本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13913℃ 0评论8喜欢
本书于2017-07由Packt Publishing出版,作者Christopher Bourez,全书440页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Get familiar with Theano and deep learningProvide examples in supervised, unsupervised, generative, or reinforcement learning.Discover the main principles for designing efficient deep learning nets: convolut zz~~ 7年前 (2017-08-23) 2384℃ 0评论8喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, w397090770 8年前 (2017-03-02) 10338℃ 0评论6喜欢
如果你使用Nginx web server,你可能在访问你网站的时候出现了504 Gateway Time-out错误,这个错误代码很常见,这可能是因为超过了PHP的最大执行时间的限制或者是FastCGI读超时。这篇文章将向大家展示如何解决Nginx的504 gateway timeout的问题。一、修改php.ini文件 下面都是以CentOS服务器为例进行介绍,如果你是CentOS,那么可以直 w397090770 9年前 (2015-08-18) 19826℃ 2评论16喜欢
每次当你在Yarn上以Cluster模式提交Spark应用程序的时候,通过日志我们总可以看到下面的信息:[code lang="java"]21 Oct 2014 14:23:22,006 INFO [main] (org.apache.spark.Logging$class.logInfo:59) - Uploading file:/home/spark-1.1.0-bin-2.2.0/lib/spark-assembly-1.1.0-hadoop2.2.0.jar to hdfs://my/user/iteblog/...../spark-assembly-1.1.0-hadoop2.2.0.jar21 Oct 2014 14:23:23,465 INFO [main] (org.ap w397090770 10年前 (2014-11-10) 10932℃ 2评论12喜欢
HDFS 快照是从 Hadoop 2.1.0-beta 版本开始引入的新功能,详见 HDFS-2802。概述HDFS 快照(HDFS Snapshots)是文件系统在某个时间点的只读副本。可以在文件系统的子树或整个文件系统上创建快照。快照的常见用途主要包括数据备份,防止用户误操作和容灾恢复。HDFS 快照的实现非常高效:快照的创建非常迅速:除去 inode 的查找时间, w397090770 6年前 (2018-12-02) 2158℃ 0评论3喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《Learning Spark》O'Reilly,2015-01 电子书下载:进入下载《Advanced Analytics with Spark》 O'Reilly,2015-04 电子书下载:进入下载如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《High Performance Spark》O'Reilly 2016-03 出 w397090770 8年前 (2017-02-12) 6741℃ 0评论18喜欢
前提条件:安装好相应版本的Hadoop(可以参见《在Fedora上部署Hadoop2.2.0伪分布式平台》)、安装好JDK1.6或以上版本(可以参见《如何在Linux平台命令行环境下安装Java1.6》) Hive的下载地址:http://archive.apache.org/dist/hive/,你可以选择你适合的版本去下载。本博客下载的Hive版本为0.8.0。你可以运行下面的命令去下载Hive,并解压:[ w397090770 11年前 (2013-11-01) 15357℃ 6评论3喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 8年前 (2017-06-02) 204℃ 0评论0喜欢
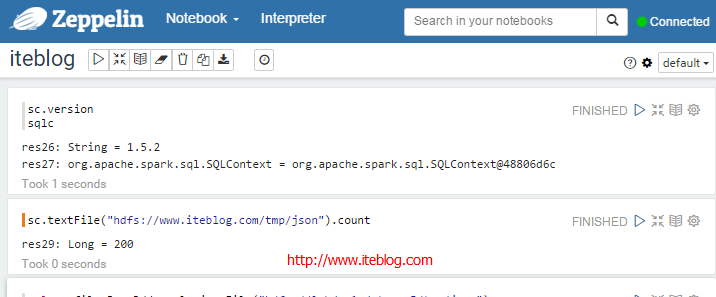
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖使用Apache Zeppelin 编译和启动完Zeppelin相关的进程之后,我们就可以来使用Zeppelin了。我们进入到https://www.iteblog.com:8080页面,我们可以在页面上直接操作Zeppelin,依次选择Notebook->Create new note,然后会弹出一个对话框 w397090770 9年前 (2016-02-03) 25292℃ 2评论31喜欢
代码生成是很多计算引擎中常用的执行优化技术,比如我们熟悉的 Apache Spark 和 Presto 在表达式等地方就使用到代码生成技术。这两个计算引擎虽然都用到了代码生成技术,但是实现方式完全不一样。在 Spark 中,代码生成其实就是在 SQL 运行的时候根据相关算子动态拼接 Java 代码,然后使用 Janino 来动态编译生成相关的 Java 字节码并 w397090770 3年前 (2021-09-28) 689℃ 0评论3喜欢
我们在使用Spark的时候有时候需要将一些数据分发到计算节点中。一种方法是将这些文件上传到HDFS上,然后计算节点从HDFS上获取这些数据。当然我们也可以使用addFile函数来分发这些文件。addFile addFile方法可以接收本地文件(或者HDFS上的文件),甚至是文件夹(如果是文件夹,必须是HDFS路径),然后Spark的Driver和Exector w397090770 8年前 (2016-07-11) 12640℃ 0评论13喜欢
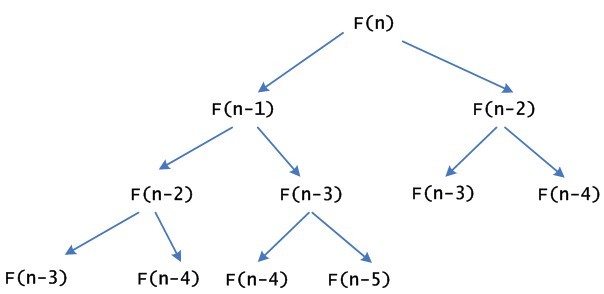
斐波那契数列又译费波拿契数、斐波那契数列、费氏数列、黄金分割数列。根据高德纳(Donald Ervin Knuth)的《计算机程序设计艺术》(The Art of Computer Programming),1150年印度数学家Gopala和金月在研究箱子包装物件长阔刚好为 1 和 2 的可行方法数目时,首先描述这个数列。 在西方,最先研究这个数列的人是比萨的列奥那多(又名费波 w397090770 12年前 (2013-04-16) 5914℃ 0评论6喜欢
在《Spark读取Hbase中的数据》文章中我介绍了如何在Spark中读取Hbase中的数据,并提供了Java和Scala两个版本的实现,本文将接着上文介绍如何通过Spark将计算好的数据存储到Hbase中。 Spark中内置提供了两个方法可以将数据写入到Hbase:(1)、saveAsHadoopDataset;(2)、saveAsNewAPIHadoopDataset,它们的官方介绍分别如下: saveAsHad w397090770 8年前 (2016-11-29) 17895℃ 1评论29喜欢
经过这段时间的整理以及格式调整,以及纠正其中的一些错误修改,整理出PDF下载。下载地址:[dl href="http://download.csdn.net/detail/w397090770/8337439" rel="nofollow"]CSDN免积分下载[/dl] 完整版可以到这里下载Learning Spark完整版下载附录:Learning Spark目录Chapter 1 Introduction to Data Analysis with Spark What Is Apache Spark? A Unified Stack Who Us w397090770 10年前 (2015-01-07) 32562℃ 6评论83喜欢
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopMMLSpark需要Scala 2.11,Spark 2 w397090770 7年前 (2017-10-24) 4222℃ 0评论9喜欢
在这篇文章中,我将介绍如何在Spark中使用Akka-http并结合Cassandra实现REST服务,在这个系统中Cassandra用于数据的存储。 我们已经见识到Spark的威力,如果和Cassandra正确地结合可以实现更强大的系统。我们先创建一个build.sbt文件,内容如下:[code lang="scala"]name := "cassandra-spark-akka-http-starter-kit"version := "1.0" w397090770 8年前 (2016-10-17) 3876℃ 1评论5喜欢
Lists类主要提供了对List类的子类构造以及操作的静态方法。在Lists类中支持构造ArrayList、LinkedList以及newCopyOnWriteArrayList对象的方法。其中提供了以下构造ArrayList的函数:下面四个构造一个ArrayList对象,但是不显式的给出申请空间的大小:[code lang="JAVA"] newArrayList() newArrayList(E... elements) newArrayList(Iterable<? w397090770 11年前 (2013-09-10) 19720℃ 2评论8喜欢
今天早上 06:53(2019年11月08日 06:53) 数砖的 Xingbo Jiang 大佬给社区发了一封邮件,宣布 Apache Spark 3.0 预览版正式发布,这个版本主要是为了对即将发布的 Apache Spark 3.0 版本进行大规模社区测试。无论是从 API 还是从功能上来说,这个预览版都不是一个稳定的版本,它的主要目的是为了让社区提前尝试 Apache Spark 3.0 的新特性。如果大家想 w397090770 5年前 (2019-11-08) 2071℃ 0评论6喜欢
1.文件大小默认为64M,改为128M有啥影响?2.RPC的原理?3.NameNode与SecondaryNameNode的区别与联系?4.介绍MadpReduce整个过程,比如把WordCount的例子的细节将清楚(重点讲解Shuffle)?5.MapReduce出现单点负载多大,怎么负载平衡?6.MapReduce怎么实现Top10?7.hadoop底层存储设计8.zookeeper有什么优点,用在什么场合9.Hbase中的meta w397090770 8年前 (2016-08-26) 3583℃ 0评论2喜欢
Spark 1.0.0于5月30日正式发布,可以到http://spark.apache.org/downloads.html页面下载。Spark 1.0.0是一个主要版本,它标志着Spark已经进入了1.X的时代。这个版本的Spark带来了很多新特性和强API的支持。 Spark 1.0加入了一个主要的组件: Spark SQL,这个组件支持在Spark上存储和操作结构化的数据。已有的标准库比如ML、Streaming和GraphX也得到了很大 w397090770 11年前 (2014-06-04) 5338℃ 1评论3喜欢
最近有个项目需要用到手机归属地信息,所有网上找到了一些免费的API。但是因为是免费的,所有很多都有限制,比如每天只能查询多少次等。本站提供的API地址: /api/mobile.php?mobile=13188888888参数:mobile ->手机号码(7位到11位)返回格式:JSON实例结果:[code lang="scala"]{ "ID": "18889", "prefix": &q w397090770 8年前 (2016-08-02) 8036℃ 4评论16喜欢
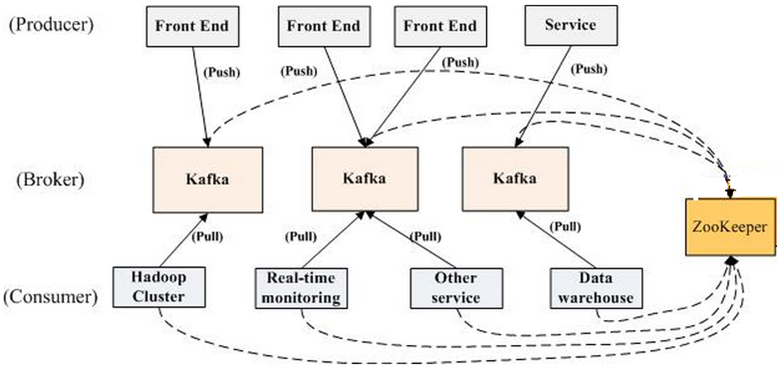
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源 w397090770 10年前 (2015-04-08) 7931℃ 2评论16喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23948℃ 1评论23喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 w397090770 3年前 (2021-10-19) 906℃ 0评论2喜欢
这几天在集群上部署了Shark 0.9.1,我下载的是已经编译好的,Hadoop版本是2.2.0,下面就总结一下我在安装Shark的过程中遇到的问题及其解决方案。一、YARN mode not available ?[code lang="JAVA"]Exception in thread "main" org.apache.spark.SparkException: YARN mode not available ? at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$createTaskScheduler(SparkContext. w397090770 11年前 (2014-05-05) 16065℃ 3评论4喜欢
在昨天我谈到了WSDL的一些概念,今天打算谈谈为什么理解WSDL非常重要。 许多用户可能会提到的一个问题是,既然WSDL文件可以在各种主要的平台上使用工具创建,为什么还要花时间学习WSDL呢?这是因为WSDL文档非常新,学习其内容和工作原理是明智的。由于Web服务正在变得无所不在,所以,理解和掌握WSDL文档的必要性越来 w397090770 12年前 (2013-04-25) 3119℃ 1评论2喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-05-15) 4818℃ 0评论3喜欢
今天在项目中用到了Scala正则表达式,网上找了好久也没找到很全的资料,这里收集了Scala中很多常用的正则表达式使用方法。关于Scala正则表达式替换请参见:《Scala正则表达式替换》如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> val regex="""([0-9]+) ([a-z]+)& w397090770 10年前 (2015-01-04) 24904℃ 0评论27喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14125℃ 30评论3喜欢
![[电子书]Deep Learning with Theano PDF下载](https://www.iteblog.com/pic/books/Deep_Learning_with_Theano_iteblog.png)