最近在使用 Python 学习 Spark,使用了 jupyter notebook,期间使用到 hist 来绘图,代码很简单如下:[code lang="python"]user_data = sc.textFile("/home/iteblog/ml-100k/u.user")user_fields = user_data.map(lambda line: line.split("|"))ages = user_fields.map(lambda x: int(x[1])).collect()hist(ages, bins=20, color='lightblue', normed=True)fig = matplotlib.pyplot.gcf()fig.set_size_inch w397090770 7年前 (2017-12-04) 4676℃ 0评论19喜欢
使用 ElasticSearch 我们可以构建一个功能完备的搜索服务器。这一切实现起来都很简单,本文将花五分钟向你介绍如何实现。安装和运行Elasticsearch这篇文章的操作环境是 Linux 或者 Mac,在安装 ElasticSearch 之前,确保你的系统上已经安装好 JDK 6 或者以上版本。[code lang="bash"]wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearc w397090770 7年前 (2017-09-01) 3224℃ 0评论13喜欢
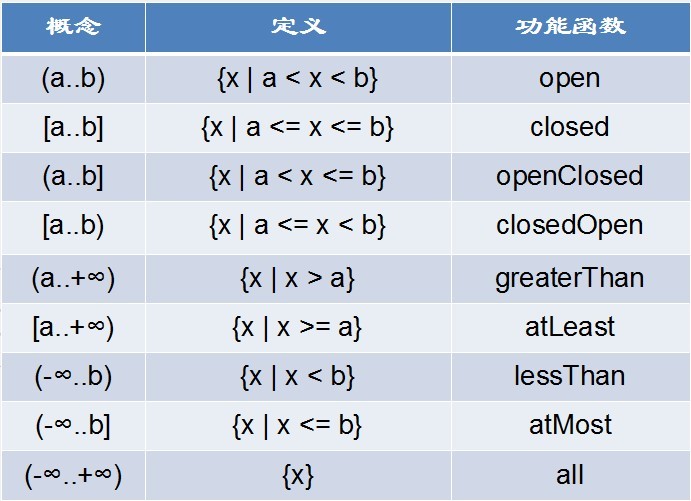
在Guava中新增了一个新的类型Range,从名字就可以了解到,这个是和区间有关的数据结构。从Google官方文档可以得到定义:Range定义了连续跨度的范围边界,这个连续跨度是一个可以比较的类型(Comparable type)。比如1到100之间的整型数据。不过我们无法遍历出这个区间里面的值。如果需要达到这个目的,我们可以将这个范围传给Conti w397090770 11年前 (2013-07-15) 5381℃ 0评论4喜欢
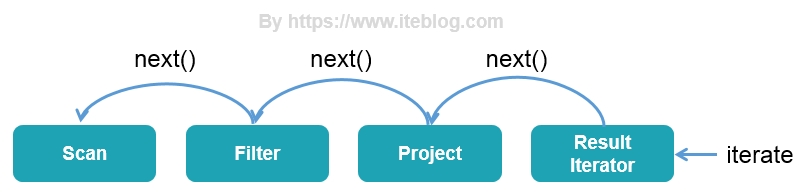
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。全阶段代码生成阶段 - WholeStageCodegen前面 w397090770 5年前 (2019-06-19) 9014℃ 0评论17喜欢
全新美国区 Apple ID 注册教程参见:2021年最新美区 Apple ID 注册教程使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple ID 账号,但是很多人手上一般都是只有国内的账号,这篇文章就来教大家如何把一个中国区的 w397090770 3年前 (2021-10-10) 1550℃ 0评论2喜欢
一. 问答题1. 简单说说map端和reduce端溢写的细节2. hive的物理模型跟传统数据库有什么不同3. 描述一下hadoop机架感知4. 对于mahout,如何进行推荐、分类、聚类的代码二次开发分别实现那些接口5. 直接将时间戳作为行健,在写入单个region 时候会发生热点问题,为什么呢?二. 计算题1. 比方:如今有10个文件夹, 每个 w397090770 8年前 (2016-08-26) 3152℃ 0评论1喜欢
首先非常感谢大家访问支持本博客,但是由于这些天访问人数的增加导致同一时刻访问本博客的人也增加,从而超过本博客服务器限制的并发数(100),这样使得本博客经常出现以下信息Bad Request (Invalid Hostname) 由于资金有限,所以选择了价格比较便宜的服务器,所以无法保证本博客100%在线。所以如果博客出现了Bad Requ w397090770 10年前 (2014-11-13) 3766℃ 3评论3喜欢
2021年2月15日,Apache Flink 创建者、Ververica 公司(前身 DataArtisans)的联合创始人 Fabian Hueske 在 Twitter 宣布其已经从 Ververica 离职, 不过离职原因不得而知。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop另外,Ververica 公司原 COO Holger Temme 将接替 Kostas Tzoumas 成为新的 CEO。Kostas Tzoumas (原 CEO) w397090770 4年前 (2021-02-18) 1115℃ 0评论5喜欢
TPCH(商业智能计算测试) 是美国交易处理效能委员会(TPC,Transaction Processing Performance Council) 组织制定的用来模拟决策支持类应用的一个测试集。目前在学术界和工业界普遍采用它来评价决策支持技术方面应用的性能。这种商业测试可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义, w397090770 7年前 (2017-12-10) 607℃ 0评论1喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 554℃ 0评论4喜欢
本程序实际上是构建了一颗二叉排序树,程序最后输出构建数的中序遍历。代码实现:[code lang="CPP"]#include <stdio.h>#include <stdlib.h>// Author: 过往记忆// Email: wyphao.2007@163.com// Blog: typedef int DataType; typedef struct BTree{ DataType data; struct BTree *Tleft; struct BTree *Tright; }*BTree;BTree CreateTree(); BTree insert(BTree root, DataTy w397090770 12年前 (2013-04-04) 3081℃ 0评论1喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1038℃ 0评论1喜欢
SPARK SUMMIT 2015会议于美国时间2015年06月15日到2015年06月17日在San Francisco(旧金山)进行,目前PPT已经全部公布了,不过很遗憾的是这个网站被墙了,无法直接访问,本博客将这些PPT全部整理免费下载。由于源网站限制,一天只能只能下载20个PPT,所以我只能一天分享20篇。如果想获取全部的PPT,请关站本博客。会议主旨 T w397090770 9年前 (2015-07-09) 3400℃ 1评论3喜欢
为期三天的 Spark Summit 在美国时间 2018-06-04 ~ 06-06 于旧金山的 Moscone Center 举行,不少人已经注意到,今年的会议已经更名为 Spark+AI, 去年 12 月份时,Databricks 在他们的博客中就已经提到过,2018 年的会议将包括更多人工智能的内容,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark Summit 2018 吸引了全球近 200 w397090770 6年前 (2018-06-18) 3635℃ 0评论14喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 下面是Spark meetup(Beijing)第 w397090770 10年前 (2014-08-29) 24055℃ 204评论16喜欢
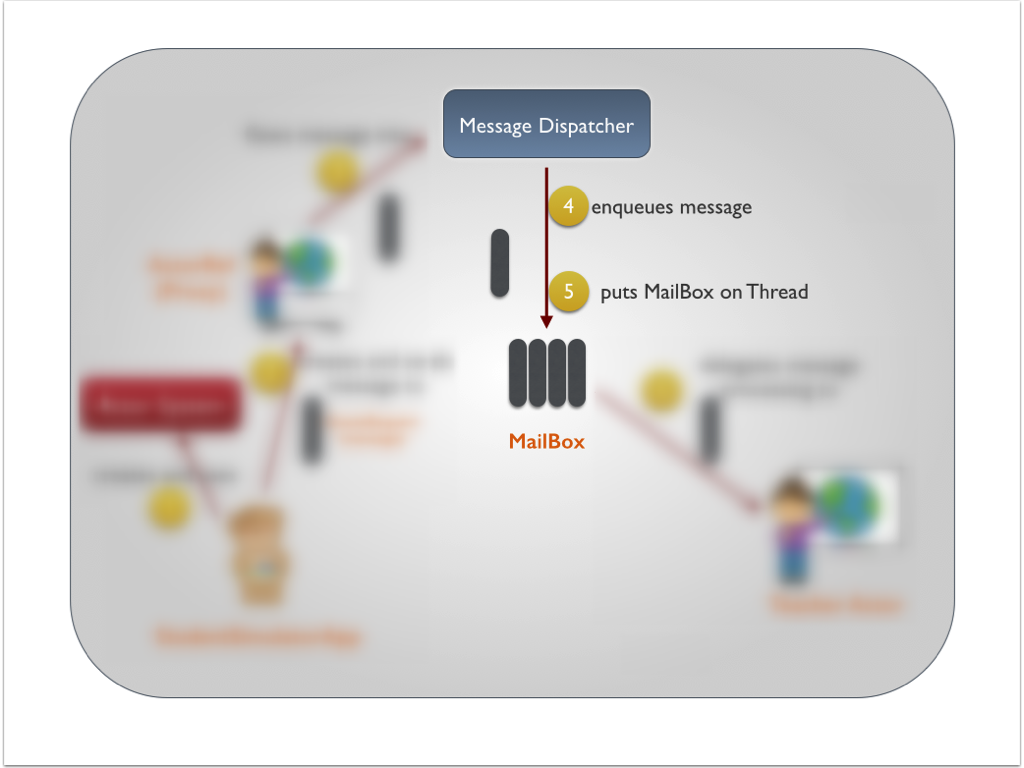
Akka学习笔记系列文章:《Akka学习笔记:ACTORS介绍》《Akka学习笔记:Actor消息传递(1)》《Akka学习笔记:Actor消息传递(2)》 《Akka学习笔记:日志》《Akka学习笔记:测试Actors》《Akka学习笔记:Actor消息处理-请求和响应(1) 》《Akka学习笔记:Actor消息处理-请求和响应(2) 》《Akka学习笔记:ActorSystem(配置)》《Akka学习笔记 w397090770 10年前 (2014-10-13) 15762℃ 2评论17喜欢
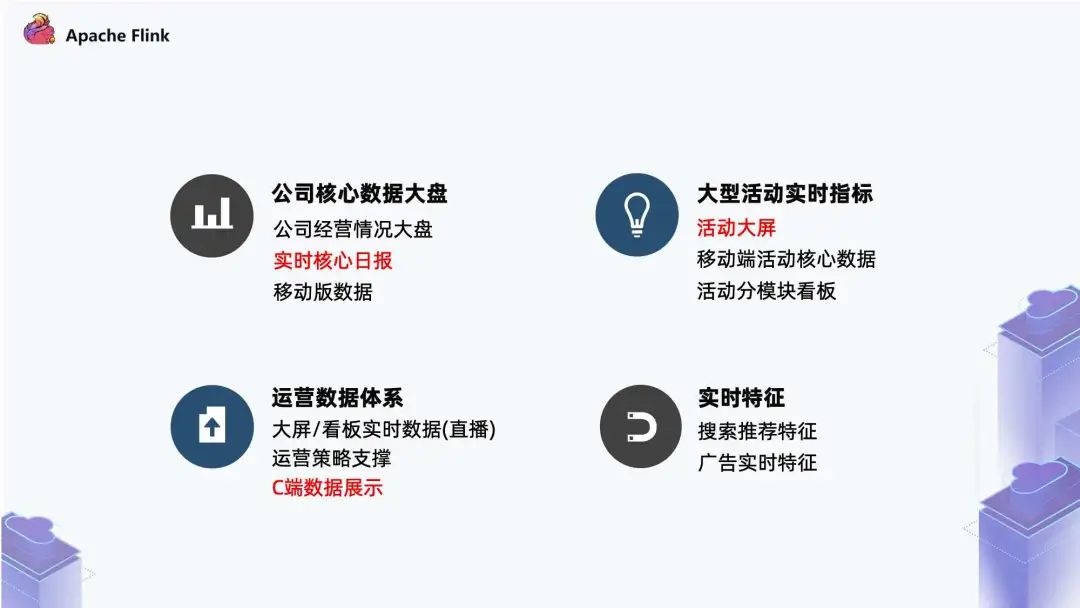
一、快手实时计算场景快手业务中的实时计算场景主要分为四块: 公司级别的核心数据:包括公司经营大盘,实时核心日报,以及移动版数据。相当于团队会有公司的大盘指标,以及各个业务线,比如视频相关、直播相关,都会有一个核心的实时看板; 大型活动实时指标:其中最核心的内容是实时大屏。例如快手的春晚 zz~~ 3年前 (2021-09-24) 786℃ 0评论5喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 10年前 (2015-05-20) 8130℃ 0评论7喜欢
一. 单选题1. 下面哪个程序负责 HDFS 数据存储a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker答案:C datanode2. HDfS 中的 block 默认保存几份?a)3 份 b)2 份 c)1 份d)不确定答案:A 默认3份 3. 下列哪个程序通常与 NameNode在一个节点启动?a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker答案:D分析:hadoop的集群是基于ma w397090770 8年前 (2016-08-26) 3707℃ 0评论2喜欢
一、定义位图法就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图法,引用bitset介绍:A bitset is a special container class that is designed to store bits (elements with only two possible values: 0 or 1,true or false, . w397090770 12年前 (2013-04-03) 8797℃ 0评论8喜欢
上海Spark Meetup第四次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 9年前 (2015-08-26) 2898℃ 0评论3喜欢
在今年的09月08日,Google在其安全博客中宣布:为了让用户更加方便了解他们与网站之间的连接是否安全,从2017年1月份正式发布的Chrome 56开始,Google将彻底把含有密码登录和交易支付等个人隐私敏感内容的HTTP页面标记为【不安全】,并且将会在后续更新的Chrome版本中,逐渐把所有的HTTP网站标记为【不安全】。HTTPS已成为网站的 w397090770 8年前 (2016-12-15) 3250℃ 0评论8喜欢
随着Spark项目的逐渐成熟, 越来越多的可配置参数被添加到Spark中来。在Spark中提供了三个地方用于配置:Spark properties:这个可以控制应用程序的绝大部分属性。并且可以通过 SparkConf 对象或者Java 系统属性进行设置;环境变量(Environment variables):这个可以分别对每台机器进行相应的设置,比如IP。这个可以在每台机器的 $SPARK_HOME/co w397090770 10年前 (2014-09-24) 57198℃ 1评论22喜欢
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。函数原型[code lang="scala"]def checkpoint()[/code]实例 w397090770 10年前 (2015-03-08) 60566℃ 0评论7喜欢
Apache Spark 2.2.0 经过了大半年的紧张开发,从RC1到RC6终于在今天正式发布了。由于时间的缘故,我并没有在《Apache Spark 2.2.0正式发布》文章中过多地介绍 Apache Spark 2.2.0 的新特性,本文作为补充将详细介绍Apache Spark 2.2.0 的新特性。这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(ex w397090770 7年前 (2017-07-12) 9318℃ 0评论28喜欢
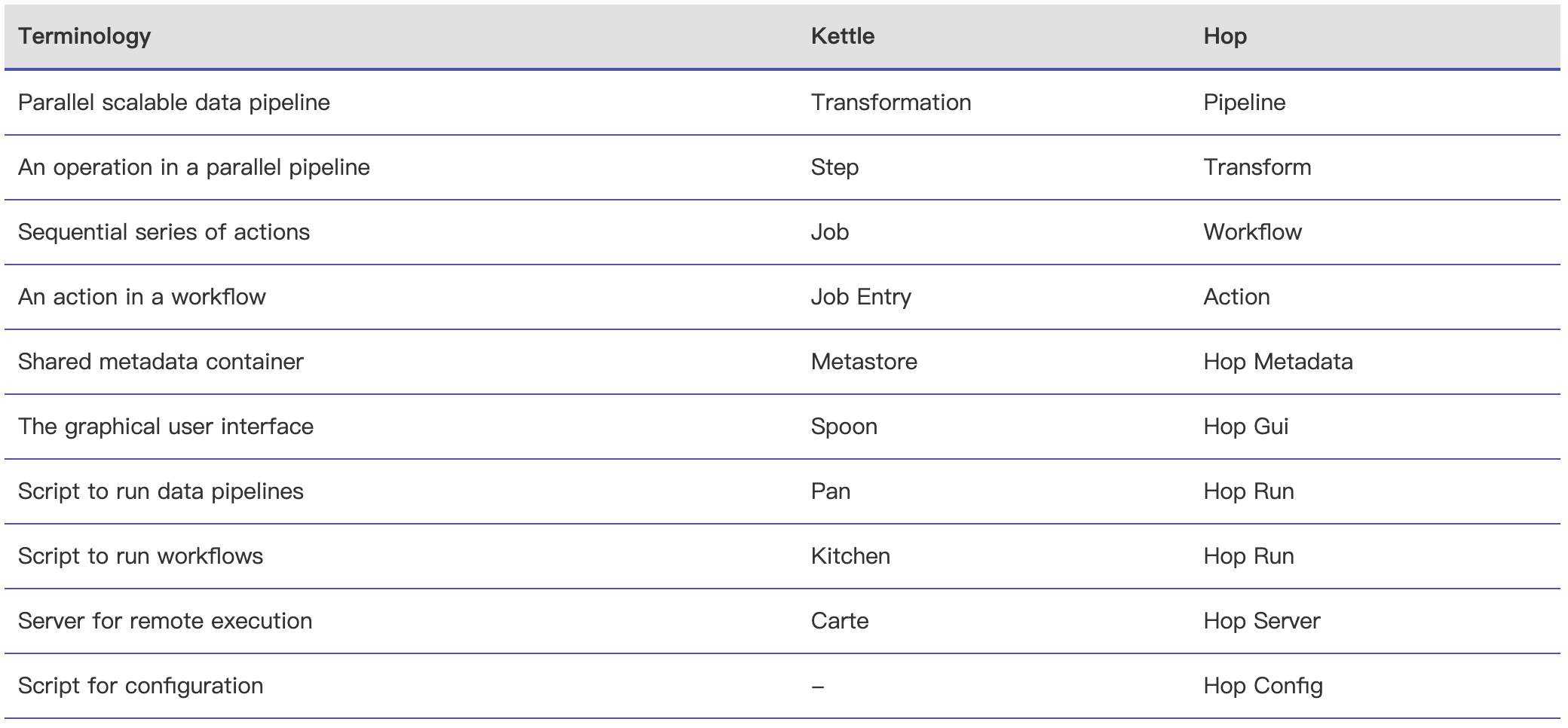
Apache Hop(Hop Orchestration Platform 的首字母缩写)是一种数据编排(data orchestration )和数据工程平台(data engineering platform),旨在促进数据和元数据编制。Hop 可以让我们专注于问题的解决,而不受技术的阻碍。该项目起源于 Kettle,经过数年的重构,并于2020年9月进入 Apache 孵化器;2022年1月18日正式成为 Apache 顶级项目。Hop 允许数据 w397090770 3年前 (2022-01-22) 1622℃ 0评论3喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!下面是 Shay Banon 修改 Elasticsearch 和 Kibana 开源协议的全文翻译。注:下面的我们是指 Elastic 公司(或 Shay Banon)我们正在将 ElasticSearch w397090770 4年前 (2021-01-17) 1188℃ 0评论4喜欢
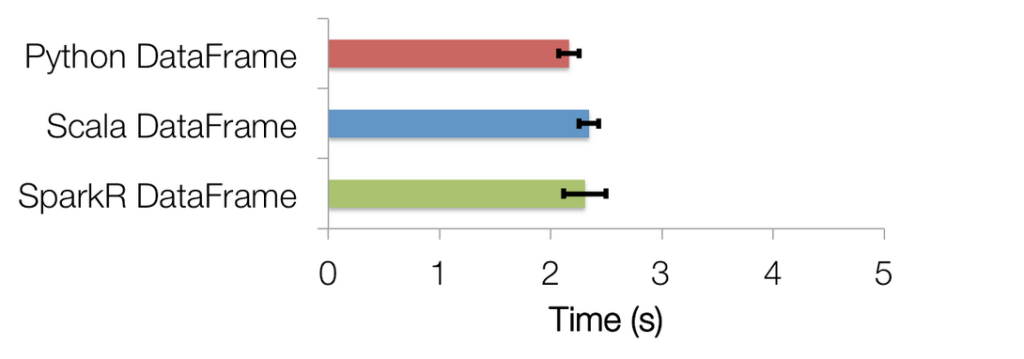
我(不是博主,这里的我指的是Shivaram Venkataraman)很高兴地宣布即将发布的Apache Spark 1.4 release将包含SparkR,它是一个R语言包,允许数据科学家通过R shell来分析大规模数据集以及交互式地运行Jobs。 R语言是一个非常流行的统计编程语言,并且支持很多扩展以便支持数据处理和机器学习任务。然而,R中交互式地数据分析常 w397090770 10年前 (2015-06-10) 8238℃ 0评论12喜欢
本博客收集的手机号段截止时间为2020年03月的,共计450000+条。包含以下字段:电信:133 153 173(新) 177 (新) 180 181 189 199 (新)移动:134 135 136 137 138 139 150 151 152 157 158 159 172(新) 178(新) 182 183 184 187 188 198(新) 联通:130 131 132 155 156 166(新) 175(新) 176(新) 185 186数据卡:145 147 149其他:170(新) 171 (新)API地址/api/mobile.php使用本AP w397090770 8年前 (2016-08-02) 5081℃ 0评论15喜欢
这里的方法貌似没有用,请参见本博客最新博文《CentOS 6.4安装谷歌浏览器(Chrome)》可以解决这个问题。 Google Chrome,又称Google浏览器,是一个由Google(谷歌)公司开发的开放原始码网页浏览器。如何在Cent OS里面安装Chrome呢?步骤如下: 第一步:打开终端,输入下面的命令[code lang="JAVA"]vim /etc/yum.repos.d/CentOS-Base.repo w397090770 11年前 (2013-08-07) 17740℃ 0评论5喜欢






![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)

![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png)