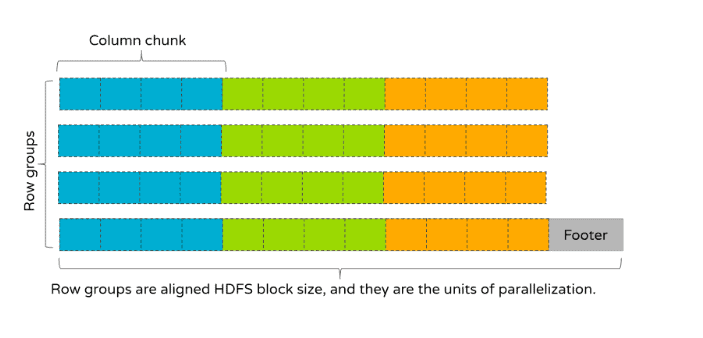
分析型SQL引擎(如Apache Impala)在进行大型表扫描和聚合查询工作负载时非常出色。在大数据生态系统中,单个表的大小可达PB(拍字节)级别,因此要实现快速的查询响应时间,就需要依据WHERE或HAVING子句中的条件对表数据进行智能过滤。通常会使用一个或多个列来对大型表进行分区,这些列能够有效地对数据进行范围过滤。例
分析型SQL引擎(如Apache Impala)在进行大型表扫描和聚合查询工作负载时非常出色。在大数据生态系统中,单个表的大小可达PB(拍字节)级别,因此要实现快速的查询响应时间,就需要依据WHERE或HAVING子句中的条件对表数据进行智能过滤。通常会使用一个或多个列来对大型表进行分区,这些列能够有效地对数据进行范围过滤。例 w397090770 9分钟前 2℃ 0评论0喜欢
自动类型推导是现代 C++ 中最重要且广泛使用的特性之一。新的 C++ 标准使得在各种上下文中可以使用 auto 作为类型的占位符,并让编译器推导出实际的类型。在 C++11 中,auto 可用于声明局部变量以及具有尾随返回类型的函数的返回类型。在 C++14 中,auto 可用于无需指定尾随类型的函数的返回类型以及 lambda 表达式中的参数声明。未 w397090770 2小时前 8℃ 0评论0喜欢
本文翻译自:《Magnet: Push-based Shuffle Service for Large-scale Data Processing》摘要在过去的十年中,Apache Spark 已成为大规模数据处理的流行计算引擎。与其他基于 MapReduce 计算范式的计算引擎一样,随机Shuffle操作(即中间数据的全部对全部传输)在 Spark 中起着重要作用。在 LinkedIn,随着数据量和 Spark 部署规模的快速增长,随机Shuffle操作正 w397090770 1周前 (01-06) 20℃ 0评论0喜欢
随着 Spark >= 3.3(在 3.4 中更加成熟)中引入的存储分区连接(Storage Partition Join,SPJ)优化技术,您可以在不触发 Shuffle 的情况下对分区的数据源 V2 表执行连接操作(当然,需要满足一些条件)。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:ob欧宝体育在线登录-ob欧宝娱乐app下载大数据Shuffle 是昂贵的,尤其是在 Spark 中的连 w397090770 1周前 (01-03) 60℃ 0评论0喜欢
本文原文来自:Databases in 2024: A Year in Review // Blog // Andy Pavlo - Carnegie Mellon University就像一颗子弹击中你的头顶,我回来了,要给你带来我关于数据库领域发生的事情的年度综述。是的,我曾经在OtterTune博客上写过这篇文章,但公司已经倒闭了(安息吧)。我现在在我的教授博客上发表这篇文章。过去的一年有很多值得关注的事情,从 w397090770 1周前 (01-03) 33℃ 0评论0喜欢
全局引用与弱全局引用在JNI编程中,管理对象引用的生命周期是非常重要的。JNI提供了几种不同类型的引用,以适应不同的使用场景。其中,全局引用(Global Reference)和弱全局引用(Weak Global Reference)是两种常用的引用类型。全局引用(Global Reference)全局引用是JNI中最强的引用类型。一旦一个Java对象被全局引用指向,它 w397090770 2周前 (12-31) 22℃ 0评论0喜欢
对象的创建与销毁在JNI中,创建和销毁Java对象是常见的操作。这涉及到使用JNIEnv指针提供的函数来实例化Java类并管理对象的生命周期。创建Java对象要创建一个Java对象,首先需要获取表示该对象类的 jclass ,然后使用 JNIEnv 的 NewObject 函数。 NewObject 函数需要三个参数:1. jclass:表示要实例化的Java类的类引用。2. jmetho w397090770 2周前 (12-31) 9℃ 0评论0喜欢
调用本地方法在JNI中,从Java代码调用本地方法是一个核心功能。这个过程涉及到Java端的声明、本地方法的实现,以及两者之间的连接。以下是如何在JNI中调用本地方法的详细步骤。在Java中声明本地方法首先,在Java类中声明本地方法。使用`native`关键字标记这些方法,但不需要提供方法体。这些方法的具体实现在本地代码 w397090770 2周前 (12-31) 17℃ 0评论0喜欢
基本数据类型映射在JNI中,Java的基本数据类型和C/C++的基本数据类型之间有一一对应的关系。这种映射关系是JNI能够实现Java与本地代码之间数据交换的基础。以下是Java基本数据类型与C/C++基本数据类型之间的映射:整数类型byte:在Java中,`byte`是有符号的8位整数。在C/C++中,它映射为`jbyte`,实际上就是一个`signed char`。shor w397090770 2周前 (12-31) 35℃ 0评论0喜欢
JNI 简介Java Native Interface(JNI)是Java平台的一个标准接口,它允许Java代码与其他语言编写的代码进行交互。这种交互能力极大地扩展了Java的应用范围,使得Java程序可以调用系统级的库或者执行高性能计算,这些往往是纯Java代码难以高效完成的。从Java 1.1版本开始,JNI标准就成为Java平台的一部分。JNI最初的设计目的是为了本地 w397090770 2周前 (12-31) 19℃ 0评论0喜欢