这一点不是很理解,因为shark是内存计算模型,所以hive中部分优化(索引)就没有必要支持。基于内存就不能在扫描全表之前先看索引文件来决定是否加载内存嘛?这是一点。还有就是spark sql已经到了2.4.4了都,现在支持hive部分优化。特指索引这个优化。因为orc压缩格式中的索引提升很大,spark sql不支持太可惜了。

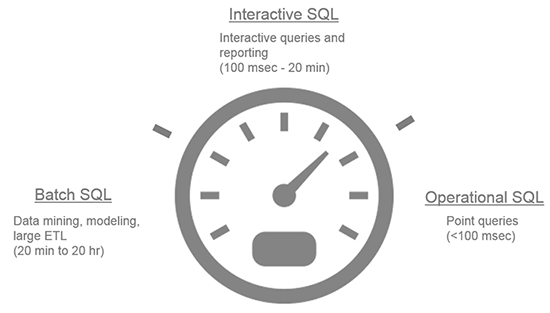



这一点不是很理解,因为shark是内存计算模型,所以hive中部分优化(索引)就没有必要支持。基于内存就不能在扫描全表之前先看索引文件来决定是否加载内存嘛?这是一点。还有就是spark sql已经到了2.4.4了都,现在支持hive部分优化。特指索引这个优化。因为orc压缩格式中的索引提升很大,spark sql不支持太可惜了。