Apache Hudi : 未来发展
Apache Hudi 是如何处理小文件的
Apache Hudi 0.8.0 版本发布,Flink 集成有重大提升以及支持并行写
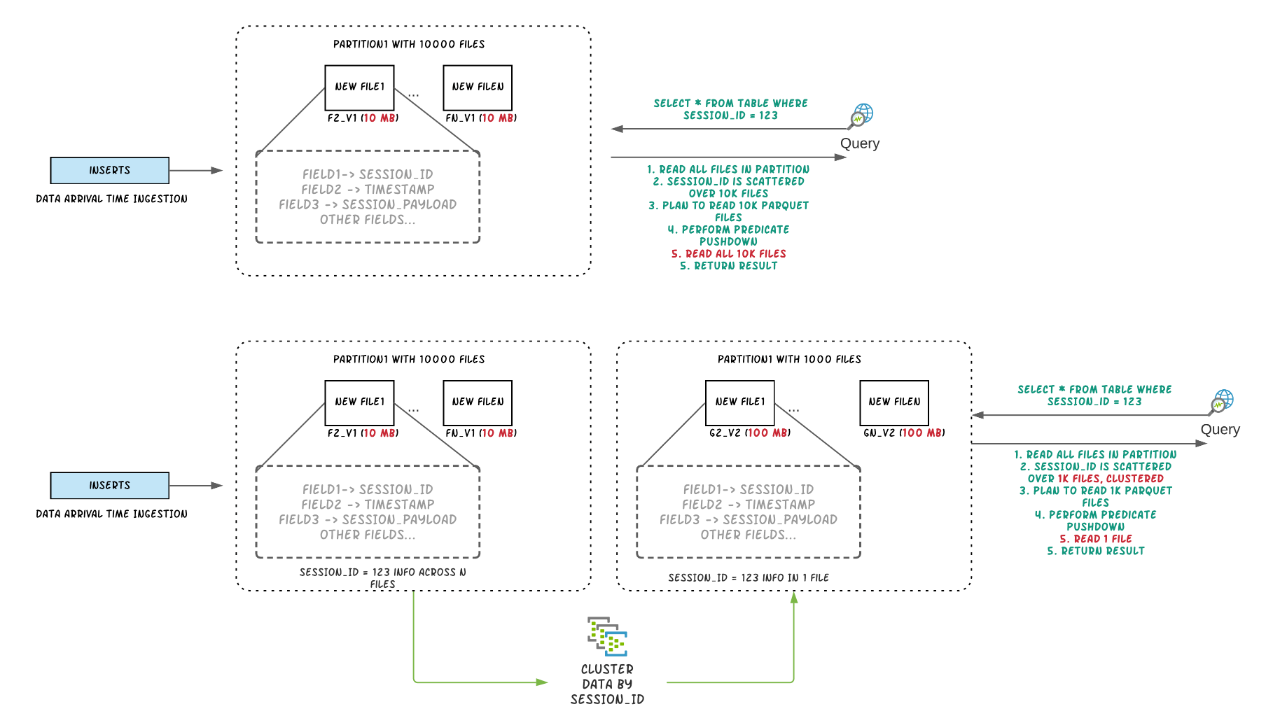
Apache Hudi Clustering 数据布局功能介绍
盘点2020年晋升为Apache TLP的大数据相关项目
Apache Hudi 现在也支持 Flink 引擎了
Apache Hudi 0.6.0 版本发布,新功能介绍
官宣,Apache Hudi 正式成为 Apache 顶级项目
下面文章您可能感兴趣
Hive常用语句
Apache Flink状态管理和容错机制介绍
[电子书]Machine Learning with Spark Second Edition PDF下载
IntelliJ IDEA 15激活码(破解)
Scala的Option monad和C#的null-conditional操作符比较
Zookeeper四字命令
SSDB:可用于替代Redis的高性能NoSQL数据库
ElasticSearch 6.0新特性介绍
Hadoop面试题系列(4/11)
一条 SQL 在 Apache Spark 之旅(上)
如何手动更新Kafka中某个Topic的偏移量
Apache Spark 1.3.0正式发布
使用Spark读写CSV格式文件
Linux库memcpy函数实现
[电子书]Machine Learning with Spark PDF下载
Kafka客户端是如何找到 leader 分区的
Spark insertIntoJDBC找不到Mysql驱动解决方法
Apache Spark 2.4.0 正式发布
Apache YARN各组件功能概述
Apache Hadoop 3.0.0-alpha1正式发布及其更新介绍
发表我的评论
取消评论
提交评论
有人回复时邮件通知我
表情
本博客评论系统带有自动识别垃圾评论功能,请写一些有意义的评论,谢谢!
有人回复时邮件通知我
使用微博登录
使用GitHub登录
使用QQ登录