 2.2.0(可以参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》) 3、安装好ant,这很简单:[code lang="JAVA"]$ wget http://mirrors.cnnic.cn/apache/ant/binaries/apache-ant-1.9.3-bin.tar.gz$ tar -zxvf apache-ant-1.9.3-bin.tar.gz[/code]然后设置好ANT_HOME和PATH就行 4、安装好相 w397090770 11年前 (2014-03-26) 23814℃ 1评论35喜欢
由于项目需要,需要在集群中安装好Zookeeper,这里我选择最新版本的Zookeeper3.4.5。 ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统 w397090770 11年前 (2014-01-20) 9474℃ 6评论8喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 w397090770 8年前 (2017-03-13) 16872℃ 9评论15喜欢
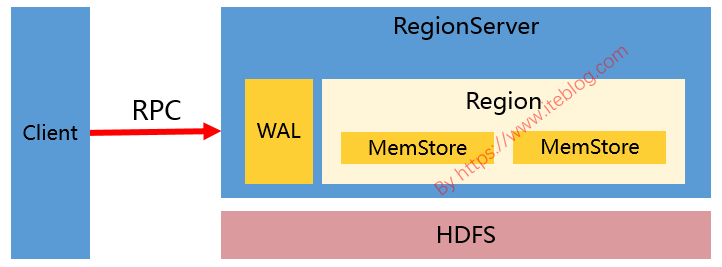
接触过 HBase 的同学应该对 HBase 写数据的过程比较熟悉(不熟悉也没关系)。HBase 写数据(比如 put、delete)的时候,都是写 WAL(假设 WAL 没有被关闭) ,然后将数据写到一个称为 MemStore 的内存结构里面的,如下图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是,MemStore 毕竟是内存里 w397090770 6年前 (2019-01-13) 7419℃ 4评论32喜欢
在过去三年中,来自Meta、Ahana(现为IBM)、Intel和字节跳动的工程师团队联手打造了一款名为Velox的先进执行引擎,它的设计目标是可以在各种计算引擎之间灵活组合使用。在这个过程中,他们开发出了基于C++的Presto worker,这是一个全新的查询执行引擎,它基于Velox构建,此前被称为Project Prestissimo,现在则被命名为Presto 2.0。我们 w397090770 5个月前 (06-27) 275℃ 0评论2喜欢
Elasticsearch最少需要Java 7版本,在本文写作时,推荐使用Oracle JDK 1.8.0_73版本。Java的安装和平台有关,所以本文并不打算介绍如何在各个平台上安装Java。在你安装ElasticSearch之前,先运行以下的命令检查你Java的版本:[code lang="java"]java -versionecho $JAVA_HOME[/code] 一旦我们将 Java 安装完成, 我们就可以下载并安装 Elasticsearch w397090770 8年前 (2016-08-29) 1533℃ 0评论1喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1386℃ 0评论1喜欢
4月16日在http://mirror.bit.edu.cn/apache/hive/hive-0.13.0/网址就可以下载Hive 0.13,这个版本在Hive执行速度、扩展性、SQL以及其他方面做了相当多的修改:一、执行速度 用户可以选择基于Tez的查询,基于Tez的查询可以大大提高Hive的查询速度(官网上上可以提升100倍)。下面一些技术对查询速度的提升: (1)、Broadcast Joins:和M w397090770 11年前 (2014-04-25) 8330℃ 1评论1喜欢
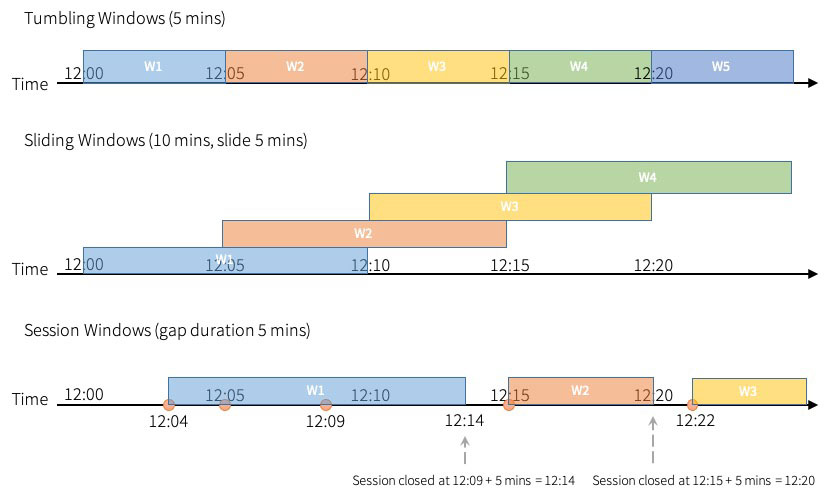
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had w397090770 3年前 (2021-10-21) 862℃ 0评论0喜欢
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 5年前 (2020-05-30) 1743℃ 0评论4喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-06) 5319℃ 0评论7喜欢
公安行业存在数以万计的前后端设备,前端设备包括相机、检测器及感应器,后端设备包括各级中心机房中的服务器、应用服务器、网络设备及机房动力系统,数量巨大、种类繁多的设备给公安内部运维管理带来了巨大挑战。传统通过ICMP/SNMP、Trap/Syslog等工具对设备进行诊断分析的方式已不能满足实际要求,由于公安内部运维管 w397090770 8年前 (2017-01-01) 11278℃ 1评论39喜欢
为期五天的 Spark Summit North America 2020在美国时间 2020-06-22 ~ 06-26 举行。由于今年新冠肺炎的影响,本次会议第一次以线上的形式进行。这次会议虽然是五天,但是前两天是培训,后面三天才是正式会议。本次会议一共有超过210个议题,一如既往,主题也主要是 Spark + AI,在 AI 方面会议还深入讨论一些流行的软件框架,如 Delta Lake、MLflo w397090770 4年前 (2020-07-04) 1878℃ 0评论2喜欢
最近在一个项目中使用到Play的Json相关的类库,看名字就知道这是和Json打交道的类库。其可以很方面地将class转换成Json字符串;也可以将Json字符串转换成一个类。一般的转换直接看Play的相关文档即可很容易的搞定,将class转换成Json字符串直接写个Writes即可;而将Json字符串转换成一个类直接写个Reads即可。所有的操作只需要引入 w397090770 8年前 (2016-08-27) 3258℃ 0评论14喜欢
CharSequenceReader类是以CharSequence的形式读取字符。CharSequenceReader类继承自Reader类,除了remaining()、hasRemaining()以及checkOpen()函数之后,其他的函数都是重写Reader类中的函数。CharSequenceReader类声明没有用public关键字,所以我们暂时还不能调用这个类CharSequenceReader类有下面三个成员变量[code lang="JAVA"] private CharSequence seq; //存放 w397090770 11年前 (2013-09-23) 2867℃ 1评论2喜欢
第十四次Shanghai Apache Spark Meetup聚会,由中国平安银行大力支持。活动将于2017年12月23日12:30~17:00在上海浦东新区上海海神诺富特酒店三楼麦哲伦厅举行。举办地点交通方便,靠近地铁4号线浦东大道站。座位有限,先到先得。大会主题《Spark在金融领域的算法实践》(13:20 – 14:05)演讲嘉宾:潘鹏举,平安银行大数据平台架构师 zz~~ 7年前 (2017-12-06) 2039℃ 0评论11喜欢
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 4年前 (2020-06-18) 1836℃ 0评论4喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 8月31日(13:30-17:30),杭州第 w397090770 10年前 (2014-09-01) 26634℃ 230评论17喜欢
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 w397090770 6年前 (2019-06-11) 12858℃ 2评论42喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 10年前 (2014-09-08) 18409℃ 177评论16喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14125℃ 30评论3喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3888℃ 0评论16喜欢








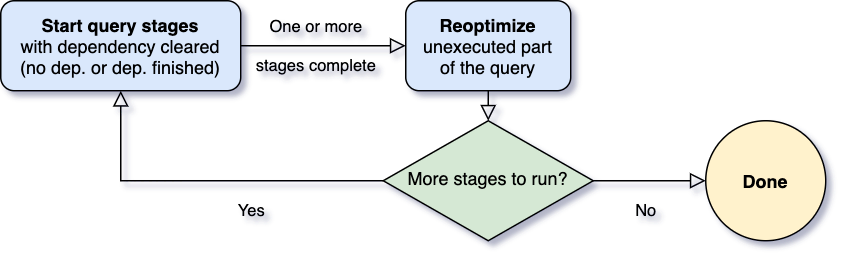

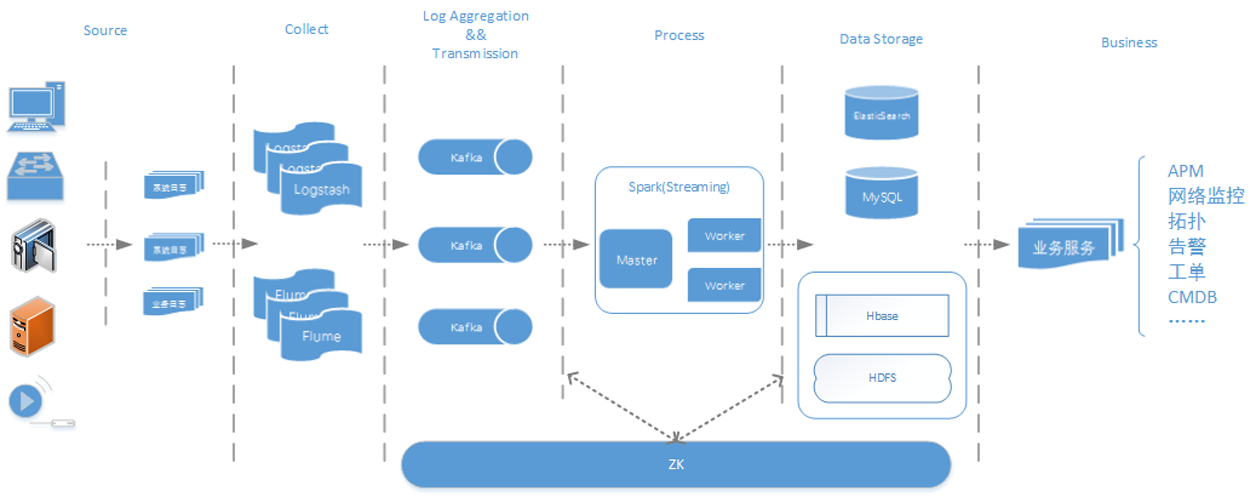

![Play JSON类库将List[(String, String)]转换成Json字符串](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/4.jpg)