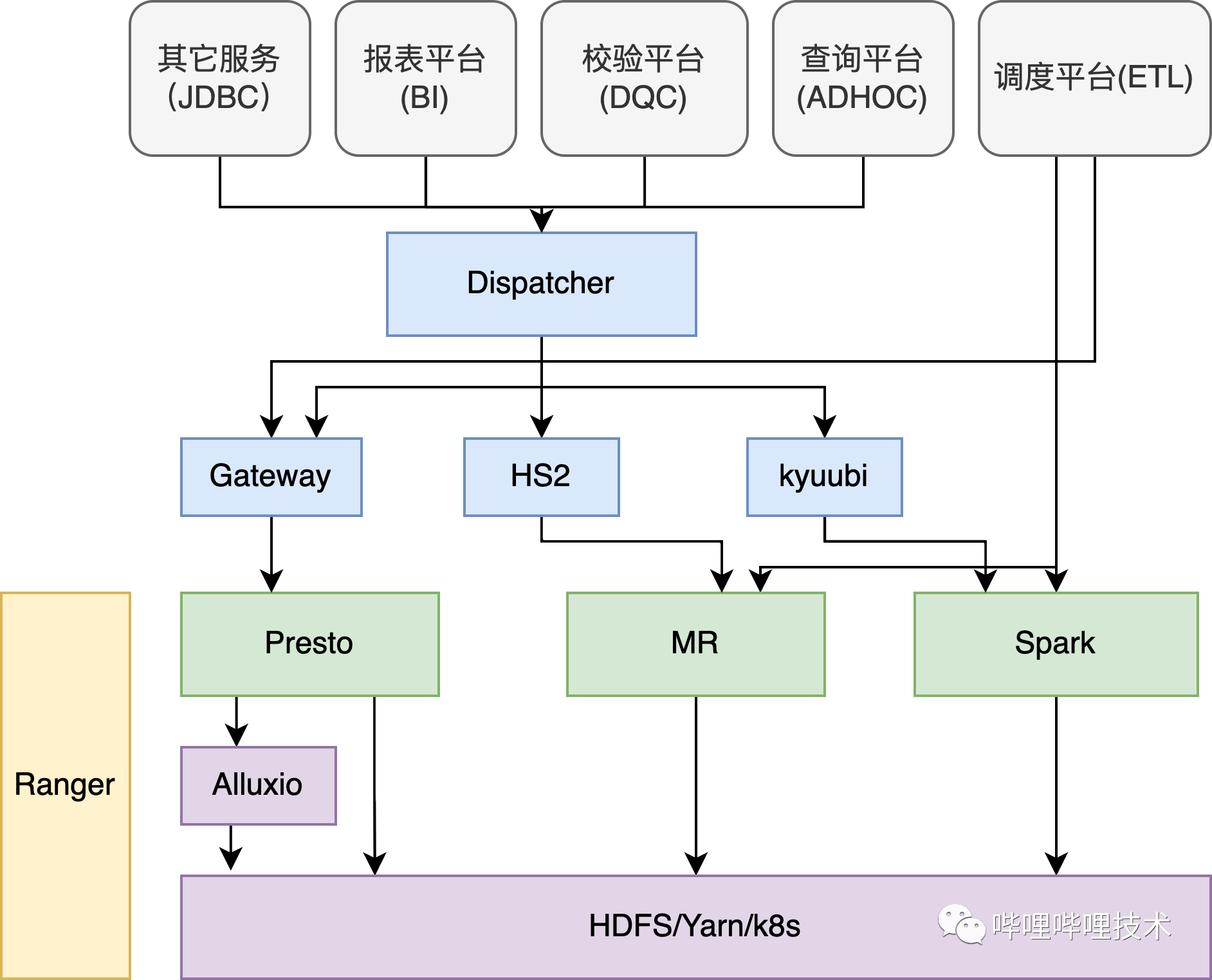
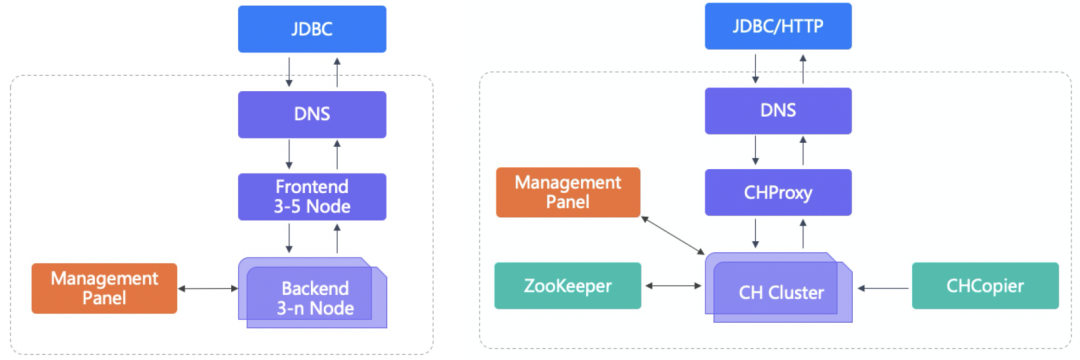
数据接入层提供了数据导入相关的服务及功能,按照数据的量级和特性我们抽象出三种Clickhouse导入数据的方式。
方式一:数仓应用层小表导入 方式二:离线多维明细宽表导入 方式三:实时多维明细宽表导入 数据存储层 数据存储层这里我们采用双副本机制来保证数据的高可靠,同时用nginx代理clickhouse集群,通过域名的方式进行读写操作,实现了数据均衡及高可靠写入,且对于域名的响应时间及流量有对应的实时监控,一旦响应速度出现波动或异常我们能在第一时间收到报警通知。
nginx_one_replication:代理集群一半节点即一个完整副本,常用于写操作,在每次提交数据时由nginx均衡路由到对应的shard表,当某一个节点出现异常导致写入失败时,nginx会暂时剔除异常节点并报警,然后另选一台节点重新写入。 nginx_two_replication:代理集群所有节点,一般用作查询和无副本表数据写入,同时也会有对于异常节点的剔除和报警机制。 数据服务层
对外:将集群查询统一封装为scf服务(RPC),供外部调用。 对内:提供了客户端工具直接供分析师及开发人员使用。 数据应用层
埋点系统:对接实时clickhouse集群,提供秒级别的OLAP查询功能。 用户分析平台:通过标签筛选的方式,从用户访问总集合中根据特定的用户行为捕获所需用户集。 BI:提供数据应用层的可视化展示,对接单分片多副本Clickhouse集群,可横向扩展。 Clickhouse运维管理平台 在Clickhouse的使用过程中我们对常见的运维操作如:增删节点、用户管理、版本升降级等封装了一系列的指令脚本,再结合业务同学使用过程中的一些诉求开发了Clickhouse管理平台,该平台集管理、运维、监控为一体,旨在让用户更方便、快捷的使用Clickhouse服务,降低运维成本,提高工作效率。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 配置文件结构 在自动化运维操作时会经常修改配置文件,而clickhouse大部分参数都是支持热修改的,为了降低修改配置的带来的风险和便于维护管理,我们将默认的配置文件做了如下拆解。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop
users.xml users.d/xxx.xml users_copy/xxx.xml metrika.xml conf.d/xxx.xml config_copy/xxx.xml 元数据管理 维护各个Clickhosue集群的元数据信息,包含表的元数据信息及Clickhouse服务状态信息,给用户更直观的元数据管理体验,主要有如下功能:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 自动化运维 用户管理 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 集群操作 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 这里以新增节点为例展示整体的流程操作:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 其中,较为核心的操作在于install作业的分发及对应的配置生成。分发install作业 :由Clickhouse平台调用运维作业平台服务将预定义的脚本分发到指定节点执行,同时传入用户选填的配置参数。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 生成配置文件 :通常情况下我们会在一个物理集群分别建立单副本集群和双副本集群,在为新节点生成配置文件时由clickhouse平台从元数据模块获取到新增节点的集群信息,动态生成新增节点的macros与metrika配置,然后将metrika.xml同步到所有集群。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 监控与报警 硬件指标监控 集群指标监控 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 流量指标监控 Clickhouse应用 BI查询引擎 核心诉求
(2) BI适配成本低;
(3)支持sql简单易用。
选型对比
功能点 Infobright TiDB Doris Clickhouse 百万级查询(100w)
84ms
24ms
25ms
41ms
千万级查询(1000w)
1330ms
332ms
130ms
71ms
亿级别查询(1.1亿)
57000ms
16151ms
3200ms
401ms
总体来看Clickhouse的查询性能略高于Doris,而TiDB在千万量级以上性能下降明显,且对于大数据量级下Clickhouse相比Infobright性能提升巨大,所以最终我们选择了Clikhouse作为BI的存储查询引擎。
集群构建 在评估了目前Infobright中的数据量级和Clickhouse的并发限制之后,我们决定使用单分片 多副本的方式来构建Clickhouse集群,理由如下:
BI对接数仓应用层数据,总体来说量级较小,同时clickhouse有着高效的数据压缩比,采用单节点能存储当前BI的全量数据,且能满足未来几年的数据存储需求。 Clickhouse默认并发数为100,采用单分片每个节点都拥有全量数据,当qps过高时可横向增加节点来增大并发数。 clickhouse对Distributed 表的join支持较差,单分片不走网络,能提高join查询速度。 服务器配置:CPU:16 × 2 cores、内存:192GB、磁盘:21TB,整体的架构图如下所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 在写数据时由taskplus对其中的一台节点写入,如果该节点异常可切换到其他副本节点写入,由写入副本自动同步其他副本。
tp99由1184ms变为739ms 大于1秒的查询总量日均减少4.5倍 大于1秒的查询总耗时日均降低6.5倍 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 问题及优化 在接入clickhouse之前BI的平均响应时间为187.93ms,接入clickhouse之后BI的平均响应时间为84.58ms,整体响应速度提升了2.2倍,虽然查询速度有所提升但是我们在clickhouse监控日报邮件中仍发现了一些慢查询,究其原因是我们对于应用层的表默认都是以日期字段stat_date分区,而有一部分表数据量级非常小且分区较多如某产品留存表总数据量:5564行,按日期分区 851个分区,平均每天6.5条数据,以下是针对于该表执行的常规group by count查询统计。
功能点 ck日期分区(冷查询) ck 日期分区(热查询) ck 无分区(热查询) Infobright 由此可见Clickhouse对于多分区的select的查询性能很差,官方文档中也有对应的表述:
A merge only works for data parts that have the same value for the partitioning expression. This means you shouldn’t make overly granular partitions (more than about a thousand partitions). Otherwise, the SELECT query performs poorly because of an unreasonably large number of files in the file system and open file descriptors
针对于这种场景我们想直接创建月或年维度的分区,但是对于增量数据会存在重跑历史等问题,而delete或ReplacingMergeTree都可能造成的数据查询不一致情况,基于此我们在mysql中做了一个中间表,每次增量导入或修改mysql表然后全量更新至clickhouse,不设置分区或不以日期为分区,保证查询的效率和一致性,经过多分区小量级表的优化之后我们的平均响应时间变为到70.66ms,相比未优化前查询性能提升了16%,最终BI的查询响应时间对比如下图所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 实时数仓 分层架构 由于每日用户行为数据量级已达百亿,传统的离线分析已不能满足业务方的需求,因此我们基于三端数据构建了实时数仓,整体分层架构如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop clickhouse在其中扮演的角色是秒级别的实时OLAP查询引擎,当我们DWS层的通用维度实时指标不满足用户需求时,用户可以直接通过Clickhouse编写sql查询实时数据,大大降低了实时数据查询门槛。
数据输入与输出 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 在数据输入层面我们将用户的行为数据实时关联维表写入kafka,然后由Flink + JDBC写入Clickhouse,为了保证实时查询的稳定性我们采用了双副本结构,用nginx代理其中一个完整的副本,直接对域名写入.同时在程序中增加失败重试机制,当有节点不可写入时,会尝试向其他分片写入,保证了每条数据都能被写入clickhouse。
在数据的输出层面将同样由nginx代理整个集群,对接到客户端工具及与SCF服务,其中客户端工具对接到开发人员及分析师,scf对外提供查询服务。
数据产品 埋点系统是我们专为埋点管理开发的系统其主要功能有:
埋点报备及校验:新上线埋点的收录及校验; 需求管理:针对于新埋点上线及埋点变更的需求周期监控及状态追踪; 埋点多维分析:基于用户上报埋点进行多维汇总,方便用户下钻分析定位问题; 指标及看板:有单个或多个埋点按一定规则组合进行多维汇总,可直接在看板中配置对应的统计结果数据; 埋点测试:实时收集测试埋点数并进行格式化校验及解析。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 在未接入Clickhouse前埋线系统采用MR预计算汇总用户配置的埋点指标,并将结果数据写入Hbase,预计算针对于用户侧来说查询的都是结果数据,响应速度非常快,但是同时也带来一些问题
时效性较差:新上报埋点数据或者修改后的埋点需要在T+1天才能展示,且修改埋点维度后需要重跑历史数据。
模型单一不便扩展:只针对埋点的事件模型做流量统计,想要支持其他分析模型必须另外开发对应的计算模型。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 基于此种情况我们直接将埋点系统中用户配置的规则转换为sql,查询Clickhouse中接入的实时多维明细数据,同时针对于埋点系统的使用场景优化了实时明细表的索引结构,依托clickhouse极致的查询性能保证实时埋点统计能在秒级别的响应,相当于即配即出,且能随意修改维度及指标,大大提升了用户体验.由于是基于sql直接统计明细数据,所以统计模型的扩展性较高,能更快的支持产品迭代。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:
iteblog_hadoop 常见问题 数据写入
一个batch内不要写多个分区的数据; 根据服务器配置适当增大background_pool_size,提高merge线程的数量 默认值16; 对于system.merges、system.processes表做好监控,可随时感知写入压力情况作出预警,避免服务崩溃; 索引不宜建立过多,对于大数据量高并发的写入可以考虑先做数据编排按建表索引排序在写入,减少merge压力; 禁止对Distributed表写入,可通过代理方式如nginx或chproxy直接对local表写入,而且能基于配置实现均衡写入及动态上下线节点。 JOIN操作
无论什么join小表必须放在右边,可以用left、right调整join方式; 开启谓词下推:enable_optimize_predicate_expression=1(部分版本默认关闭); 大量降低数据量的操作如where、group by、distinct操作优先在join之前做(需根据降低比例评估)。 常用参数
max_execution_time 单次查询的最大时间:600s; max_memory_usage 单服务器单次查询使用的最大内存,设置总体内存的50%; max_bytes_before_external_group_by 启动外部存储 max_memory_usage/2; max_memory_usage_for_all_queries 单服务器所有查询使用的最大内存,设置总体内存的80%-90%,防止因clickhouse服务占用过大资源导致服务器假死。 总结与展望 目前Clickhouse主要应用于数据产品、画像、BI等方向,日更新百亿数据,每日百万量级查询请求,持续对外提供高效的查询服务,我们未来将在以下两个方面加强Clickhouse的建设:
1.完善Clickhouse管理平台保障Clickhouse服务的稳定性: 2.优化Clickhouse性能,拓展Clickhouse使用场景: 参考文献:
Clickhouse官网 作者简介: 本文原文:Clickhouse的实践之路
本博客文章除特别声明,全部都是原创!过往记忆 )所有,未经许可不得转载。【Clickhouse 在58的实践之路】(https://www.iteblog.com/archives/9916.html) Learning and Operating Presto 预览版下载 又一个大数据相关项目成为顶级项目