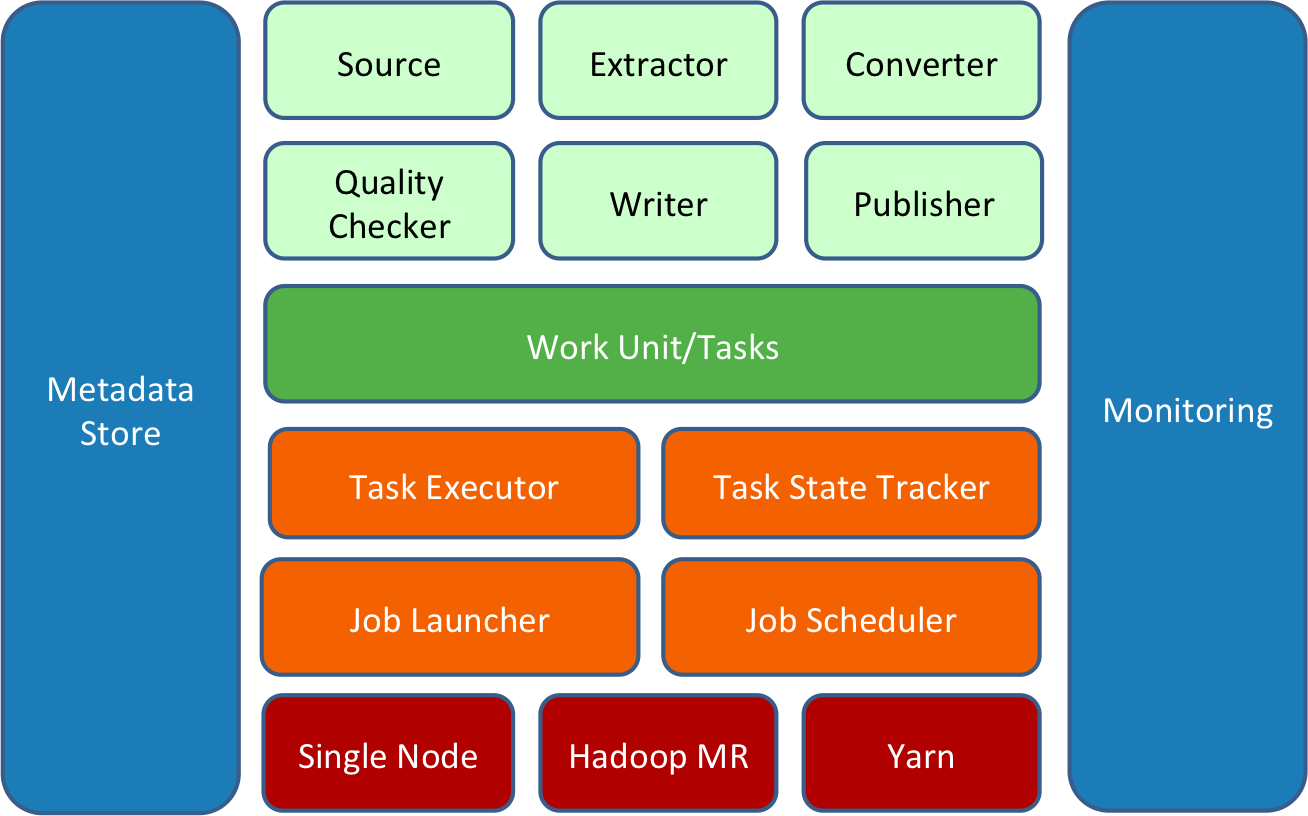
Gobblin 作业建立在一组 constructs 上(由上图中的浅绿色框表示),它们以某种方式协同工作并完成数据提取工作。所有的 constructs 都可以通过作业配置插入,并且可以通过添加新的或扩展现有的实现来扩展。
一个 Gobblin 作业由一组任务组成,每个任务对应一个要完成的工作单元,负责提取一部分数据。Gobblin 作业的任务由 Gobblin 运行时(Gobblin runtime)(由上图中的橙色框表示)根据选择的部署设置(由上图中的红色框表示)执行。
Gobblin 运行时(Gobblin runtime)负责在选择的部署设置上运行用户定义的 Gobblin 作业。它处理常见的任务,包括作业和任务调度、错误处理和任务重试、资源协商和管理、状态管理、数据质量检查、数据发布等。
Gobblin 目前支持两种部署模式:单节点的 Standalone 模式和 Hadoop 集群的 Hadoop MapReduce 模式。 当然,这部分还在扩展。
Gobblin 的运行和操作由一些组件和实用程序(由上图中的蓝色框表示)支持,它们处理重要的事情,例如元数据管理、状态管理、指标收集和报告以及监控。
关于 Apache® Gobblin™ 的更多介绍可以到 https://gobblin.apache.org/ 查看。
本博客文章除特别声明,全部都是原创!






