有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 w397090770 6年前 (2019-03-20) 8287℃ 5评论29喜欢
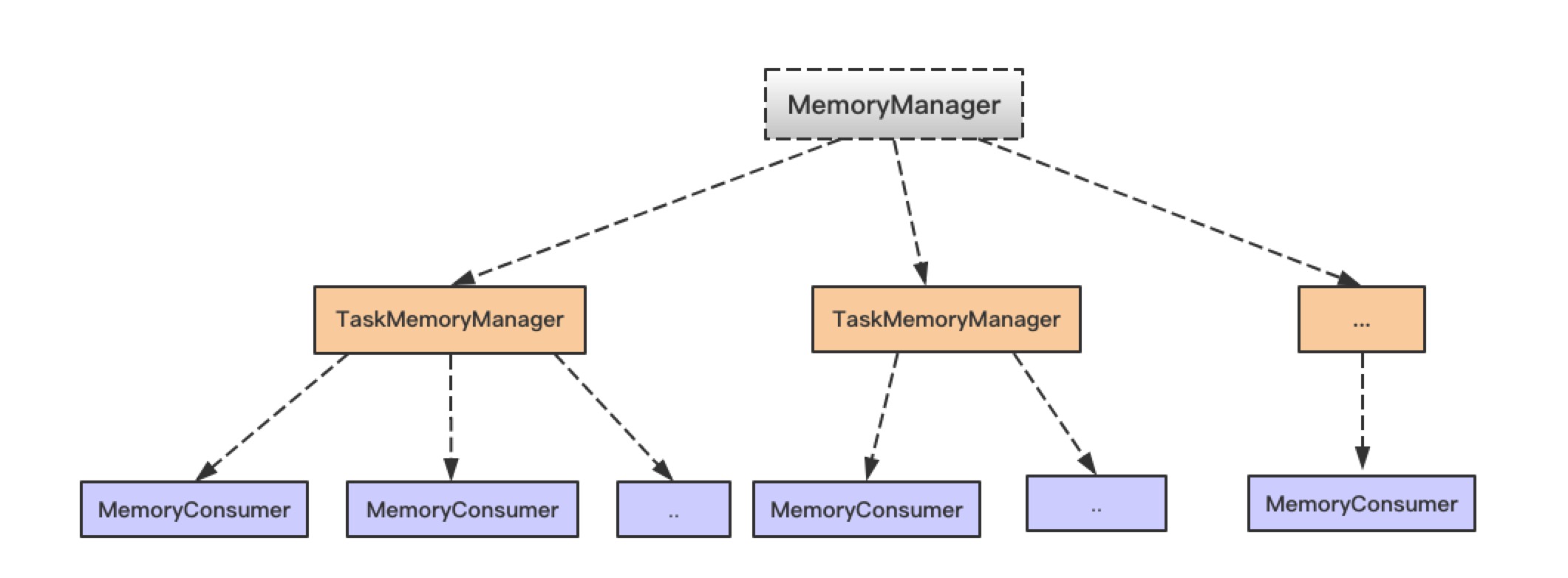
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM w397090770 6年前 (2019-03-17) 5389℃ 0评论19喜欢
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自 Databricks、NVIDIA、Google 以及阿里巴巴的工程师们正在为 Apache Spark 添加 w397090770 6年前 (2019-03-10) 6478℃ 0评论9喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3904℃ 0评论16喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 w397090770 6年前 (2019-02-20) 3229℃ 0评论8喜欢
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 6年前 (2019-02-16) 24269℃ 1评论46喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8225℃ 0评论12喜欢
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 6年前 (2019-01-14) 4271℃ 0评论18喜欢
随着图像分类(image classification)和对象检测(object detection)的深度学习框架的最新进展,开发者对 Apache Spark 中标准图像处理的需求变得越来越大。图像处理和预处理有其特定的挑战 - 比如,图像有不同的格式(例如,jpeg,png等),大小和颜色,并且没有简单的方法来测试正确性。图像数据源通过给我们提供可以编码的标准表 w397090770 6年前 (2018-12-13) 2475℃ 0评论4喜欢
Apache Avro 是一种流行的数据序列化格式。它广泛用于 Apache Spark 和 Apache Hadoop 生态系统,尤其适用于基于 Kafka 的数据管道。从 Apache Spark 2.4 版本开始,Spark 为读取和写入 Avro 数据提供内置支持。新的内置 spark-avro 模块最初来自 Databricks 的开源项目Avro Data Source for Apache Spark。除此之外,它还提供以下功能:新函数 from_avro() 和 to_avro() w397090770 6年前 (2018-12-11) 3179℃ 0评论9喜欢